 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObstacle-aware Gaussian Process Regression
Dec 09, 2024Obstacle-aware trajectory navigation is crucial for many systems. For example, in real-world navigation tasks, an agent must avoid obstacles, such as furniture in a room, while planning a trajectory. Gaussian Process (GP) regression, in its current form, fits a curve to a set of data pairs, with each pair consisting of an input point 'x' and its corresponding target regression value 'y(x)' (a positive data pair). However, to account for obstacles, we need to constrain the GP to avoid a target regression value 'y(x-)' for an input point 'x-' (a negative data pair). Our proposed approach, 'GP-ND' (Gaussian Process with Negative Datapairs), fits the model to the positive data pairs while avoiding the negative ones. Specifically, we model the negative data pairs using small blobs of Gaussian distribution and maximize their KL divergence from the GP. Our framework jointly optimizes for both positive and negative data pairs. Our experiments show that GP-ND outperforms traditional GP learning. Additionally, our framework does not affect the scalability of Gaussian Process regression and helps the model converge faster as the data size increases.
Continuous Video Process: Modeling Videos as Continuous Multi-Dimensional Processes for Video Prediction
Dec 09, 2024



Diffusion models have made significant strides in image generation, mastering tasks such as unconditional image synthesis, text-image translation, and image-to-image conversions. However, their capability falls short in the realm of video prediction, mainly because they treat videos as a collection of independent images, relying on external constraints such as temporal attention mechanisms to enforce temporal coherence. In our paper, we introduce a novel model class, that treats video as a continuous multi-dimensional process rather than a series of discrete frames. We also report a reduction of 75\% sampling steps required to sample a new frame thus making our framework more efficient during the inference time. Through extensive experimentation, we establish state-of-the-art performance in video prediction, validated on benchmark datasets including KTH, BAIR, Human3.6M, and UCF101. Navigate to the project page https://www.cs.umd.edu/~gauravsh/cvp/supp/website.html for video results.
Video Decomposition Prior: A Methodology to Decompose Videos into Layers
Dec 09, 2024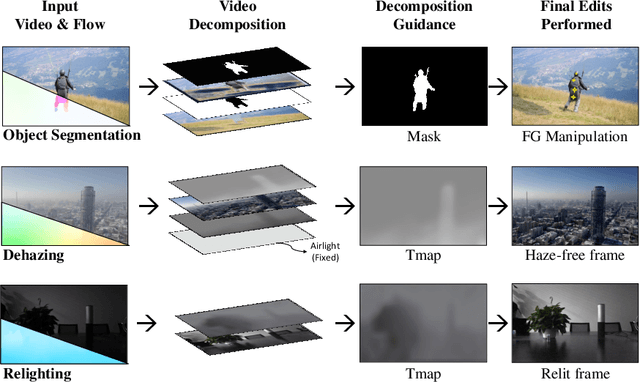

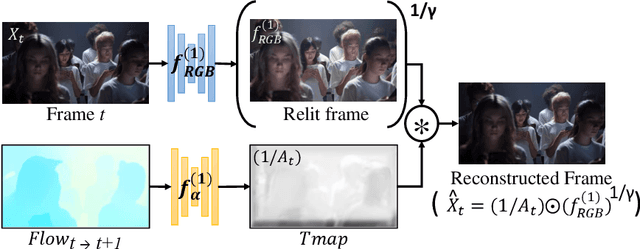

In the evolving landscape of video enhancement and editing methodologies, a majority of deep learning techniques often rely on extensive datasets of observed input and ground truth sequence pairs for optimal performance. Such reliance often falters when acquiring data becomes challenging, especially in tasks like video dehazing and relighting, where replicating identical motions and camera angles in both corrupted and ground truth sequences is complicated. Moreover, these conventional methodologies perform best when the test distribution closely mirrors the training distribution. Recognizing these challenges, this paper introduces a novel video decomposition prior `VDP' framework which derives inspiration from professional video editing practices. Our methodology does not mandate task-specific external data corpus collection, instead pivots to utilizing the motion and appearance of the input video. VDP framework decomposes a video sequence into a set of multiple RGB layers and associated opacity levels. These set of layers are then manipulated individually to obtain the desired results. We addresses tasks such as video object segmentation, dehazing, and relighting. Moreover, we introduce a novel logarithmic video decomposition formulation for video relighting tasks, setting a new benchmark over the existing methodologies. We observe the property of relighting emerge as we optimize for our novel relighting decomposition formulation. We evaluate our approach on standard video datasets like DAVIS, REVIDE, & SDSD and show qualitative results on a diverse array of internet videos. Project Page - https://www.cs.umd.edu/~gauravsh/video_decomposition/index.html for video results.
Efficient Continuous Video Flow Model for Video Prediction
Dec 07, 2024



Multi-step prediction models, such as diffusion and rectified flow models, have emerged as state-of-the-art solutions for generation tasks. However, these models exhibit higher latency in sampling new frames compared to single-step methods. This latency issue becomes a significant bottleneck when adapting such methods for video prediction tasks, given that a typical 60-second video comprises approximately 1.5K frames. In this paper, we propose a novel approach to modeling the multi-step process, aimed at alleviating latency constraints and facilitating the adaptation of such processes for video prediction tasks. Our approach not only reduces the number of sample steps required to predict the next frame but also minimizes computational demands by reducing the model size to one-third of the original size. We evaluate our method on standard video prediction datasets, including KTH, BAIR action robot, Human3.6M and UCF101, demonstrating its efficacy in achieving state-of-the-art performance on these benchmarks.
Video Dynamics Prior: An Internal Learning Approach for Robust Video Enhancements
Dec 13, 2023



In this paper, we present a novel robust framework for low-level vision tasks, including denoising, object removal, frame interpolation, and super-resolution, that does not require any external training data corpus. Our proposed approach directly learns the weights of neural modules by optimizing over the corrupted test sequence, leveraging the spatio-temporal coherence and internal statistics of videos. Furthermore, we introduce a novel spatial pyramid loss that leverages the property of spatio-temporal patch recurrence in a video across the different scales of the video. This loss enhances robustness to unstructured noise in both the spatial and temporal domains. This further results in our framework being highly robust to degradation in input frames and yields state-of-the-art results on downstream tasks such as denoising, object removal, and frame interpolation. To validate the effectiveness of our approach, we conduct qualitative and quantitative evaluations on standard video datasets such as DAVIS, UCF-101, and VIMEO90K-T.
Diverse Video Generation using a Gaussian Process Trigger
Jul 09, 2021

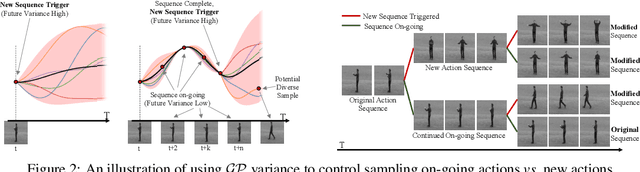

Generating future frames given a few context (or past) frames is a challenging task. It requires modeling the temporal coherence of videos and multi-modality in terms of diversity in the potential future states. Current variational approaches for video generation tend to marginalize over multi-modal future outcomes. Instead, we propose to explicitly model the multi-modality in the future outcomes and leverage it to sample diverse futures. Our approach, Diverse Video Generator, uses a Gaussian Process (GP) to learn priors on future states given the past and maintains a probability distribution over possible futures given a particular sample. In addition, we leverage the changes in this distribution over time to control the sampling of diverse future states by estimating the end of ongoing sequences. That is, we use the variance of GP over the output function space to trigger a change in an action sequence. We achieve state-of-the-art results on diverse future frame generation in terms of reconstruction quality and diversity of the generated sequences.