 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Video Generation using a Gaussian Process Trigger
Paper and Code
Jul 09, 2021

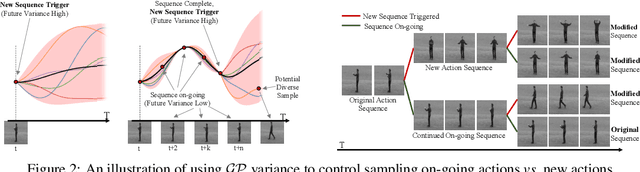

Generating future frames given a few context (or past) frames is a challenging task. It requires modeling the temporal coherence of videos and multi-modality in terms of diversity in the potential future states. Current variational approaches for video generation tend to marginalize over multi-modal future outcomes. Instead, we propose to explicitly model the multi-modality in the future outcomes and leverage it to sample diverse futures. Our approach, Diverse Video Generator, uses a Gaussian Process (GP) to learn priors on future states given the past and maintains a probability distribution over possible futures given a particular sample. In addition, we leverage the changes in this distribution over time to control the sampling of diverse future states by estimating the end of ongoing sequences. That is, we use the variance of GP over the output function space to trigger a change in an action sequence. We achieve state-of-the-art results on diverse future frame generation in terms of reconstruction quality and diversity of the generated sequences.