 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCESMA: Centralized Expert Supervises Multi-Agents
Feb 07, 2019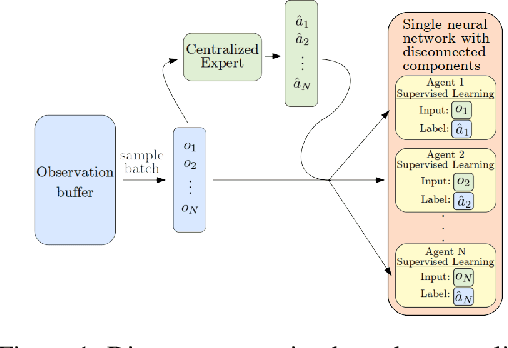
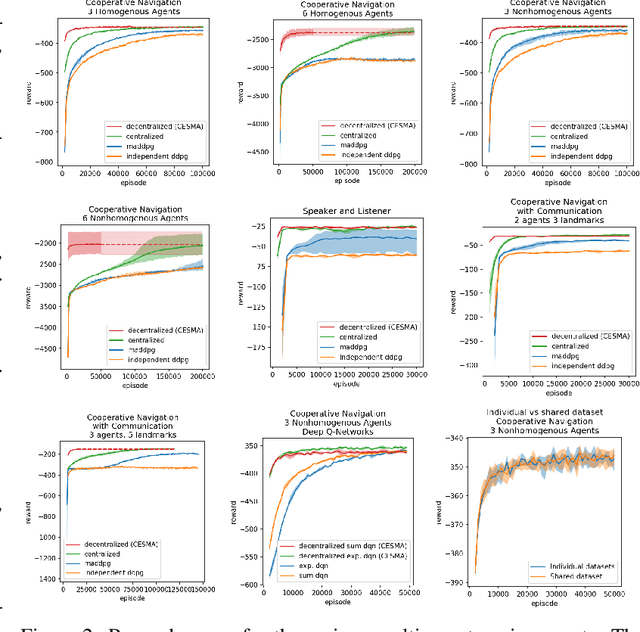
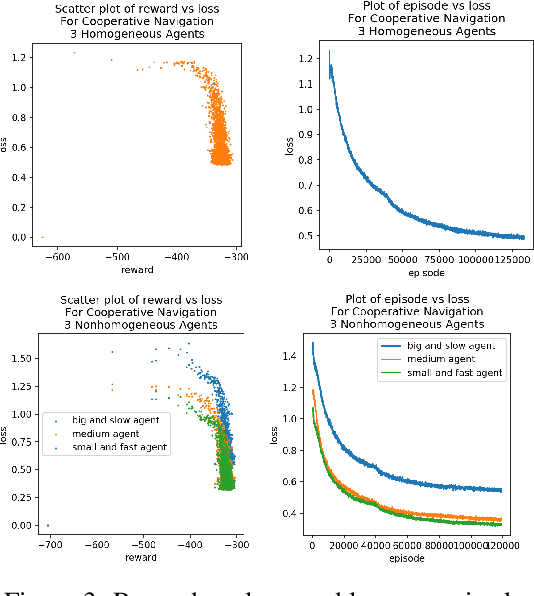
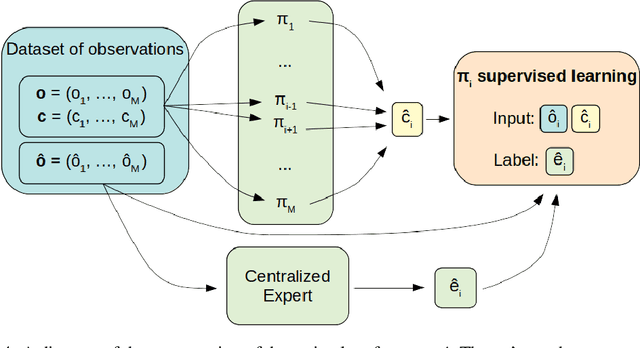
We consider the reinforcement learning problem of training multiple agents in order to maximize a shared reward. In this multi-agent system, each agent seeks to maximize the reward while interacting with other agents, and they may or may not be able to communicate. Typically the agents do not have access to other agent policies and thus each agent observes a non-stationary and partially-observable environment. In order to resolve this issue, we demonstrate a novel multi-agent training framework that first turns a multi-agent problem into a single-agent problem to obtain a centralized expert that is then used to guide supervised learning for multiple independent agents with the goal of decentralizing the policy. We additionally demonstrate a way to turn the exponential growth in the joint action space into a linear growth for the centralized policy. Overall, the problem is twofold: the problem of obtaining a centralized expert, and then the problem of supervised learning to train the multi-agents. We demonstrate our solutions to both of these tasks, and show that supervised learning can be used to decentralize a multi-agent policy.