 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating synthetic multi-dimensional molecular-mediator time series data for artificial intelligence-based disease trajectory forecasting and drug development digital twins: Considerations
Mar 16, 2023

The use of synthetic data is recognized as a crucial step in the development of neural network-based Artificial Intelligence (AI) systems. While the methods for generating synthetic data for AI applications in other domains have a role in certain biomedical AI systems, primarily related to image processing, there is a critical gap in the generation of time series data for AI tasks where it is necessary to know how the system works. This is most pronounced in the ability to generate synthetic multi-dimensional molecular time series data (SMMTSD); this is the type of data that underpins research into biomarkers and mediator signatures for forecasting various diseases and is an essential component of the drug development pipeline. We argue the insufficiency of statistical and data-centric machine learning (ML) means of generating this type of synthetic data is due to a combination of factors: perpetual data sparsity due to the Curse of Dimensionality, the inapplicability of the Central Limit Theorem, and the limits imposed by the Causal Hierarchy Theorem. Alternatively, we present a rationale for using complex multi-scale mechanism-based simulation models, constructed and operated on to account for epistemic incompleteness and the need to provide maximal expansiveness in concordance with the Principle of Maximal Entropy. These procedures provide for the generation of SMMTD that minimizes the known shortcomings associated with neural network AI systems, namely overfitting and lack of generalizability. The generation of synthetic data that accounts for the identified factors of multi-dimensional time series data is an essential capability for the development of mediator-biomarker based AI forecasting systems, and therapeutic control development and optimization through systems like Drug Development Digital Twins.
Facilitating automated conversion of scientific knowledge into scientific simulation models with the Machine Assisted Generation, Calibration, and Comparison (MAGCC) Framework
Apr 21, 2022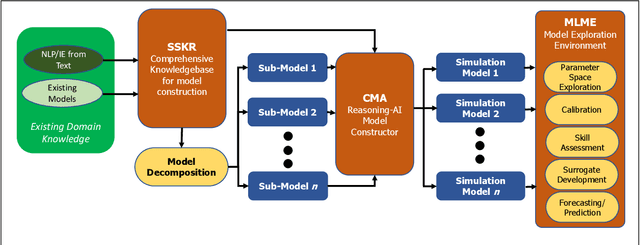
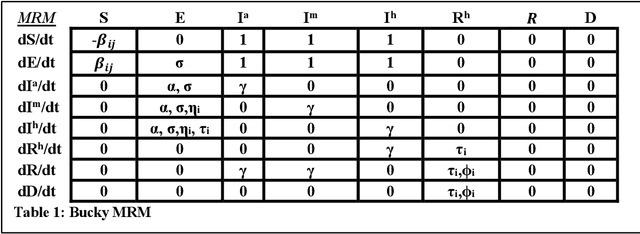
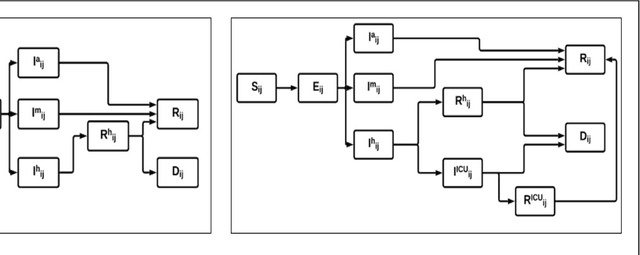
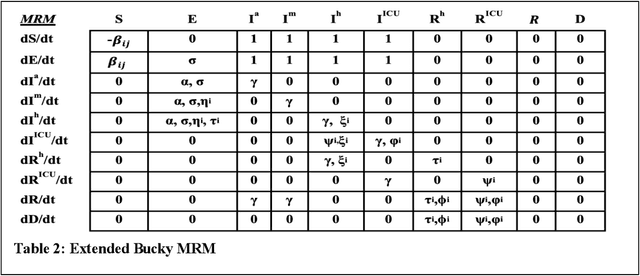
The Machine Assisted Generation, Comparison, and Calibration (MAGCC) framework provides machine assistance and automation of recurrent crucial steps and processes in the development, implementation, testing, and use of scientific simulation models. MAGCC bridges systems for knowledge extraction via natural language processing or extracted from existing mathematical models and provides a comprehensive workflow encompassing the composition of scientific models and artificial intelligence (AI) assisted code generation. MAGCC accomplishes this through: 1) the development of a comprehensively expressive formal knowledge representation knowledgebase, the Structured Scientific Knowledge Representation (SSKR) that encompasses all the types of information needed to make any simulation model, 2) the use of an artificially intelligent logic reasoning system, the Computational Modeling Assistant (CMA), that takes information from the SSKR and generates, in a traceable fashion, model specifications across a range of simulation modeling methods, and 3) the use of the CMA to generate executable code for a simulation model from those model specifications. The MAGCC framework can be customized any scientific domain, and future work will integrate newly developed code-generating AI systems.
Precision medicine as a control problem: Using simulation and deep reinforcement learning to discover adaptive, personalized multi-cytokine therapy for sepsis
Feb 08, 2018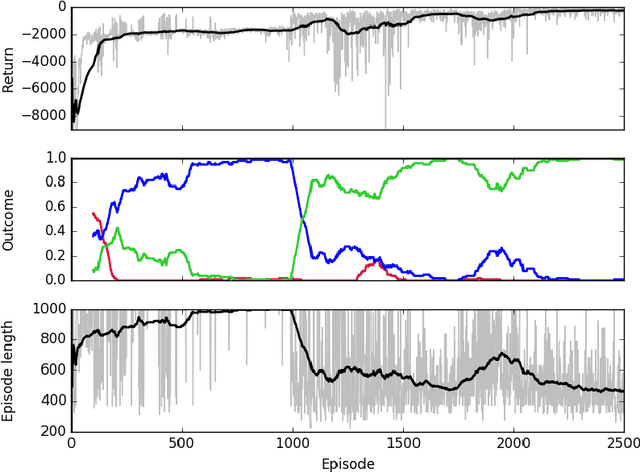
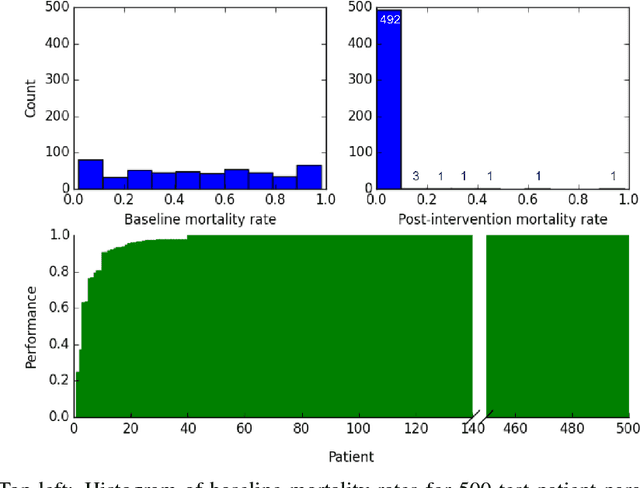
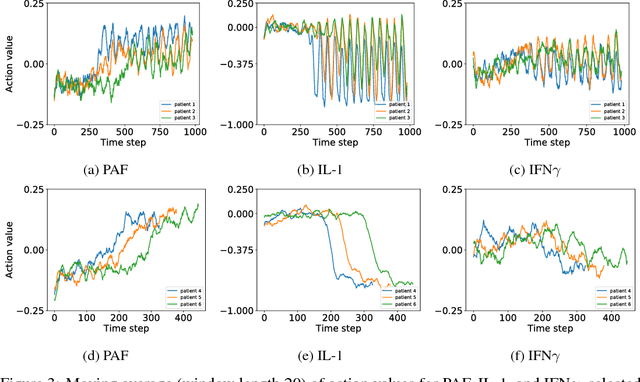
Sepsis is a life-threatening condition affecting one million people per year in the US in which dysregulation of the body's own immune system causes damage to its tissues, resulting in a 28 - 50% mortality rate. Clinical trials for sepsis treatment over the last 20 years have failed to produce a single currently FDA approved drug treatment. In this study, we attempt to discover an effective cytokine mediation treatment strategy for sepsis using a previously developed agent-based model that simulates the innate immune response to infection: the Innate Immune Response agent-based model (IIRABM). Previous attempts at reducing mortality with multi-cytokine mediation using the IIRABM have failed to reduce mortality across all patient parameterizations and motivated us to investigate whether adaptive, personalized multi-cytokine mediation can control the trajectory of sepsis and lower patient mortality. We used the IIRABM to compute a treatment policy in which systemic patient measurements are used in a feedback loop to inform future treatment. Using deep reinforcement learning, we identified a policy that achieves 0% mortality on the patient parameterization on which it was trained. More importantly, this policy also achieves 0.8% mortality over 500 randomly selected patient parameterizations with baseline mortalities ranging from 1 - 99% (with an average of 49%) spanning the entire clinically plausible parameter space of the IIRABM. These results suggest that adaptive, personalized multi-cytokine mediation therapy could be a promising approach for treating sepsis. We hope that this work motivates researchers to consider such an approach as part of future clinical trials. To the best of our knowledge, this work is the first to consider adaptive, personalized multi-cytokine mediation therapy for sepsis, and is the first to exploit deep reinforcement learning on a biological simulation.