 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuSTIP: A Novel Neuro-Symbolic Model for Link and Time Prediction in Temporal Knowledge Graphs
May 15, 2023



While Knowledge Graph Completion (KGC) on static facts is a matured field, Temporal Knowledge Graph Completion (TKGC), that incorporates validity time into static facts is still in its nascent stage. The KGC methods fall into multiple categories including embedding-based, rule-based, GNN-based, pretrained Language Model based approaches. However, such dimensions have not been explored in TKG. To that end, we propose a novel temporal neuro-symbolic model, NeuSTIP, that performs link prediction and time interval prediction in a TKG. NeuSTIP learns temporal rules in the presence of the Allen predicates that ensure the temporal consistency between neighboring predicates in a given rule. We further design a unique scoring function that evaluates the confidence of the candidate answers while performing link prediction and time interval prediction by utilizing the learned rules. Our empirical evaluation on two time interval based TKGC datasets suggests that our model outperforms state-of-the-art models for both link prediction and the time interval prediction task.
BERT Meets Relational DB: Contextual Representations of Relational Databases
Apr 30, 2021

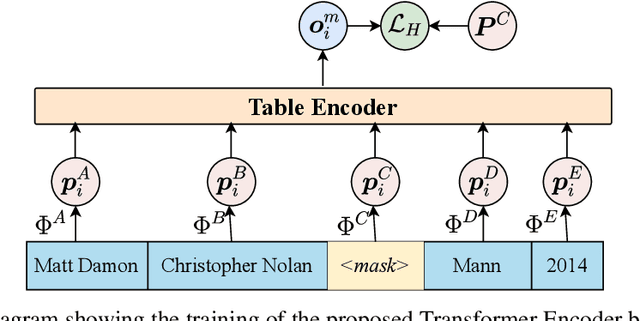

In this paper, we address the problem of learning low dimension representation of entities on relational databases consisting of multiple tables. Embeddings help to capture semantics encoded in the database and can be used in a variety of settings like auto-completion of tables, fully-neural query processing of relational joins queries, seamlessly handling missing values, and more. Current work is restricted to working with just single table, or using pretrained embeddings over an external corpus making them unsuitable for use in real-world databases. In this work, we look into ways of using these attention-based model to learn embeddings for entities in the relational database. We are inspired by BERT style pretraining methods and are interested in observing how they can be extended for representation learning on structured databases. We evaluate our approach of the autocompletion of relational databases and achieve improvement over standard baselines.
Tracking entities in technical procedures -- a new dataset and baselines
Apr 15, 2021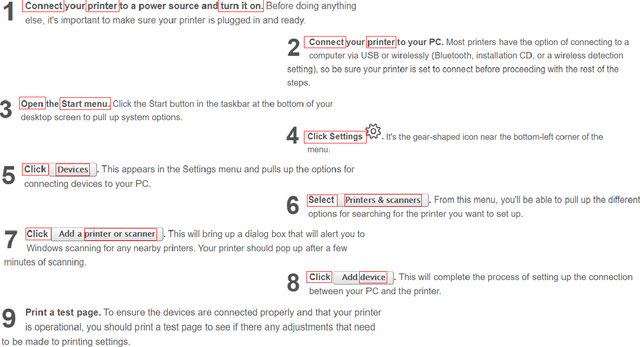

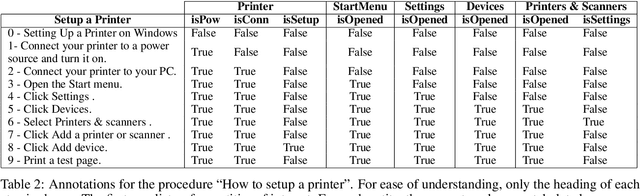
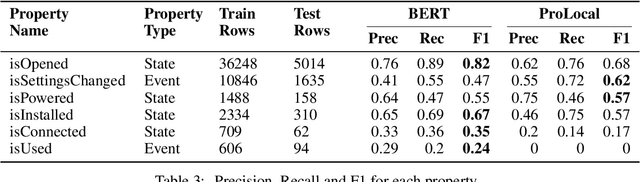
We introduce TechTrack, a new dataset for tracking entities in technical procedures. The dataset, prepared by annotating open domain articles from WikiHow, consists of 1351 procedures, e.g., "How to connect a printer", identifies more than 1200 unique entities with an average of 4.7 entities per procedure. We evaluate the performance of state-of-the-art models on the entity-tracking task and find that they are well below the human annotation performance. We describe how TechTrack can be used to take forward the research on understanding procedures from temporal texts.