 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Learning-based Framework for Spatial Impulse Response Compensation in 3D Photoacoustic Computed Tomography
Jan 28, 2026Photoacoustic computed tomography (PACT) is a promising imaging modality that combines the advantages of optical contrast with ultrasound detection. Utilizing ultrasound transducers with larger surface areas can improve detection sensitivity. However, when computationally efficient analytic reconstruction methods that neglect the spatial impulse responses (SIRs) of the transducer are employed, the spatial resolution of the reconstructed images will be compromised. Although optimization-based reconstruction methods can explicitly account for SIR effects, their computational cost is generally high, particularly in three-dimensional (3D) applications. To address the need for accurate but rapid 3D PACT image reconstruction, this study presents a framework for establishing a learned SIR compensation method that operates in the data domain. The learned compensation method maps SIR-corrupted PACT measurement data to compensated data that would have been recorded by idealized point-like transducers. Subsequently, the compensated data can be used with a computationally efficient reconstruction method that neglects SIR effects. Two variants of the learned compensation model are investigated that employ a U-Net model and a specifically designed, physics-inspired model, referred to as Deconv-Net. A fast and analytical training data generation procedure is also a component of the presented framework. The framework is rigorously validated in virtual imaging studies, demonstrating resolution improvement and robustness to noise variations, object complexity, and sound speed heterogeneity. When applied to in-vivo breast imaging data, the learned compensation models revealed fine structures that had been obscured by SIR-induced artifacts. To our knowledge, this is the first demonstration of learned SIR compensation in 3D PACT imaging.
Benchmarking Deep Learning-Based Reconstruction Methods for Photoacoustic Computed Tomography with Clinically Relevant Synthetic Datasets
Jan 23, 2026Deep learning (DL)-based image reconstruction methods for photoacoustic computed tomography (PACT) have developed rapidly in recent years. However, most existing methods have not employed standardized datasets, and their evaluations rely on traditional image quality (IQ) metrics that may lack clinical relevance. The absence of a standardized framework for clinically meaningful IQ assessment hinders fair comparison and raises concerns about the reproducibility and reliability of reported advancements in PACT. A benchmarking framework is proposed that provides open-source, anatomically plausible synthetic datasets and evaluation strategies for DL-based acoustic inversion methods in PACT. The datasets each include over 11,000 two-dimensional (2D) stochastic breast objects with clinically relevant lesions and paired measurements at varying modeling complexity. The evaluation strategies incorporate both traditional and task-based IQ measures to assess fidelity and clinical utility. A preliminary benchmarking study is conducted to demonstrate the framework's utility by comparing DL-based and physics-based reconstruction methods. The benchmarking study demonstrated that the proposed framework enabled comprehensive, quantitative comparisons of reconstruction performance and revealed important limitations in certain DL-based methods. Although they performed well according to traditional IQ measures, they often failed to accurately recover lesions. This highlights the inadequacy of traditional metrics and motivates the need for task-based assessments. The proposed benchmarking framework enables systematic comparisons of DL-based acoustic inversion methods for 2D PACT. By integrating clinically relevant synthetic datasets with rigorous evaluation protocols, it enables reproducible, objective assessments and facilitates method development and system optimization in PACT.
Revisiting the joint estimation of initial pressure and speed-of-sound distributions in photoacoustic computed tomography with consideration of canonical object constraints
Oct 05, 2024



In photoacoustic computed tomography (PACT) the accurate estimation of the initial pressure (IP) distribution generally requires knowledge of the object's heterogeneous speed-of-sound (SOS) distribution. Although hybrid imagers that combine ultrasound tomography with PACT have been proposed, in many current applications of PACT the SOS distribution remains unknown. Joint reconstruction (JR) of the IP and SOS distributions from PACT measurement data alone can address this issue. However, this joint estimation problem is ill-posed and corresponds to a non-convex optimization problem. While certain regularization strategies have been deployed, stabilizing the JR problem to yield accurate estimates of the IP and SOS distributions has remained an open challenge. To address this, the presented numerical studies explore the effectiveness of easy to implement canonical object constraints for stabilizing the JR problem. The considered constraints include support, bound, and total variation constraints, which are incorporated into an optimization-based method for JR. Computer-simulation studies that employ anatomically realistic numerical breast phantoms are conducted to evaluate the impact of these object constraints on JR accuracy. Additionally, the impact of certain data inconsistencies, such as caused by measurement noise and physics modeling mismatches, on the effectiveness of the object constraints is investigated. The results demonstrate, for the first time, that the incorporation of canonical object constraints in an optimization-based image reconstruction method holds significant potential for mitigating the ill-posed nature of the PACT JR problem.
Investigating the Use of Traveltime and Reflection Tomography for Deep Learning-Based Sound-Speed Estimation in Ultrasound Computed Tomography
Nov 16, 2023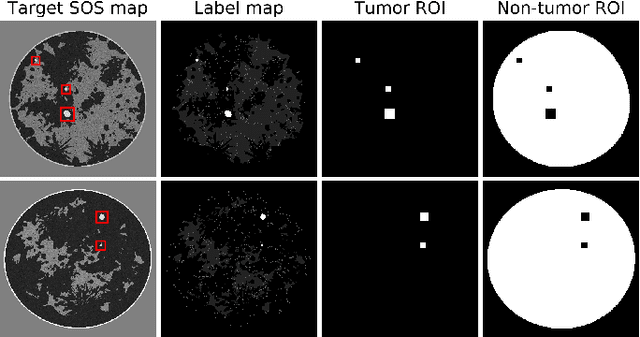


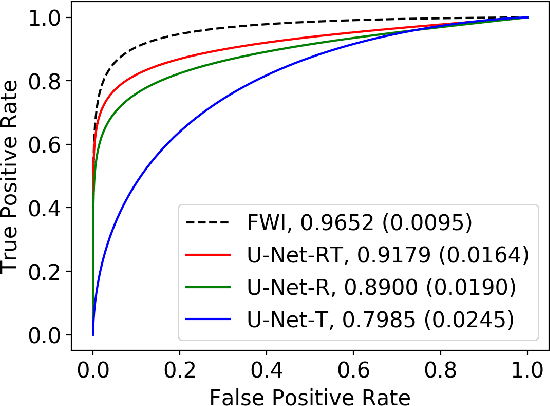
Ultrasound computed tomography (USCT) is actively being developed to quantify acoustic tissue properties such as the speed-of-sound (SOS). Although full-waveform inversion (FWI) is an effective method for accurate SOS reconstruction, it can be computationally challenging for large-scale problems. Deep learning-based image-to-image learned reconstruction (IILR) methods are being investigated as scalable and computationally efficient alternatives. This study investigates the impact of the chosen input modalities on IILR methods for high-resolution SOS reconstruction in USCT. The selected modalities are traveltime tomography (TT) and reflection tomography (RT), which produce a low-resolution SOS map and a reflectivity map, respectively. These modalities have been chosen for their lower computational cost relative to FWI and their capacity to provide complementary information: TT offers a direct -- while low resolution -- SOS measure, while RT reveals tissue boundary information. Systematic analyses were facilitated by employing a stylized USCT imaging system with anatomically realistic numerical breast phantoms. Within this testbed, a supervised convolutional neural network (CNN) was trained to map dual-channel (TT and RT images) to a high-resolution SOS map. Moreover, the CNN was fine-tuned using a weighted reconstruction loss that prioritized tumor regions to address tumor underrepresentation in the training dataset. To understand the benefits of employing dual-channel inputs, single-input CNNs were trained separately using inputs from each modality alone (TT or RT). The methods were assessed quantitatively using normalized root mean squared error and structural similarity index measure for reconstruction accuracy and receiver operating characteristic analysis to assess signal detection-based performance measures.