 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Use of Traveltime and Reflection Tomography for Deep Learning-Based Sound-Speed Estimation in Ultrasound Computed Tomography
Paper and Code
Nov 16, 2023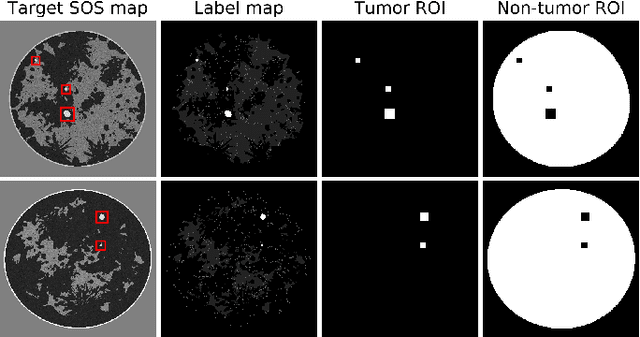


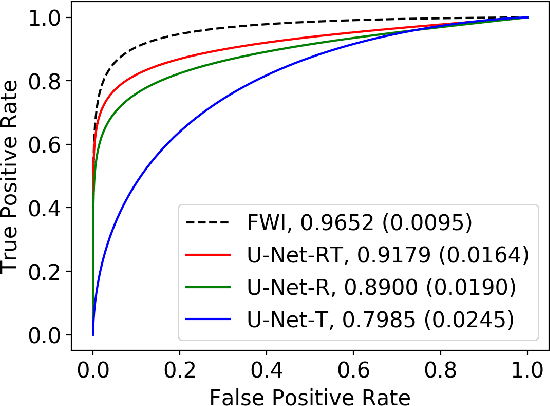
Ultrasound computed tomography (USCT) is actively being developed to quantify acoustic tissue properties such as the speed-of-sound (SOS). Although full-waveform inversion (FWI) is an effective method for accurate SOS reconstruction, it can be computationally challenging for large-scale problems. Deep learning-based image-to-image learned reconstruction (IILR) methods are being investigated as scalable and computationally efficient alternatives. This study investigates the impact of the chosen input modalities on IILR methods for high-resolution SOS reconstruction in USCT. The selected modalities are traveltime tomography (TT) and reflection tomography (RT), which produce a low-resolution SOS map and a reflectivity map, respectively. These modalities have been chosen for their lower computational cost relative to FWI and their capacity to provide complementary information: TT offers a direct -- while low resolution -- SOS measure, while RT reveals tissue boundary information. Systematic analyses were facilitated by employing a stylized USCT imaging system with anatomically realistic numerical breast phantoms. Within this testbed, a supervised convolutional neural network (CNN) was trained to map dual-channel (TT and RT images) to a high-resolution SOS map. Moreover, the CNN was fine-tuned using a weighted reconstruction loss that prioritized tumor regions to address tumor underrepresentation in the training dataset. To understand the benefits of employing dual-channel inputs, single-input CNNs were trained separately using inputs from each modality alone (TT or RT). The methods were assessed quantitatively using normalized root mean squared error and structural similarity index measure for reconstruction accuracy and receiver operating characteristic analysis to assess signal detection-based performance measures.