 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTechING: Towards Real World Technical Image Understanding via VLMs
Jan 26, 2026Professionals working in technical domain typically hand-draw (on whiteboard, paper, etc.) technical diagrams (e.g., flowcharts, block diagrams, etc.) during discussions; however, if they want to edit these later, it needs to be drawn from scratch. Modern day VLMs have made tremendous progress in image understanding but they struggle when it comes to understanding technical diagrams. One way to overcome this problem is to fine-tune on real world hand-drawn images, but it is not practically possible to generate large number of such images. In this paper, we introduce a large synthetically generated corpus (reflective of real world images) for training VLMs and subsequently evaluate VLMs on a smaller corpus of hand-drawn images (with the help of humans). We introduce several new self-supervision tasks for training and perform extensive experiments with various baseline models and fine-tune Llama 3.2 11B-instruct model on synthetic images on these tasks to obtain LLama-VL-TUG, which significantly improves the ROUGE-L performance of Llama 3.2 11B-instruct by 2.14x and achieves the best all-round performance across all baseline models. On real-world images, human evaluation reveals that we achieve minimum compilation errors across all baselines in 7 out of 8 diagram types and improve the average F1 score of Llama 3.2 11B-instruct by 6.97x.
AdaGradSelect: An adaptive gradient-guided layer selection method for efficient fine-tuning of SLMs
Dec 12, 2025Large Language Models (LLMs) can perform many NLP tasks well, but fully fine-tuning them is expensive and requires a lot of memory. Parameter-Efficient Fine-Tuning (PEFT) methods such as LoRA reduce this cost by adding small low-rank updates to frozen model weights. However, these methods restrict the training to a limited subspace, which can sometimes reduce performance. For Small Language Models (SLMs), where efficiency gains matter even more, we introduce AdaGradSelect, an adaptive method that selects which transformer blocks to update based on gradients. Early observations showed that updating only the transformer blocks with the highest gradient norms can achieve performance close to full fine-tuning. Building on this insight, AdaGradSelect adaptively chooses which blocks to train. It uses a combination of Dirichlet-based sampling, which depends on how frequently blocks were updated in the past, and an epsilon-greedy exploration strategy. This lets the method explore different blocks in early training and gradually focus on the most important ones in later epochs. Experiments show that AdaGradSelect trains about 12 percent faster and uses 35 percent less GPU memory while delivering performance very close to full fine-tuning. On the GSM8K dataset, it outperforms LoRA (rank 256) by about 3 percent on average across models such as Qwen2.5-0.5B, LLaMA3.2-1B, and Phi4-mini-3.8B. It also achieves similar accuracy on the MATH dataset. Overall, AdaGradSelect provides a more effective and resource-efficient alternative to traditional fine-tuning methods.
MM-Telco: Benchmarks and Multimodal Large Language Models for Telecom Applications
Nov 17, 2025Large Language Models (LLMs) have emerged as powerful tools for automating complex reasoning and decision-making tasks. In telecommunications, they hold the potential to transform network optimization, automate troubleshooting, enhance customer support, and ensure regulatory compliance. However, their deployment in telecom is hindered by domain-specific challenges that demand specialized adaptation. To overcome these challenges and to accelerate the adaptation of LLMs for telecom, we propose MM-Telco, a comprehensive suite of multimodal benchmarks and models tailored for the telecom domain. The benchmark introduces various tasks (both text based and image based) that address various practical real-life use cases such as network operations, network management, improving documentation quality, and retrieval of relevant text and images. Further, we perform baseline experiments with various LLMs and VLMs. The models fine-tuned on our dataset exhibit a significant boost in performance. Our experiments also help analyze the weak areas in the working of current state-of-art multimodal LLMs, thus guiding towards further development and research.
Autograder+: A Multi-Faceted AI Framework for Rich Pedagogical Feedback in Programming Education
Oct 30, 2025The rapid growth of programming education has outpaced traditional assessment tools, leaving faculty with limited means to provide meaningful, scalable feedback. Conventional autograders, while efficient, act as black-box systems that simply return pass/fail results, offering little insight into student thinking or learning needs. Autograder+ is designed to shift autograding from a purely summative process to a formative learning experience. It introduces two key capabilities: automated feedback generation using a fine-tuned Large Language Model, and visualization of student code submissions to uncover learning patterns. The model is fine-tuned on curated student code and expert feedback to ensure pedagogically aligned, context-aware guidance. In evaluation across 600 student submissions from multiple programming tasks, the system produced feedback with strong semantic alignment to instructor comments. For visualization, contrastively learned code embeddings trained on 1,000 annotated submissions enable grouping solutions into meaningful clusters based on functionality and approach. The system also supports prompt-pooling, allowing instructors to guide feedback style through selected prompt templates. By integrating AI-driven feedback, semantic clustering, and interactive visualization, Autograder+ reduces instructor workload while supporting targeted instruction and promoting stronger learning outcomes.
Process Integrated Computer Vision for Real-Time Failure Prediction in Steel Rolling Mill
Oct 30, 2025We present a long-term deployment study of a machine vision-based anomaly detection system for failure prediction in a steel rolling mill. The system integrates industrial cameras to monitor equipment operation, alignment, and hot bar motion in real time along the process line. Live video streams are processed on a centralized video server using deep learning models, enabling early prediction of equipment failures and process interruptions, thereby reducing unplanned breakdown costs. Server-based inference minimizes the computational load on industrial process control systems (PLCs), supporting scalable deployment across production lines with minimal additional resources. By jointly analyzing sensor data from data acquisition systems and visual inputs, the system identifies the location and probable root causes of failures, providing actionable insights for proactive maintenance. This integrated approach enhances operational reliability, productivity, and profitability in industrial manufacturing environments.
Action Recognition based Industrial Safety Violation Detection
Dec 07, 2024Proper use of personal protective equipment (PPE) can save the lives of industry workers and it is a widely used application of computer vision in the large manufacturing industries. However, most of the applications deployed generate a lot of false alarms (violations) because they tend to generalize the requirements of PPE across the industry and tasks. The key to resolving this issue is to understand the action being performed by the worker and customize the inference for the specific PPE requirements of that action. In this paper, we propose a system that employs activity recognition models to first understand the action being performed and then use object detection techniques to check for violations. This leads to a 23% improvement in the F1-score compared to the PPE-based approach on our test dataset of 109 videos.
PatchAlign:Fair and Accurate Skin Disease Image Classification by Alignment with Clinical Labels
Sep 08, 2024



Deep learning models have achieved great success in automating skin lesion diagnosis. However, the ethnic disparity in these models' predictions needs to be addressed before deploying them. We introduce a novel approach, PatchAlign, to enhance skin condition image classification accuracy and fairness by aligning with clinical text representations of skin conditions. PatchAlign uses Graph Optimal Transport (GOT) Loss as a regularizer to perform cross-domain alignment. The representations obtained are robust and generalize well across skin tones, even with limited training samples. To reduce the effect of noise and artifacts in clinical dermatology images, we propose a learnable Masked Graph Optimal Transport for cross-domain alignment that further improves fairness metrics. We compare our model to the state-of-the-art FairDisCo on two skin lesion datasets with different skin types: Fitzpatrick17k and Diverse Dermatology Images (DDI). PatchAlign enhances the accuracy of skin condition image classification by 2.8% (in-domain) and 6.2% (out-domain) on Fitzpatrick17k, and 4.2% (in-domain) on DDI compared to FairDisCo. Additionally, it consistently improves the fairness of true positive rates across skin tones. The source code for the implementation is available at the following GitHub repository: https://github.com/aayushmanace/PatchAlign24, enabling easy reproduction and further experimentation.
DiffRed: Dimensionality Reduction guided by stable rank
Mar 09, 2024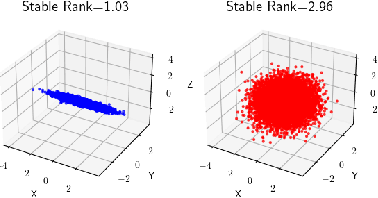
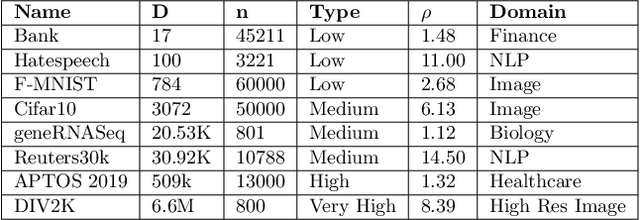
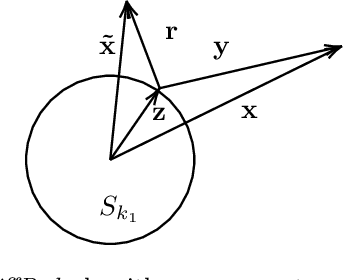
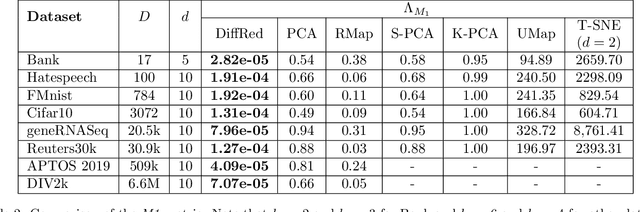
In this work, we propose a novel dimensionality reduction technique, DiffRed, which first projects the data matrix, A, along first $k_1$ principal components and the residual matrix $A^{*}$ (left after subtracting its $k_1$-rank approximation) along $k_2$ Gaussian random vectors. We evaluate M1, the distortion of mean-squared pair-wise distance, and Stress, the normalized value of RMS of distortion of the pairwise distances. We rigorously prove that DiffRed achieves a general upper bound of $O\left(\sqrt{\frac{1-p}{k_2}}\right)$ on Stress and $O\left(\frac{(1-p)}{\sqrt{k_2*\rho(A^{*})}}\right)$ on M1 where $p$ is the fraction of variance explained by the first $k_1$ principal components and $\rho(A^{*})$ is the stable rank of $A^{*}$. These bounds are tighter than the currently known results for Random maps. Our extensive experiments on a variety of real-world datasets demonstrate that DiffRed achieves near zero M1 and much lower values of Stress as compared to the well-known dimensionality reduction techniques. In particular, DiffRed can map a 6 million dimensional dataset to 10 dimensions with 54% lower Stress than PCA.
Entropy Aware Training for Fast and Accurate Distributed GNN
Nov 04, 2023



Several distributed frameworks have been developed to scale Graph Neural Networks (GNNs) on billion-size graphs. On several benchmarks, we observe that the graph partitions generated by these frameworks have heterogeneous data distributions and class imbalance, affecting convergence, and resulting in lower performance than centralized implementations. We holistically address these challenges and develop techniques that reduce training time and improve accuracy. We develop an Edge-Weighted partitioning technique to improve the micro average F1 score (accuracy) by minimizing the total entropy. Furthermore, we add an asynchronous personalization phase that adapts each compute-host's model to its local data distribution. We design a class-balanced sampler that considerably speeds up convergence. We implemented our algorithms on the DistDGL framework and observed that our training techniques scale much better than the existing training approach. We achieved a (2-3x) speedup in training time and 4\% improvement on average in micro-F1 scores on 5 large graph benchmarks compared to the standard baselines.
PFSL: Personalized & Fair Split Learning with Data & Label Privacy for thin clients
Mar 19, 2023



The traditional framework of federated learning (FL) requires each client to re-train their models in every iteration, making it infeasible for resource-constrained mobile devices to train deep-learning (DL) models. Split learning (SL) provides an alternative by using a centralized server to offload the computation of activations and gradients for a subset of the model but suffers from problems of slow convergence and lower accuracy. In this paper, we implement PFSL, a new framework of distributed split learning where a large number of thin clients perform transfer learning in parallel, starting with a pre-trained DL model without sharing their data or labels with a central server. We implement a lightweight step of personalization of client models to provide high performance for their respective data distributions. Furthermore, we evaluate performance fairness amongst clients under a work fairness constraint for various scenarios of non-i.i.d. data distributions and unequal sample sizes. Our accuracy far exceeds that of current SL algorithms and is very close to that of centralized learning on several real-life benchmarks. It has a very low computation cost compared to FL variants and promises to deliver the full benefits of DL to extremely thin, resource-constrained clients.