 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating the number of household TV profiles based in customer behaviour using Gaussian mixture model averaging
May 15, 2025TV customers today face many choices from many live channels and on-demand services. Providing a personalised experience that saves customers time when discovering content is essential for TV providers. However, a reliable understanding of their behaviour and preferences is key. When creating personalised recommendations for TV, the biggest challenge is understanding viewing behaviour within households when multiple people are watching. The objective is to detect and combine individual profiles to make better-personalised recommendations for group viewing. Our challenge is that we have little explicit information about who is watching the devices at any time (individuals or groups). Also, we do not have a way to combine more than one individual profile to make better recommendations for group viewing. We propose a novel framework using a Gaussian mixture model averaging to obtain point estimates for the number of household TV profiles and a Bayesian random walk model to introduce uncertainty. We applied our approach using data from real customers whose TV-watching data totalled approximately half a million observations. Our results indicate that combining our framework with the selected features provides a means to estimate the number of household TV profiles and their characteristics, including shifts over time and quantification of uncertainty.
Asset price movement prediction using empirical mode decomposition and Gaussian mixture models
Mar 26, 2025We investigated the use of Empirical Mode Decomposition (EMD) combined with Gaussian Mixture Models (GMM), feature engineering and machine learning algorithms to optimize trading decisions. We used five, two, and one year samples of hourly candle data for GameStop, Tesla, and XRP (Ripple) markets respectively. Applying a 15 hour rolling window for each market, we collected several features based on a linear model and other classical features to predict the next hour's movement. Subsequently, a GMM filtering approach was used to identify clusters among these markets. For each cluster, we applied the EMD algorithm to extract high, medium, low and trend components from each feature collected. A simple thresholding algorithm was applied to classify market movements based on the percentage change in each market's close price. We then evaluated the performance of various machine learning models, including Random Forests (RF) and XGBoost, in classifying market movements. A naive random selection of trading decisions was used as a benchmark, which assumed equal probabilities for each outcome, and a temporal cross-validation approach was used to test models on 40%, 30%, and 20% of the dataset. Our results indicate that transforming selected features using EMD improves performance, particularly for ensemble learning algorithms like Random Forest and XGBoost, as measured by accumulated profit. Finally, GMM filtering expanded the range of learning algorithm and data source combinations that outperformed the top percentile of the random baseline.
Profiling Television Watching Behaviour Using Bayesian Hierarchical Joint Models for Time-to-Event and Count Data
Sep 06, 2022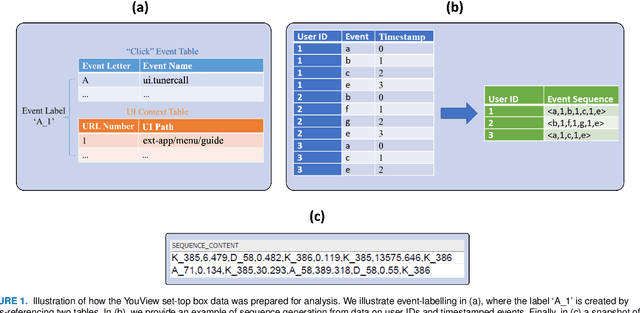
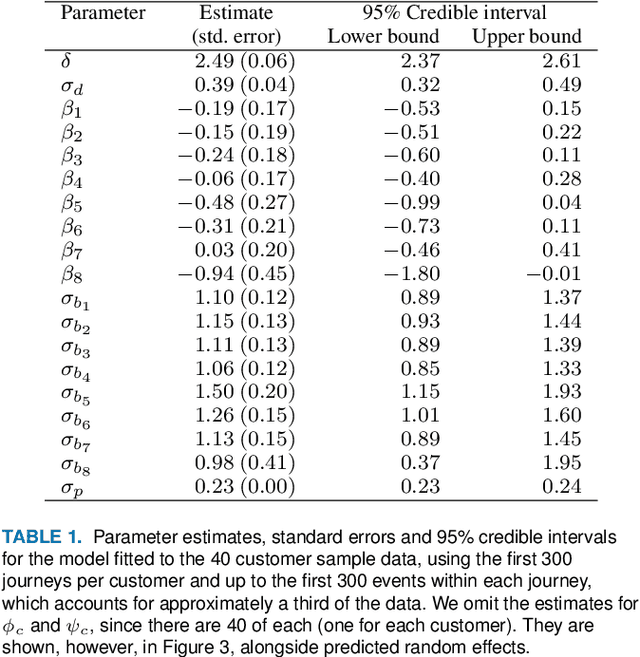

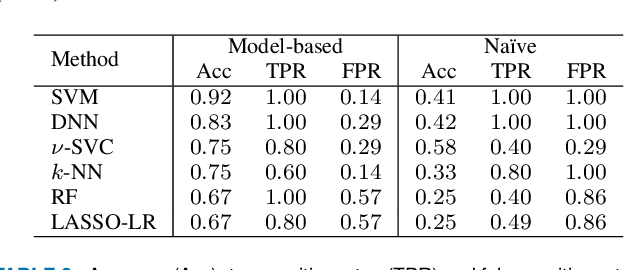
Customer churn prediction is a valuable task in many industries. In telecommunications it presents great challenges, given the high dimensionality of the data, and how difficult it is to identify underlying frustration signatures, which may represent an important driver regarding future churn behaviour. Here, we propose a novel Bayesian hierarchical joint model that is able to characterise customer profiles based on how many events take place within different television watching journeys, and how long it takes between events. The model drastically reduces the dimensionality of the data from thousands of observations per customer to 11 customer-level parameter estimates and random effects. We test our methodology using data from 40 BT customers (20 active and 20 who eventually cancelled their subscription) whose TV watching behaviours were recorded from October to December 2019, totalling approximately half a million observations. Employing different machine learning techniques using the parameter estimates and random effects from the Bayesian hierarchical model as features yielded up to 92\% accuracy predicting churn, associated with 100\% true positive rates and false positive rates as low as 14\% on a validation set. Our proposed methodology represents an efficient way of reducing the dimensionality of the data, while at the same time maintaining high descriptive and predictive capabilities. We provide code to implement the Bayesian model at https://github.com/rafamoral/profiling_tv_watching_behaviour.