 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimization of Functions on Dually Flat Spaces Using Geodesic Descent Based on Dual Connections
Dec 10, 2025



We propose geodesic-based optimization methods on dually flat spaces, where the geometric structure of the parameter manifold is closely related to the form of the objective function. A primary application is maximum likelihood estimation in statistical models, especially exponential families, whose model manifolds are dually flat. We show that an m-geodesic update, which directly optimizes the log-likelihood, can theoretically reach the maximum likelihood estimator in a single step. In contrast, an e-geodesic update has a practical advantage in cases where the parameter space is geodesically complete, allowing optimization without explicitly handling parameter constraints. We establish the theoretical properties of the proposed methods and validate their effectiveness through numerical experiments.
BHGNN-RT: Network embedding for directed heterogeneous graphs
Nov 24, 2023Networks are one of the most valuable data structures for modeling problems in the real world. However, the most recent node embedding strategies have focused on undirected graphs, with limited attention to directed graphs, especially directed heterogeneous graphs. In this study, we first investigated the network properties of directed heterogeneous graphs. Based on network analysis, we proposed an embedding method, a bidirectional heterogeneous graph neural network with random teleport (BHGNN-RT), for directed heterogeneous graphs, that leverages bidirectional message-passing process and network heterogeneity. With the optimization of teleport proportion, BHGNN-RT is beneficial to overcome the over-smoothing problem. Extensive experiments on various datasets were conducted to verify the efficacy and efficiency of BHGNN-RT. Furthermore, we investigated the effects of message components, model layer, and teleport proportion on model performance. The performance comparison with all other baselines illustrates that BHGNN-RT achieves state-of-the-art performance, outperforming the benchmark methods in both node classification and unsupervised clustering tasks.
Learning partially ranked data based on graph regularization
Feb 28, 2019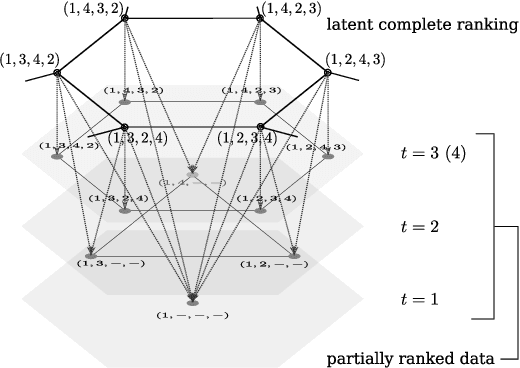
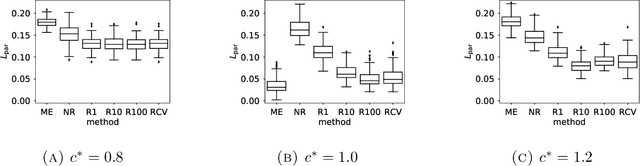
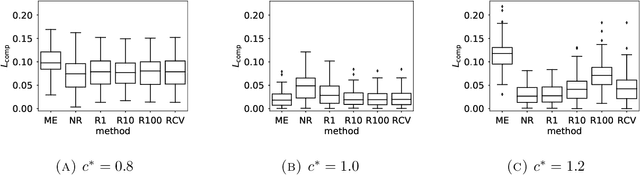
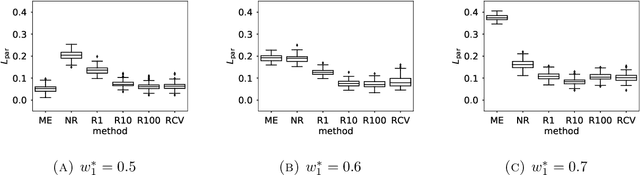
Ranked data appear in many different applications, including voting and consumer surveys. There often exhibits a situation in which data are partially ranked. Partially ranked data is thought of as missing data. This paper addresses parameter estimation for partially ranked data under a (possibly) non-ignorable missing mechanism. We propose estimators for both complete rankings and missing mechanisms together with a simple estimation procedure. Our estimation procedure leverages a graph regularization in conjunction with the Expectation-Maximization algorithm. Our estimation procedure is theoretically guaranteed to have the convergence properties. We reduce a modeling bias by allowing a non-ignorable missing mechanism. In addition, we avoid the inherent complexity within a non-ignorable missing mechanism by introducing a graph regularization. The experimental results demonstrate that the proposed estimators work well under non-ignorable missing mechanisms.
Analysis of Noise Contrastive Estimation from the Perspective of Asymptotic Variance
Aug 24, 2018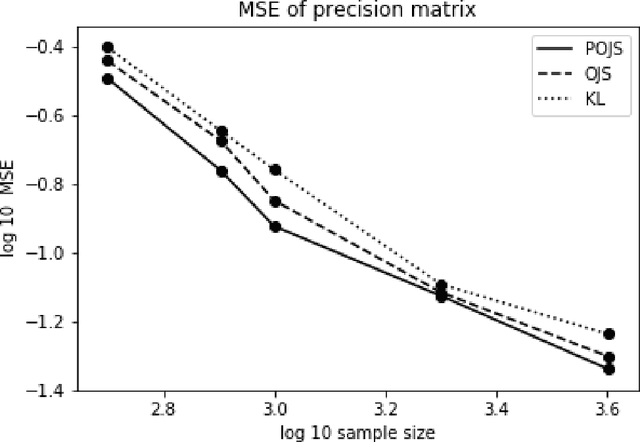
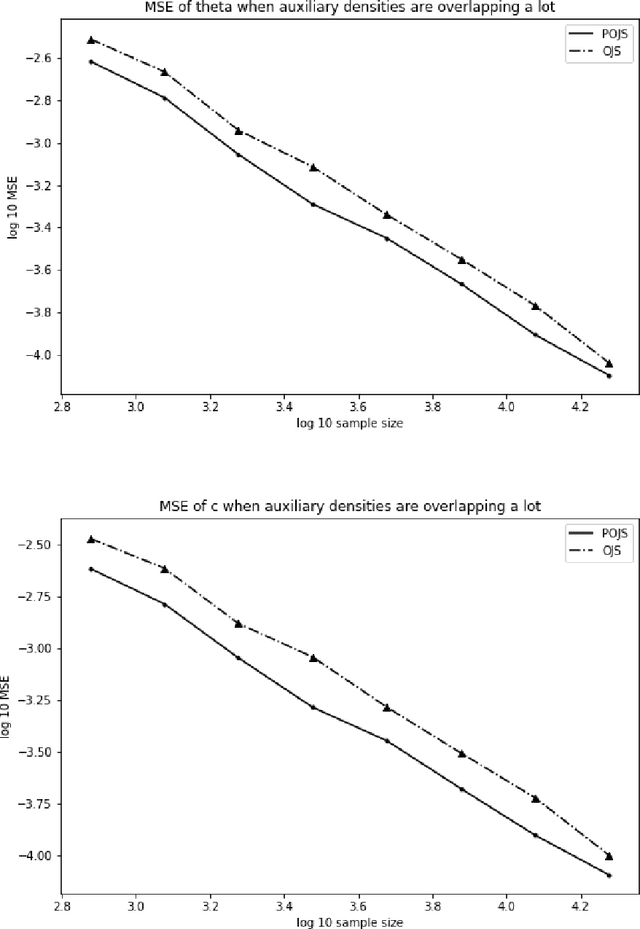
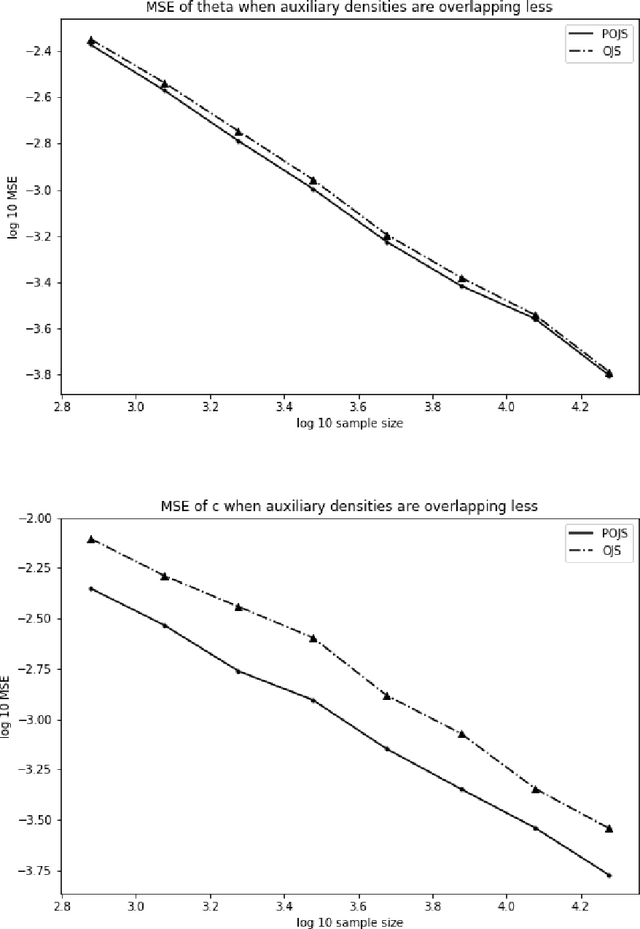

There are many models, often called unnormalized models, whose normalizing constants are not calculated in closed form. Maximum likelihood estimation is not directly applicable to unnormalized models. Score matching, contrastive divergence method, pseudo-likelihood, Monte Carlo maximum likelihood, and noise contrastive estimation (NCE) are popular methods for estimating parameters of such models. In this paper, we focus on NCE. The estimator derived from NCE is consistent and asymptotically normal because it is an M-estimator. NCE characteristically uses an auxiliary distribution to calculate the normalizing constant in the same spirit of the importance sampling. In addition, there are several candidates as objective functions of NCE. We focus on how to reduce asymptotic variance. First, we propose a method for reducing asymptotic variance by estimating the parameters of the auxiliary distribution. Then, we determine the form of the objective functions, where the asymptotic variance takes the smallest values in the original estimator class and the proposed estimator classes. We further analyze the robustness of the estimator.
Empirical Bayes Matrix Completion
Jun 06, 2017

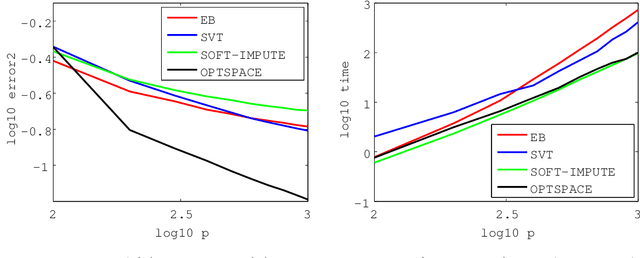
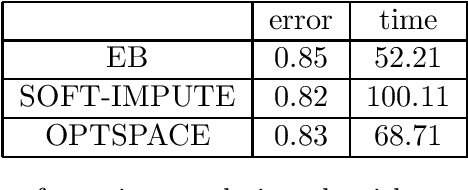
We develop an empirical Bayes (EB) algorithm for the matrix completion problems. The EB algorithm is motivated from the singular value shrinkage estimator for matrix means by Efron and Morris (1972). Since the EB algorithm is essentially the EM algorithm applied to a simple model, it does not require heuristic parameter tuning other than tolerance. Numerical results demonstrated that the EB algorithm achieves a good trade-off between accuracy and efficiency compared to existing algorithms and that it works particularly well when the difference between the number of rows and columns is large. Application to real data also shows the practical utility of the EB algorithm.