 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond EM Algorithm on Over-specified Two-Component Location-Scale Gaussian Mixtures
May 23, 2022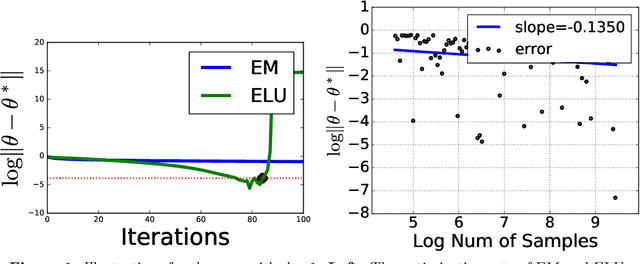



The Expectation-Maximization (EM) algorithm has been predominantly used to approximate the maximum likelihood estimation of the location-scale Gaussian mixtures. However, when the models are over-specified, namely, the chosen number of components to fit the data is larger than the unknown true number of components, EM needs a polynomial number of iterations in terms of the sample size to reach the final statistical radius; this is computationally expensive in practice. The slow convergence of EM is due to the missing of the locally strong convexity with respect to the location parameter on the negative population log-likelihood function, i.e., the limit of the negative sample log-likelihood function when the sample size goes to infinity. To efficiently explore the curvature of the negative log-likelihood functions, by specifically considering two-component location-scale Gaussian mixtures, we develop the Exponential Location Update (ELU) algorithm. The idea of the ELU algorithm is that we first obtain the exact optimal solution for the scale parameter and then perform an exponential step-size gradient descent for the location parameter. We demonstrate theoretically and empirically that the ELU iterates converge to the final statistical radius of the models after a logarithmic number of iterations. To the best of our knowledge, it resolves the long-standing open question in the literature about developing an optimization algorithm that has optimal statistical and computational complexities for solving parameter estimation even under some specific settings of the over-specified Gaussian mixture models.
Towards Statistical and Computational Complexities of Polyak Step Size Gradient Descent
Oct 15, 2021
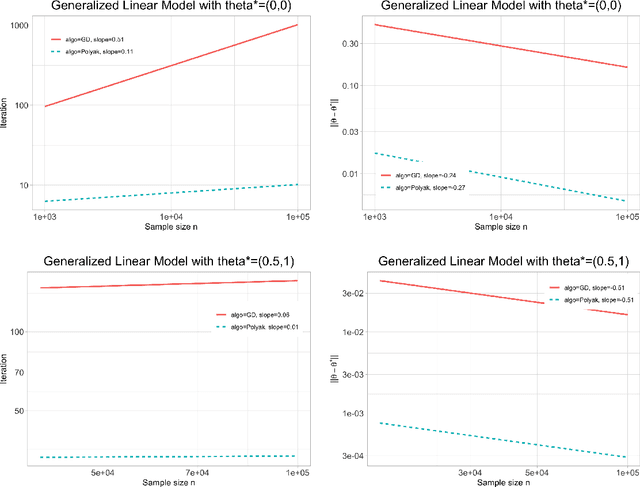

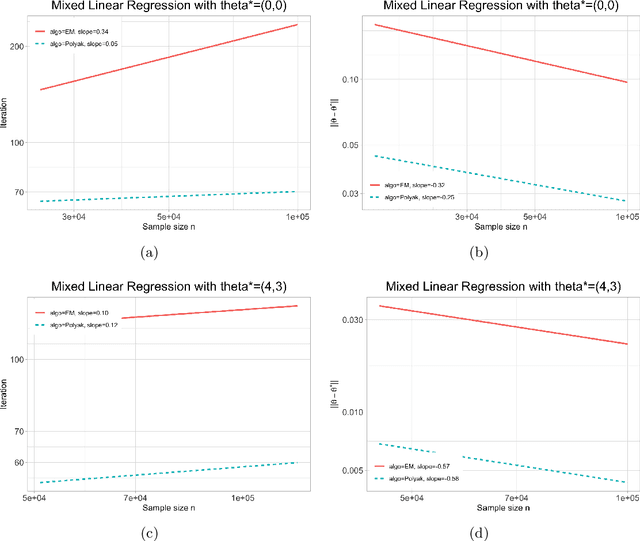
We study the statistical and computational complexities of the Polyak step size gradient descent algorithm under generalized smoothness and Lojasiewicz conditions of the population loss function, namely, the limit of the empirical loss function when the sample size goes to infinity, and the stability between the gradients of the empirical and population loss functions, namely, the polynomial growth on the concentration bound between the gradients of sample and population loss functions. We demonstrate that the Polyak step size gradient descent iterates reach a final statistical radius of convergence around the true parameter after logarithmic number of iterations in terms of the sample size. It is computationally cheaper than the polynomial number of iterations on the sample size of the fixed-step size gradient descent algorithm to reach the same final statistical radius when the population loss function is not locally strongly convex. Finally, we illustrate our general theory under three statistical examples: generalized linear model, mixture model, and mixed linear regression model.