 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Surrogate Learning of Objectives, Constraints, and Sensitivities for Efficient Multi-objective Optimization of Neural Dynamical Systems
Mar 22, 2026Biophysical neural system simulations are among the most computationally demanding scientific applications, and their optimization requires navigating high-dimensional parameter spaces under numerous constraints that impose a binary feasible/infeasible partition with no gradient signal to guide the search. Here, we introduce DMOSOPT, a scalable optimization framework that leverages a unified, jointly learned surrogate model to capture the interplay between objectives, constraints, and parameter sensitivities. By learning a smooth approximation of both the objective landscape and the feasibility boundary, the joint surrogate provides a unified gradient that simultaneously steers the search toward improved objective values and greater constraint satisfaction, while its partial derivatives yield per-parameter sensitivity estimates that enable more targeted exploration. We validate the framework from single-cell dynamics to population-level network activity, spanning incremental stages of a neural circuit modeling workflow, and demonstrate efficient, effective optimization of highly constrained problems at supercomputing scale with substantially fewer problem evaluations. While motivated by and demonstrated in the context of computational neuroscience, the framework is general and applicable to constrained multi-objective optimization problems across scientific and engineering domains.
Towards Structured Dynamic Sparse Pre-Training of BERT
Aug 13, 2021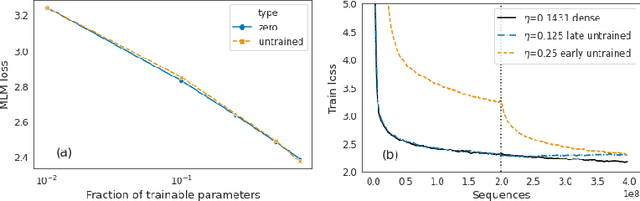
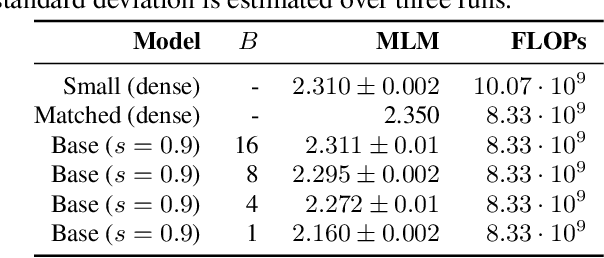
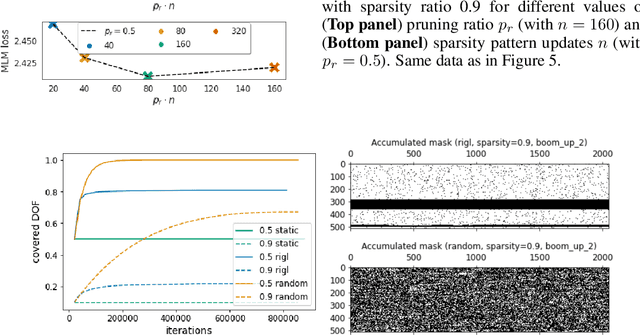
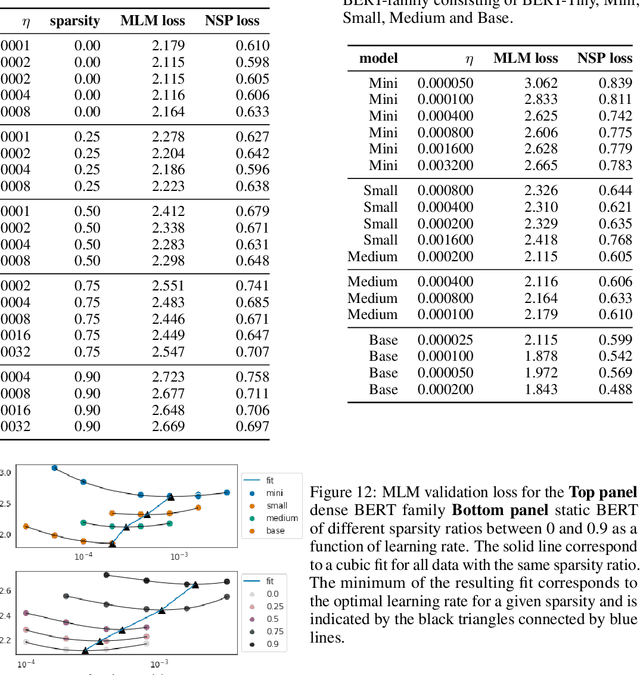
Identifying algorithms for computational efficient unsupervised training of large language models is an important and active area of research. In this work, we develop and study a straightforward, dynamic always-sparse pre-training approach for BERT language modeling task, which leverages periodic compression steps based on magnitude pruning followed by random parameter re-allocation. This approach enables us to achieve Pareto improvements in terms of the number of floating-point operations (FLOPs) over statically sparse and dense models across a broad spectrum of network sizes. Furthermore, we demonstrate that training remains FLOP-efficient when using coarse-grained block sparsity, making it particularly promising for efficient execution on modern hardware accelerators.
GroupBERT: Enhanced Transformer Architecture with Efficient Grouped Structures
Jun 10, 2021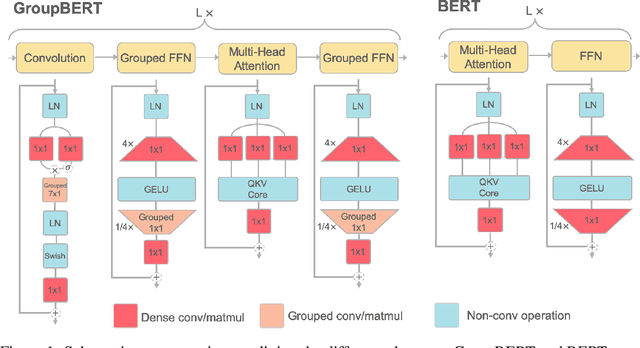
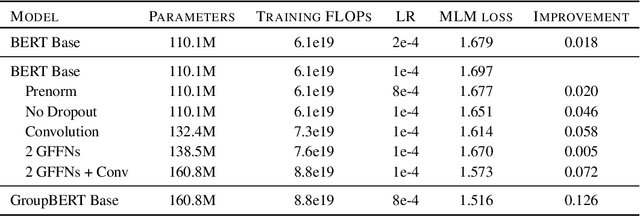

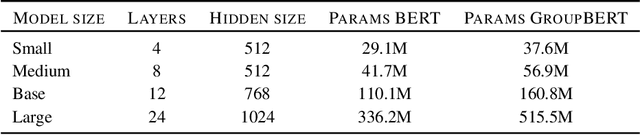
Attention based language models have become a critical component in state-of-the-art natural language processing systems. However, these models have significant computational requirements, due to long training times, dense operations and large parameter count. In this work we demonstrate a set of modifications to the structure of a Transformer layer, producing a more efficient architecture. First, we add a convolutional module to complement the self-attention module, decoupling the learning of local and global interactions. Secondly, we rely on grouped transformations to reduce the computational cost of dense feed-forward layers and convolutions, while preserving the expressivity of the model. We apply the resulting architecture to language representation learning and demonstrate its superior performance compared to BERT models of different scales. We further highlight its improved efficiency, both in terms of floating-point operations (FLOPs) and time-to-train.
Improving Neural Network Training in Low Dimensional Random Bases
Nov 09, 2020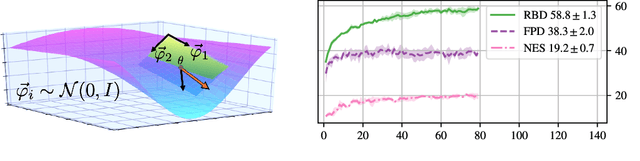



Stochastic Gradient Descent (SGD) has proven to be remarkably effective in optimizing deep neural networks that employ ever-larger numbers of parameters. Yet, improving the efficiency of large-scale optimization remains a vital and highly active area of research. Recent work has shown that deep neural networks can be optimized in randomly-projected subspaces of much smaller dimensionality than their native parameter space. While such training is promising for more efficient and scalable optimization schemes, its practical application is limited by inferior optimization performance. Here, we improve on recent random subspace approaches as follows: Firstly, we show that keeping the random projection fixed throughout training is detrimental to optimization. We propose re-drawing the random subspace at each step, which yields significantly better performance. We realize further improvements by applying independent projections to different parts of the network, making the approximation more efficient as network dimensionality grows. To implement these experiments, we leverage hardware-accelerated pseudo-random number generation to construct the random projections on-demand at every optimization step, allowing us to distribute the computation of independent random directions across multiple workers with shared random seeds. This yields significant reductions in memory and is up to 10 times faster for the workloads in question.
Probabilistic supervised learning
Apr 28, 2018
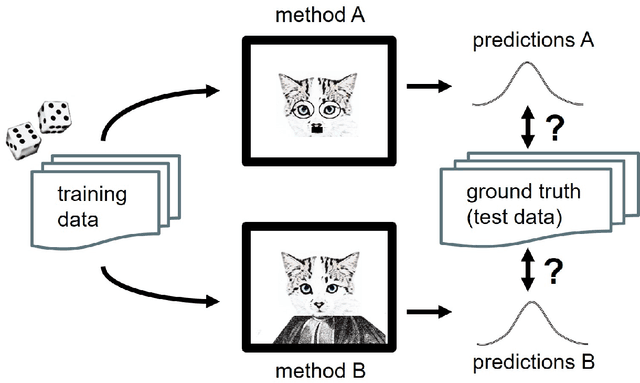
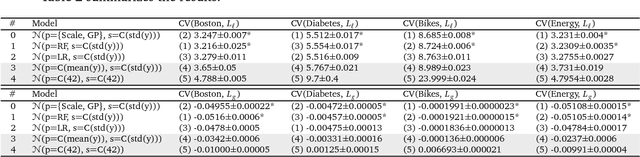
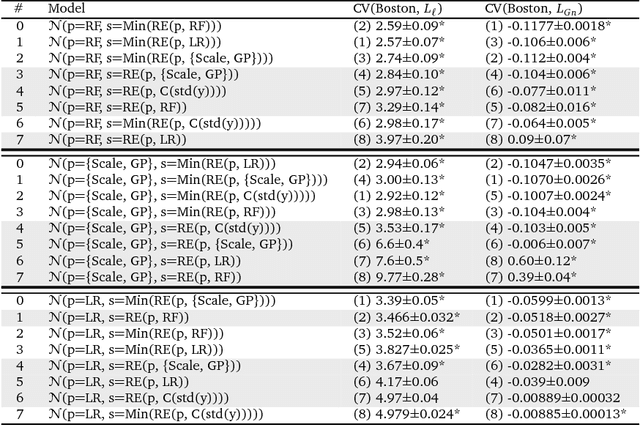
Predictive modelling and supervised learning are central to modern data science. With predictions from an ever-expanding number of supervised black-box strategies - e.g., kernel methods, random forests, deep learning aka neural networks - being employed as a basis for decision making processes, it is crucial to understand the statistical uncertainty associated with these predictions. As a general means to approach the issue, we present an overarching framework for black-box prediction strategies that not only predict the target but also their own predictions' uncertainty. Moreover, the framework allows for fair assessment and comparison of disparate prediction strategies. For this, we formally consider strategies capable of predicting full distributions from feature variables, so-called probabilistic supervised learning strategies. Our work draws from prior work including Bayesian statistics, information theory, and modern supervised machine learning, and in a novel synthesis leads to (a) new theoretical insights such as a probabilistic bias-variance decomposition and an entropic formulation of prediction, as well as to (b) new algorithms and meta-algorithms, such as composite prediction strategies, probabilistic boosting and bagging, and a probabilistic predictive independence test. Our black-box formulation also leads (c) to a new modular interface view on probabilistic supervised learning and a modelling workflow API design, which we have implemented in the newly released skpro machine learning toolbox, extending the familiar modelling interface and meta-modelling functionality of sklearn. The skpro package provides interfaces for construction, composition, and tuning of probabilistic supervised learning strategies, together with orchestration features for validation and comparison of any such strategy - be it frequentist, Bayesian, or other.