 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance Segmentation of Microscopic Foraminifera
May 15, 2021
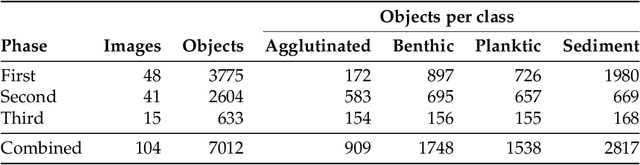
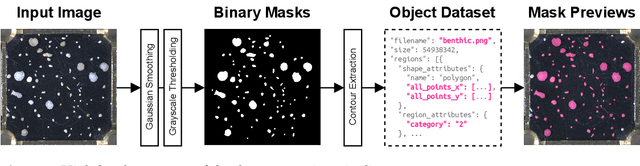
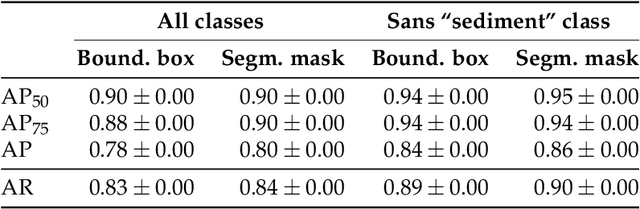
Foraminifera are single-celled marine organisms that construct shells that remain as fossils in the marine sediments. Classifying and counting these fossils are important in e.g. paleo-oceanographic and -climatological research. However, the identification and counting process has been performed manually since the 1800s and is laborious and time-consuming. In this work, we present a deep learning-based instance segmentation model for classifying, detecting, and segmenting microscopic foraminifera. Our model is based on the Mask R-CNN architecture, using model weight parameters that have learned on the COCO detection dataset. We use a fine-tuning approach to adapt the parameters on a novel object detection dataset of more than 7000 microscopic foraminifera and sediment grains. The model achieves a (COCO-style) average precision of $0.78 \pm 0.00$ on the classification and detection task, and $0.80 \pm 0.00$ on the segmentation task. When the model is evaluated without challenging sediment grain images, the average precision for both tasks increases to $0.84 \pm 0.00$ and $0.86 \pm 0.00$, respectively. Prediction results are analyzed both quantitatively and qualitatively and discussed. Based on our findings we propose several directions for future work, and conclude that our proposed model is an important step towards automating the identification and counting of microscopic foraminifera.
Data-Driven Robust Control Using Reinforcement Learning
Apr 16, 2020


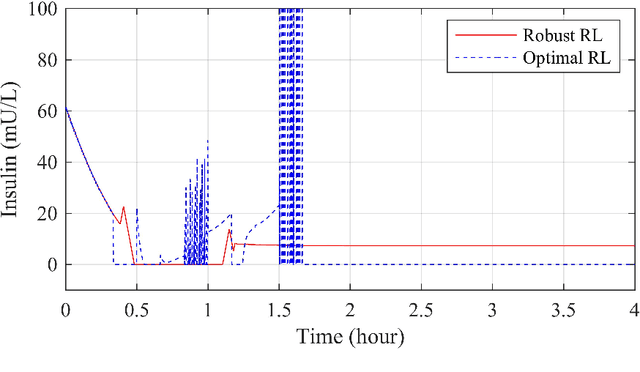
This paper proposes a robust control design method using reinforcement-learning for controlling partially-unknown dynamical systems under uncertain conditions. The method extends the optimal reinforcement-learning algorithm with a new learning technique that is based on the robust control theory. By learning from the data, the algorithm proposed actions that guarantees the stability of the closed loop system within the uncertainties estimated from the data. Control policies are calculated by solving a set of linear matrix inequalities. The controller was evaluated using simulations on a blood glucose model for patients with type-1 diabetes. Simulation results show that the proposed methodology is capable of safely regulates the blood glucose within a healthy level under the influence of measurement and process noises. The controller has also significantly reduced the post-meal fluctuation of the blood glucose. A comparison between the proposed algorithm and the existing optimal reinforcement learning algorithm shows the improved robustness of the closed loop system using our method.
A bag-to-class divergence approach to multiple-instance learning
Oct 12, 2018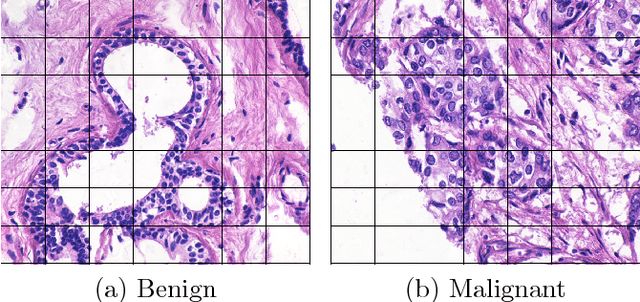
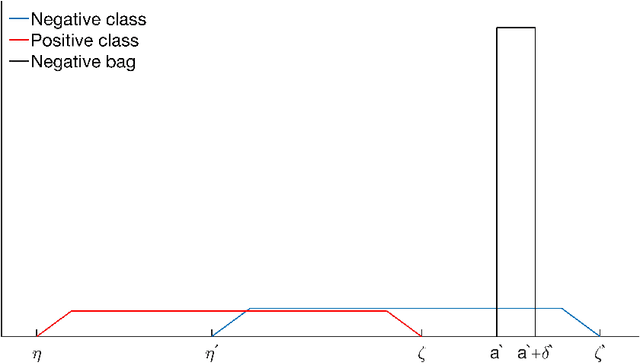
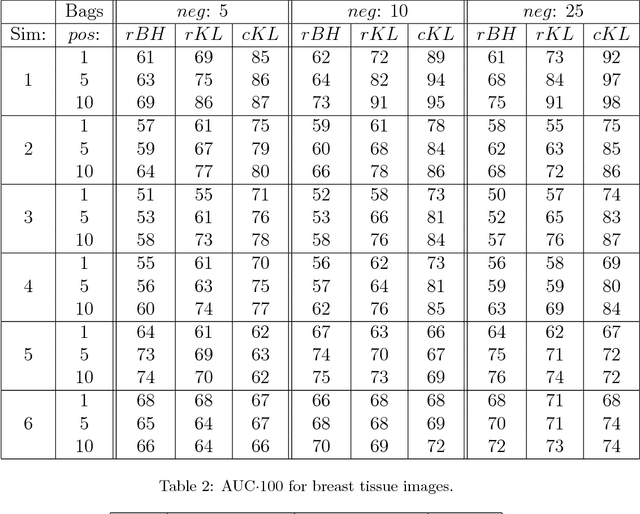
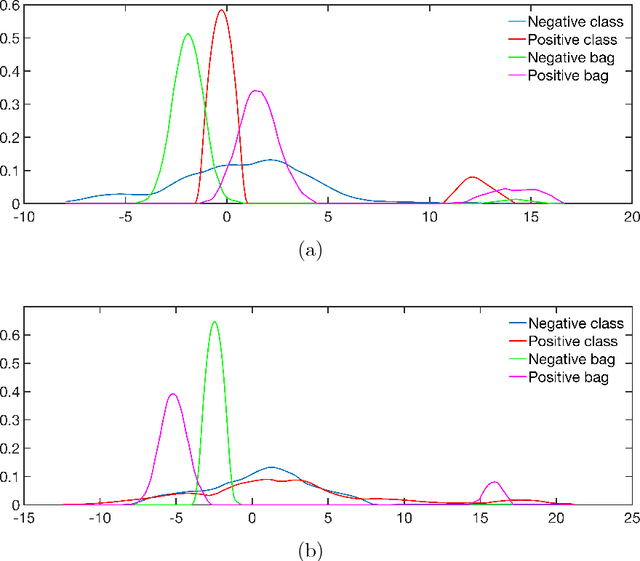
In multi-instance (MI) learning, each object (bag) consists of multiple feature vectors (instances), and is most commonly regarded as a set of points in a multidimensional space. A different viewpoint is that the instances are realisations of random vectors with corresponding probability distribution, and that a bag is the distribution, not the realisations. In MI classification, each bag in the training set has a class label, but the instances are unlabelled. By introducing the probability distribution space to bag-level classification problems, dissimilarities between probability distributions (divergences) can be applied. The bag-to-bag Kullback-Leibler information is asymptotically the best classifier, but the typical sparseness of MI training sets is an obstacle. We introduce bag-to-class divergence to MI learning, emphasising the hierarchical nature of the random vectors that makes bags from the same class different. We propose two properties for bag-to-class divergences, and an additional property for sparse training sets.
Comparison of computer systems and ranking criteria for automatic melanoma detection in dermoscopic images
Feb 05, 2018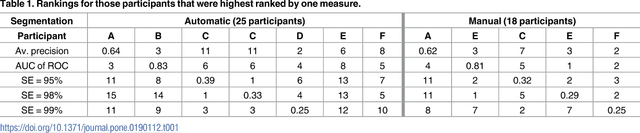
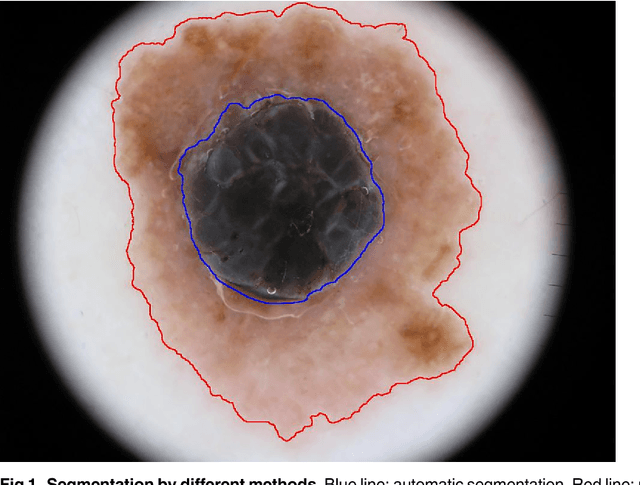
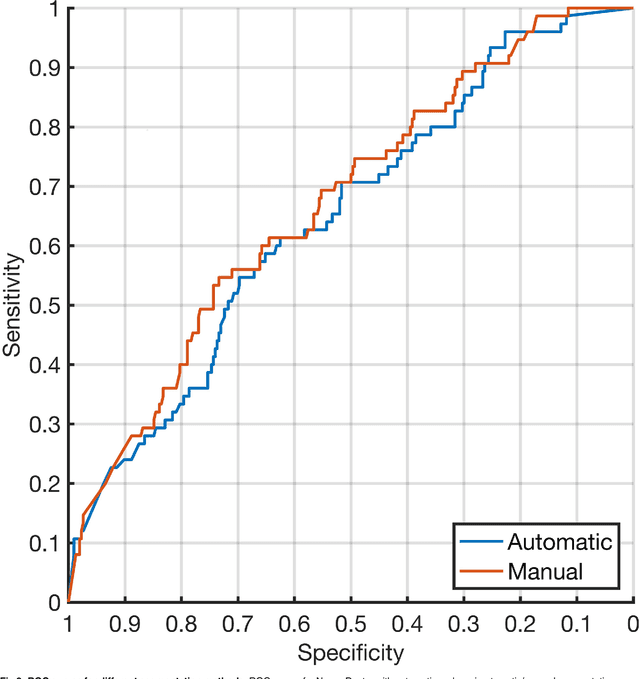
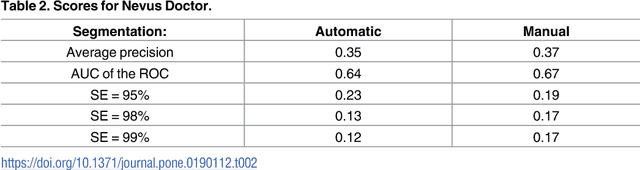
Melanoma is the deadliest form of skin cancer. Computer systems can assist in melanoma detection, but are not widespread in clinical practice. In 2016, an open challenge in classification of dermoscopic images of skin lesions was announced. A training set of 900 images with corresponding class labels and semi-automatic/manual segmentation masks was released for the challenge. An independent test set of 379 images was used to rank the participants. This article demonstrates the impact of ranking criteria, segmentation method and classifier, and highlights the clinical perspective. We compare five different measures for diagnostic accuracy by analysing the resulting ranking of the computer systems in the challenge. Choice of performance measure had great impact on the ranking. Systems that were ranked among the top three for one measure, dropped to the bottom half when changing performance measure. Nevus Doctor, a computer system previously developed by the authors, was used to investigate the impact of segmentation and classifier. The unexpected small impact of automatic versus semi-automatic/manual segmentation suggests that improvements of the automatic segmentation method w.r.t. resemblance to semi-automatic/manual segmentation will not improve diagnostic accuracy substantially. A small set of similar classification algorithms are used to investigate the impact of classifier on the diagnostic accuracy. The variability in diagnostic accuracy for different classifier algorithms was larger than the variability for segmentation methods, and suggests a focus for future investigations. From a clinical perspective, the misclassification of a melanoma as benign has far greater cost than the misclassification of a benign lesion. For computer systems to have clinical impact, their performance should be ranked by a high-sensitivity measure.
On Data-Independent Properties for Density-Based Dissimilarity Measures in Hybrid Clustering
Sep 21, 2016


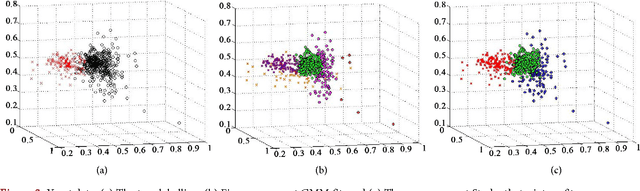
Hybrid clustering combines partitional and hierarchical clustering for computational effectiveness and versatility in cluster shape. In such clustering, a dissimilarity measure plays a crucial role in the hierarchical merging. The dissimilarity measure has great impact on the final clustering, and data-independent properties are needed to choose the right dissimilarity measure for the problem at hand. Properties for distance-based dissimilarity measures have been studied for decades, but properties for density-based dissimilarity measures have so far received little attention. Here, we propose six data-independent properties to evaluate density-based dissimilarity measures associated with hybrid clustering, regarding equality, orthogonality, symmetry, outlier and noise observations, and light-tailed models for heavy-tailed clusters. The significance of the properties is investigated, and we study some well-known dissimilarity measures based on Shannon entropy, misclassification rate, Bhattacharyya distance and Kullback-Leibler divergence with respect to the proposed properties. As none of them satisfy all the proposed properties, we introduce a new dissimilarity measure based on the Kullback-Leibler information and show that it satisfies all proposed properties. The effect of the proposed properties is also illustrated on several real and simulated data sets.