 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalized Information Distance
Sep 15, 2008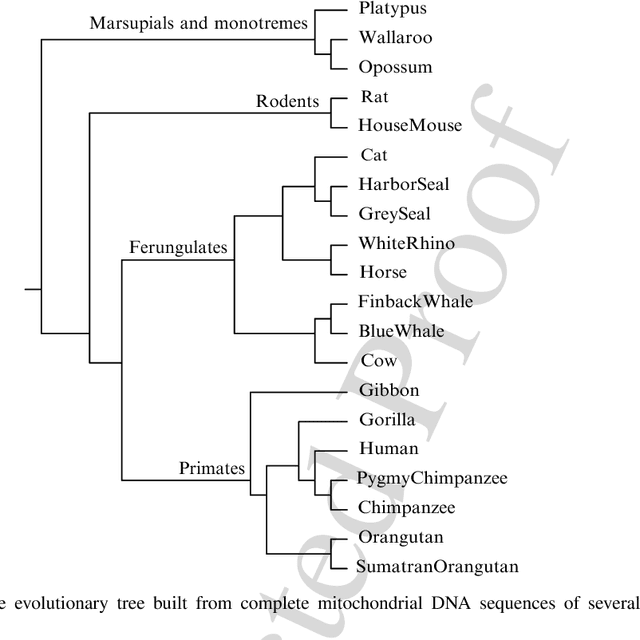
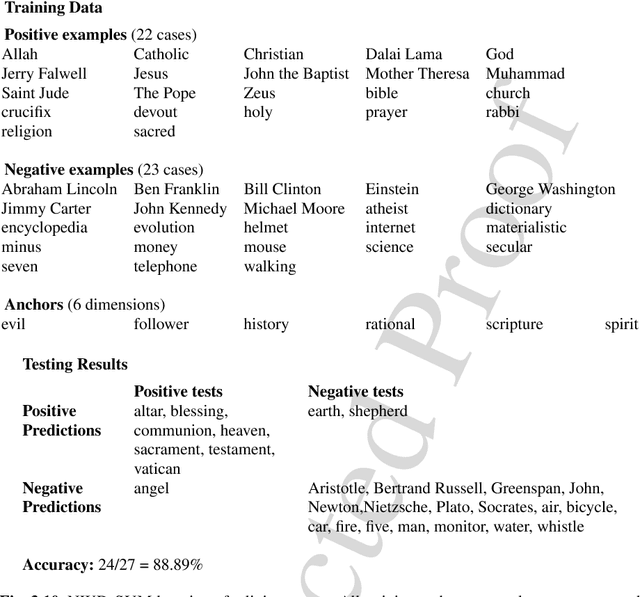
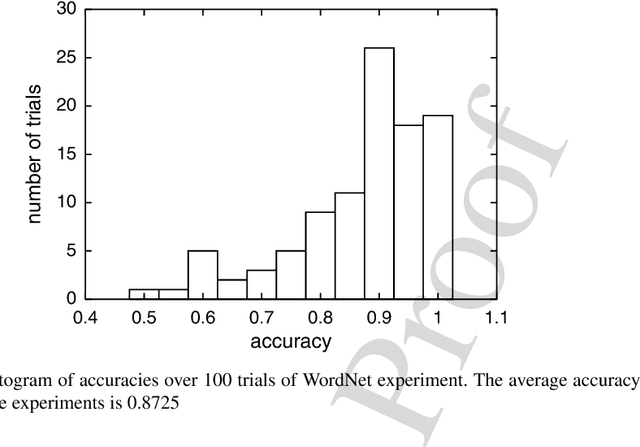

The normalized information distance is a universal distance measure for objects of all kinds. It is based on Kolmogorov complexity and thus uncomputable, but there are ways to utilize it. First, compression algorithms can be used to approximate the Kolmogorov complexity if the objects have a string representation. Second, for names and abstract concepts, page count statistics from the World Wide Web can be used. These practical realizations of the normalized information distance can then be applied to machine learning tasks, expecially clustering, to perform feature-free and parameter-free data mining. This chapter discusses the theoretical foundations of the normalized information distance and both practical realizations. It presents numerous examples of successful real-world applications based on these distance measures, ranging from bioinformatics to music clustering to machine translation.