 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieving Examples from Memory for Retrieval Augmented Neural Machine Translation: A Systematic Comparison
Apr 03, 2024



Retrieval-Augmented Neural Machine Translation (RAMT) architectures retrieve examples from memory to guide the generation process. While most works in this trend explore new ways to exploit the retrieved examples, the upstream retrieval step is mostly unexplored. In this paper, we study the effect of varying retrieval methods for several translation architectures, to better understand the interplay between these two processes. We conduct experiments in two language pairs in a multi-domain setting and consider several downstream architectures based on a standard autoregressive model, an edit-based model, and a large language model with in-context learning. Our experiments show that the choice of the retrieval technique impacts the translation scores, with variance across architectures. We also discuss the effects of increasing the number and diversity of examples, which are mostly positive across the board.
Controlling Utterance Length in NMT-based Word Segmentation with Attention
Oct 18, 2019
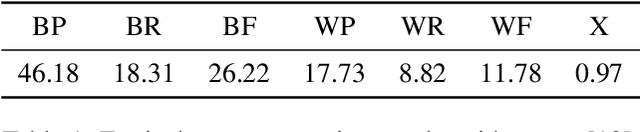


One of the basic tasks of computational language documentation (CLD) is to identify word boundaries in an unsegmented phonemic stream. While several unsupervised monolingual word segmentation algorithms exist in the literature, they are challenged in real-world CLD settings by the small amount of available data. A possible remedy is to take advantage of glosses or translation in a foreign, well-resourced, language, which often exist for such data. In this paper, we explore and compare ways to exploit neural machine translation models to perform unsupervised boundary detection with bilingual information, notably introducing a new loss function for jointly learning alignment and segmentation. We experiment with an actual under-resourced language, Mboshi, and show that these techniques can effectively control the output segmentation length.
Grapheme-to-Phoneme Conversion using Multiple Unbounded Overlapping Chunks
Aug 14, 1996We present in this paper an original extension of two data-driven algorithms for the transcription of a sequence of graphemes into the corresponding sequence of phonemes. In particular, our approach generalizes the algorithm originally proposed by Dedina and Nusbaum (D&N) (1991), which had originally been promoted as a model of the human ability to pronounce unknown words by analogy to familiar lexical items. We will show that DN's algorithm performs comparatively poorly when evaluated on a realistic test set, and that our extension allows us to improve substantially the performance of the analogy-based model. We will also suggest that both algorithms can be reformulated in a much more general framework, which allows us to anticipate other useful extensions. However, considering the inability to define in these models important notions like lexical neighborhood, we conclude that both approaches fail to offer a proper model of the analogical processes involved in reading aloud.