 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Utterance Length in NMT-based Word Segmentation with Attention
Paper and Code

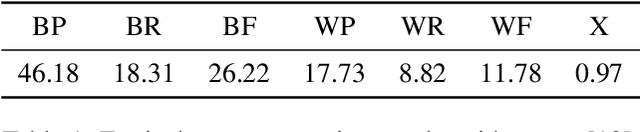


One of the basic tasks of computational language documentation (CLD) is to identify word boundaries in an unsegmented phonemic stream. While several unsupervised monolingual word segmentation algorithms exist in the literature, they are challenged in real-world CLD settings by the small amount of available data. A possible remedy is to take advantage of glosses or translation in a foreign, well-resourced, language, which often exist for such data. In this paper, we explore and compare ways to exploit neural machine translation models to perform unsupervised boundary detection with bilingual information, notably introducing a new loss function for jointly learning alignment and segmentation. We experiment with an actual under-resourced language, Mboshi, and show that these techniques can effectively control the output segmentation length.