 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAERMA: Stacked Autoencoder Rule Mining Algorithm for the Interpretation of Epistatic Interactions in GWAS for Extreme Obesity
Aug 27, 2019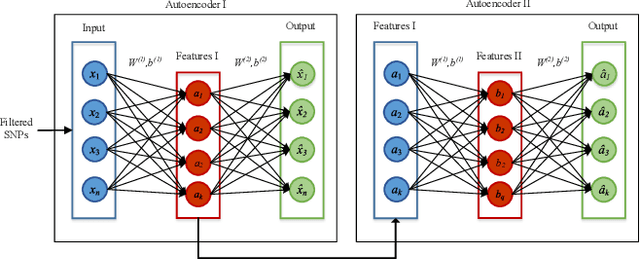
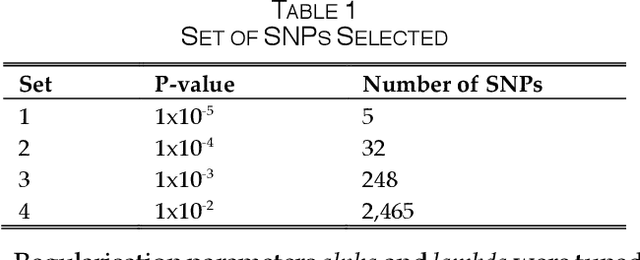
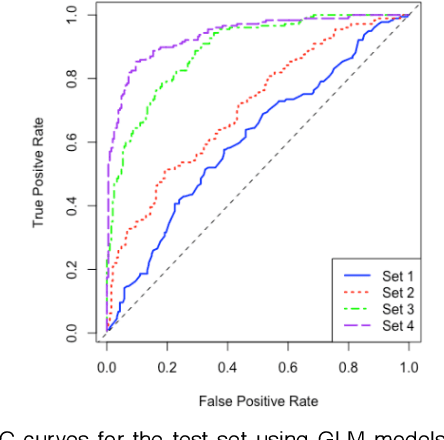
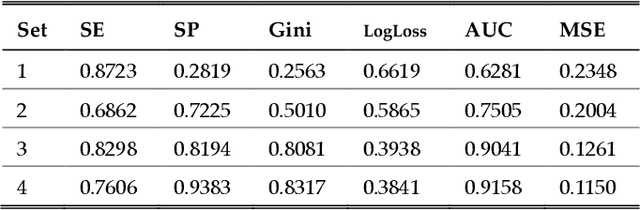
One of the most important challenges in the analysis of high-throughput genetic data is the development of efficient computational methods to identify statistically significant Single Nucleotide Polymorphisms (SNPs). Genome-wide association studies (GWAS) use single-locus analysis where each SNP is independently tested for association with phenotypes. The limitation with this approach, however, is its inability to explain genetic variation in complex diseases. Alternative approaches are required to model the intricate relationships between SNPs. Our proposed approach extends GWAS by combining deep learning stacked autoencoders (SAEs) and association rule mining (ARM) to identify epistatic interactions between SNPs. Following traditional GWAS quality control and association analysis, the most significant SNPs are selected and used in the subsequent analysis to investigate epistasis. SAERMA controls the classification results produced in the final fully connected multi-layer feedforward artificial neural network (MLP) by manipulating the interestingness measures, support and confidence, in the rule generation process. The best classification results were achieved with 204 SNPs compressed to 100 units (77% AUC, 77% SE, 68% SP, 53% Gini, logloss=0.58, and MSE=0.20), although it was possible to achieve 73% AUC (77% SE, 63% SP, 45% Gini, logloss=0.62, and MSE=0.21) with 50 hidden units - both supported by close model interpretation.
Structure-Based Networks for Drug Validation
Nov 21, 2018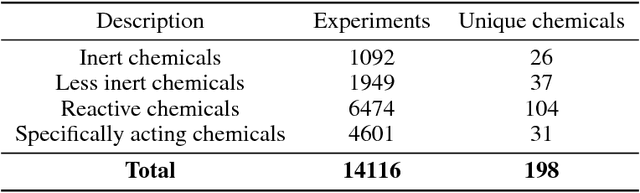


Classifying chemicals according to putative modes of action (MOAs) is of paramount importance in the context of risk assessment. However, current methods are only able to handle a very small proportion of the existing chemicals. We address this issue by proposing an integrative deep learning architecture that learns a joint representation from molecular structures of drugs and their effects on human cells. Our choice of architecture is motivated by the significant influence of a drug's chemical structure on its MOA. We improve on the strong ability of a unimodal architecture (F1 score of 0.803) to classify drugs by their toxic MOAs (Verhaar scheme) through adding another learning stream that processes transcriptional responses of human cells affected by drugs. Our integrative model achieves an even higher classification performance on the LINCS L1000 dataset - the error is reduced by 4.6%. We believe that our method can be used to extend the current Verhaar scheme and constitute a basis for fast drug validation and risk assessment.