 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaking advantage of a very simple property to efficiently infer NFAs
Mar 16, 2023Grammatical inference consists in learning a formal grammar as a finite state machine or as a set of rewrite rules. In this paper, we are concerned with inferring Nondeterministic Finite Automata (NFA) that must accept some words, and reject some other words from a given sample. This problem can naturally be modeled in SAT. The standard model being enormous, some models based on prefixes, suffixes, and hybrids were designed to generate smaller SAT instances. There is a very simple and obvious property that says: if there is an NFA of size k for a given sample, there is also an NFA of size k+1. We first strengthen this property by adding some characteristics to the NFA of size k+1. Hence, we can use this property to tighten the bounds of the size of the minimal NFA for a given sample. We then propose simplified and refined models for NFA of size k+1 that are smaller than the initial models for NFA of size k. We also propose a reduction algorithm to build an NFA of size k from a specific NFA of size k+1. Finally, we validate our proposition with some experimentation that shows the efficiency of our approach.
A two-stage approach for table extraction in invoices
Oct 10, 2022
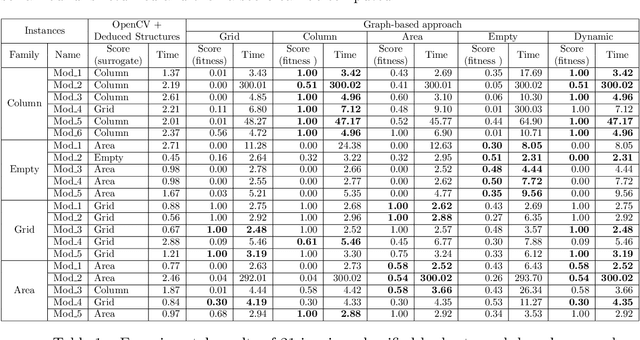

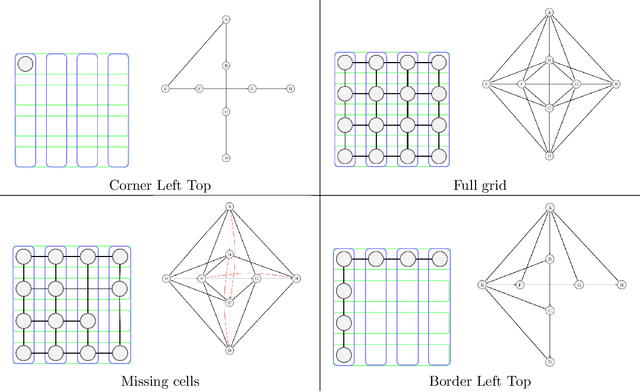
The automated analysis of administrative documents is an important field in document recognition that is studied for decades. Invoices are key documents among these huge amounts of documents available in companies and public services. Invoices contain most of the time data that are presented in tables that should be clearly identified to extract suitable information. In this paper, we propose an approach that combines an image processing based estimation of the shape of the tables with a graph-based representation of the document, which is used to identify complex tables precisely. We propose an experimental evaluation using a real case application.
A Computational Model for Logical Analysis of Data
Jul 12, 2022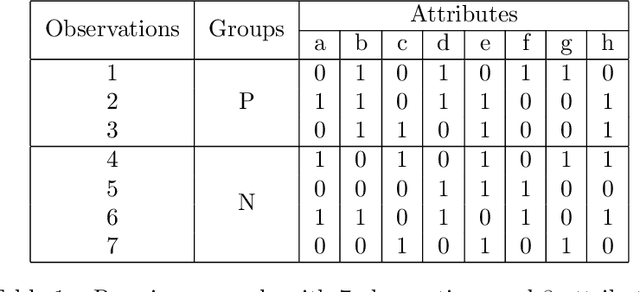
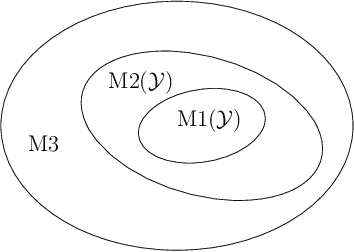
Initially introduced by Peter Hammer, Logical Analysis of Data is a methodology that aims at computing a logical justification for dividing a group of data in two groups of observations, usually called the positive and negative groups. Consider this partition into positive and negative groups as the description of a partially defined Boolean function; the data is then processed to identify a subset of attributes, whose values may be used to characterize the observations of the positive groups against those of the negative group. LAD constitutes an interesting rule-based learning alternative to classic statistical learning techniques and has many practical applications. Nevertheless, the computation of group characterization may be costly, depending on the properties of the data instances. A major aim of our work is to provide effective tools for speeding up the computations, by computing some \emph{a priori} probability that a given set of attributes does characterize the positive and negative groups. To this effect, we propose several models for representing the data set of observations, according to the information we have on it. These models, and the probabilities they allow us to compute, are also helpful for quickly assessing some properties of the real data at hand; furthermore they may help us to better analyze and understand the computational difficulties encountered by solving methods. Once our models have been established, the mathematical tools for computing probabilities come from Analytic Combinatorics. They allow us to express the desired probabilities as ratios of generating functions coefficients, which then provide a quick computation of their numerical values. A further, long-range goal of this paper is to show that the methods of Analytic Combinatorics can help in analyzing the performance of various algorithms in LAD and related fields.
Improved SAT models for NFA learning
Jul 13, 2021
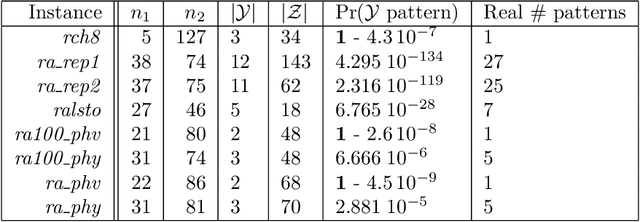
Grammatical inference is concerned with the study of algorithms for learning automata and grammars from words. We focus on learning Nondeterministic Finite Automaton of size k from samples of words. To this end, we formulate the problem as a SAT model. The generated SAT instances being enormous, we propose some model improvements, both in terms of the number of variables, the number of clauses, and clauses size. These improvements significantly reduce the instances, but at the cost of longer generation time. We thus try to balance instance size vs. generation and solving time. We also achieved some experimental comparisons and we analyzed our various model improvements.
GA and ILS for optimizing the size of NFA models
Jul 13, 2021


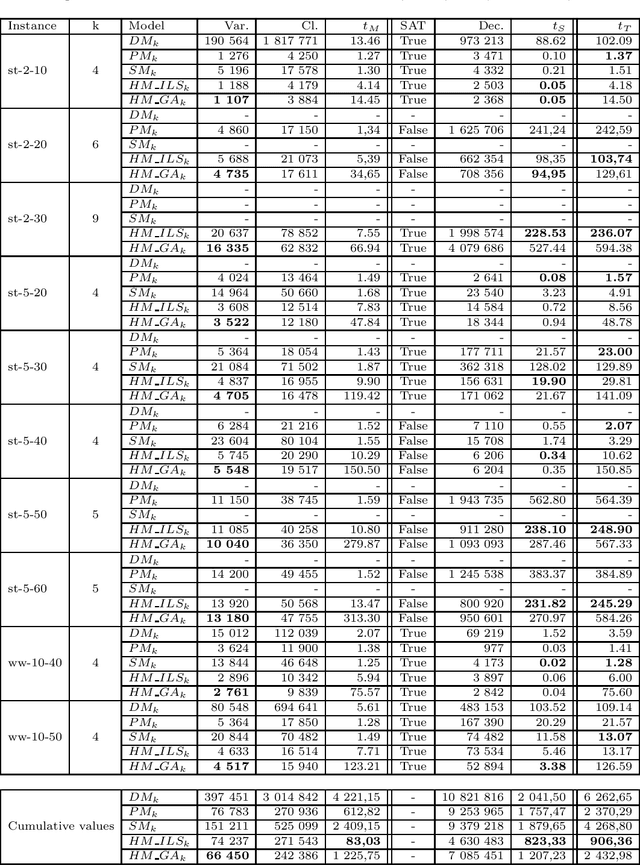
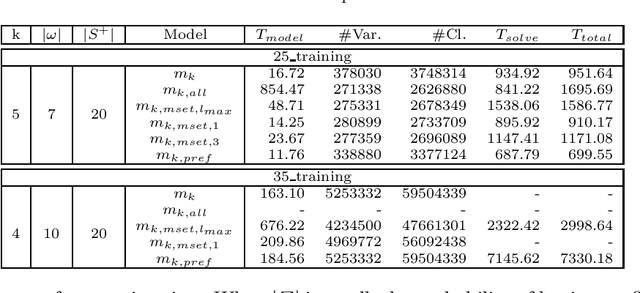
Grammatical inference consists in learning a formal grammar (as a set of rewrite rules or a finite state machine). We are concerned with learning Nondeterministic Finite Automata (NFA) of a given size from samples of positive and negative words. NFA can naturally be modeled in SAT. The standard model [1] being enormous, we also try a model based on prefixes [2] which generates smaller instances. We also propose a new model based on suffixes and a hybrid model based on prefixes and suffixes. We then focus on optimizing the size of generated SAT instances issued from the hybrid models. We present two techniques to optimize this combination, one based on Iterated Local Search (ILS), the second one based on Genetic Algorithm (GA). Optimizing the combination significantly reduces the SAT instances and their solving time, but at the cost of longer generation time. We, therefore, study the balance between generation time and solving time thanks to some experimental comparisons, and we analyze our various model improvements.
An Experimental Study of Adaptive Control for Evolutionary Algorithms
Sep 05, 2014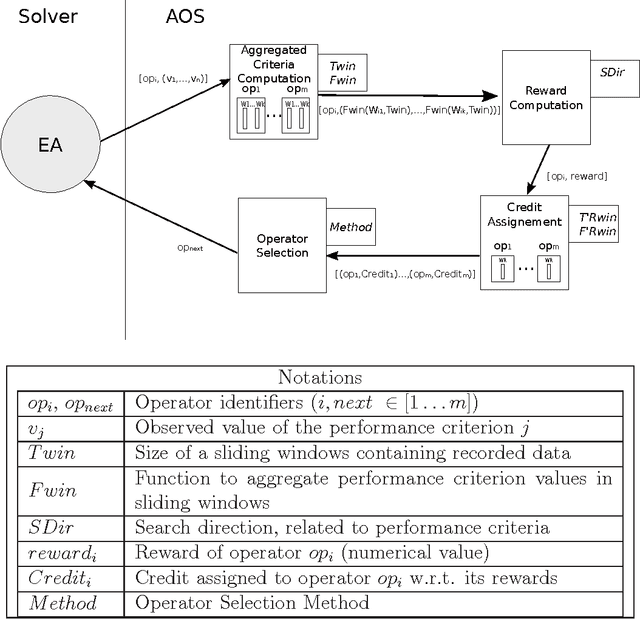
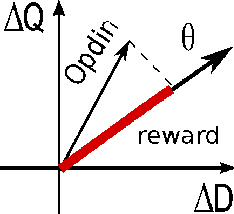

The balance of exploration versus exploitation (EvE) is a key issue on evolutionary computation. In this paper we will investigate how an adaptive controller aimed to perform Operator Selection can be used to dynamically manage the EvE balance required by the search, showing that the search strategies determined by this control paradigm lead to an improvement of solution quality found by the evolutionary algorithm.
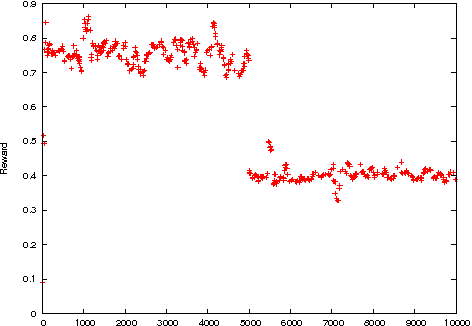
Simulating Non Stationary Operators in Search Algorithms
Sep 05, 2014


In this paper, we propose a model for simulating search operators whose behaviour often changes continuously during the search. In these scenarios, the performance of the operators decreases when they are applied. This is motivated by the fact that operators for optimization problems are often roughly classified into exploitation operators and exploration operators. Our simulation model is used to compare the different performances of operator selection policies and clearly identify their ability to adapt to such specific operators behaviours. The experimental study provides interesting results on the respective behaviours of operator selection policies when faced to such non stationary search scenarios.
Set Constraint Model and Automated Encoding into SAT: Application to the Social Golfer Problem
Jun 30, 2014
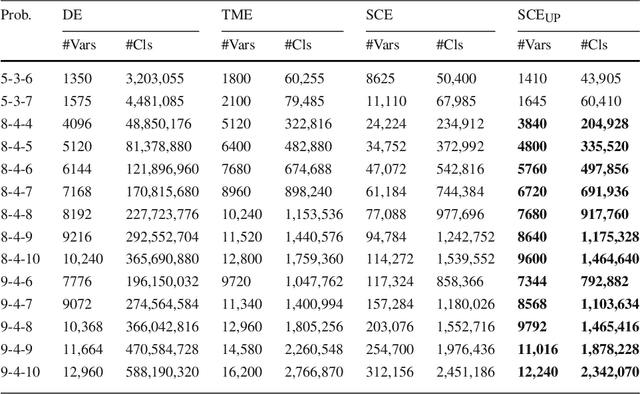
On the one hand, Constraint Satisfaction Problems allow one to declaratively model problems. On the other hand, propositional satisfiability problem (SAT) solvers can handle huge SAT instances. We thus present a technique to declaratively model set constraint problems and to encode them automatically into SAT instances. We apply our technique to the Social Golfer Problem and we also use it to break symmetries of the problem. Our technique is simpler, more declarative, and less error-prone than direct and improved hand modeling. The SAT instances that we automatically generate contain less clauses than improved hand-written instances such as in [20], and with unit propagation they also contain less variables. Moreover, they are well-suited for SAT solvers and they are solved faster as shown when solving difficult instances of the Social Golfer Problem.