 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Computational Model for Logical Analysis of Data
Paper and Code
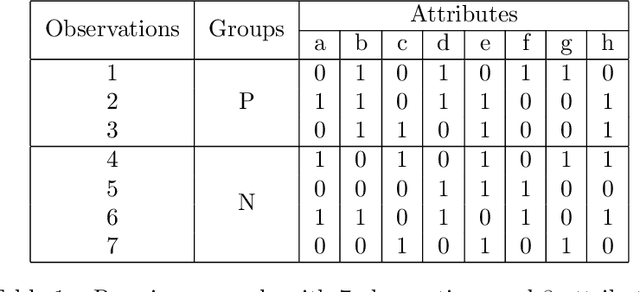
Initially introduced by Peter Hammer, Logical Analysis of Data is a methodology that aims at computing a logical justification for dividing a group of data in two groups of observations, usually called the positive and negative groups. Consider this partition into positive and negative groups as the description of a partially defined Boolean function; the data is then processed to identify a subset of attributes, whose values may be used to characterize the observations of the positive groups against those of the negative group. LAD constitutes an interesting rule-based learning alternative to classic statistical learning techniques and has many practical applications. Nevertheless, the computation of group characterization may be costly, depending on the properties of the data instances. A major aim of our work is to provide effective tools for speeding up the computations, by computing some \emph{a priori} probability that a given set of attributes does characterize the positive and negative groups. To this effect, we propose several models for representing the data set of observations, according to the information we have on it. These models, and the probabilities they allow us to compute, are also helpful for quickly assessing some properties of the real data at hand; furthermore they may help us to better analyze and understand the computational difficulties encountered by solving methods. Once our models have been established, the mathematical tools for computing probabilities come from Analytic Combinatorics. They allow us to express the desired probabilities as ratios of generating functions coefficients, which then provide a quick computation of their numerical values. A further, long-range goal of this paper is to show that the methods of Analytic Combinatorics can help in analyzing the performance of various algorithms in LAD and related fields.