 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePix2Point: Learning Outdoor 3D Using Sparse Point Clouds and Optimal Transport
Jul 30, 2021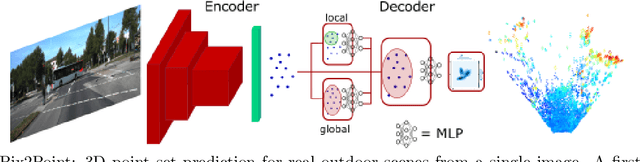
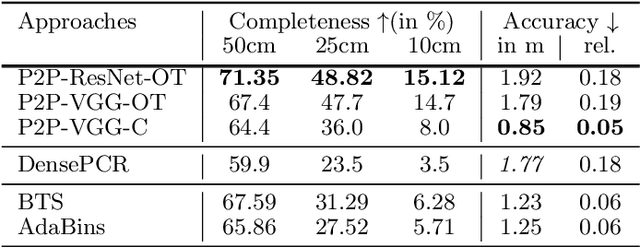
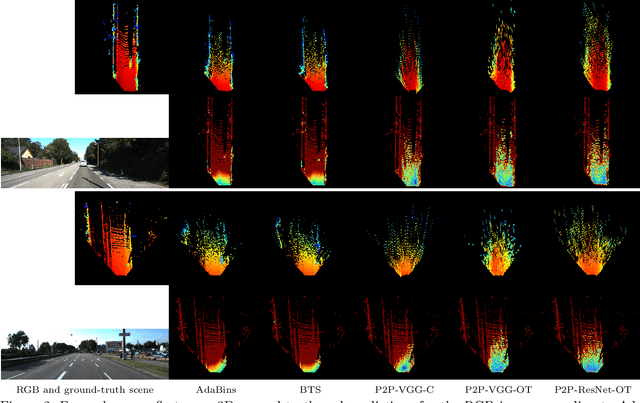
Good quality reconstruction and comprehension of a scene rely on 3D estimation methods. The 3D information was usually obtained from images by stereo-photogrammetry, but deep learning has recently provided us with excellent results for monocular depth estimation. Building up a sufficiently large and rich training dataset to achieve these results requires onerous processing. In this paper, we address the problem of learning outdoor 3D point cloud from monocular data using a sparse ground-truth dataset. We propose Pix2Point, a deep learning-based approach for monocular 3D point cloud prediction, able to deal with complete and challenging outdoor scenes. Our method relies on a 2D-3D hybrid neural network architecture, and a supervised end-to-end minimisation of an optimal transport divergence between point clouds. We show that, when trained on sparse point clouds, our simple promising approach achieves a better coverage of 3D outdoor scenes than efficient monocular depth methods.
Multi-Task Learning of Height and Semantics from Aerial Images
Nov 18, 2019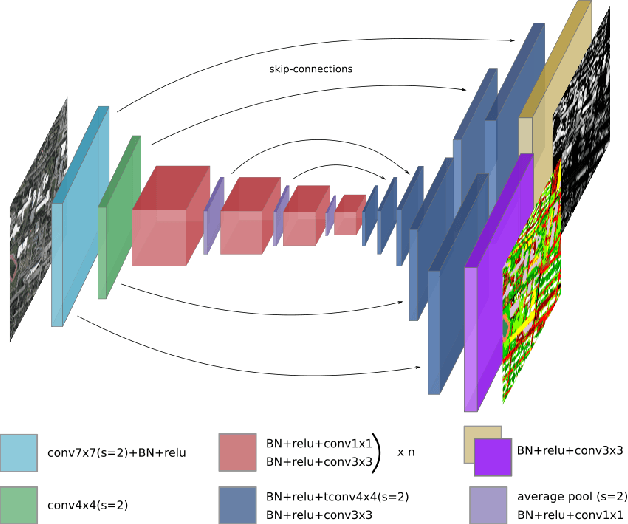
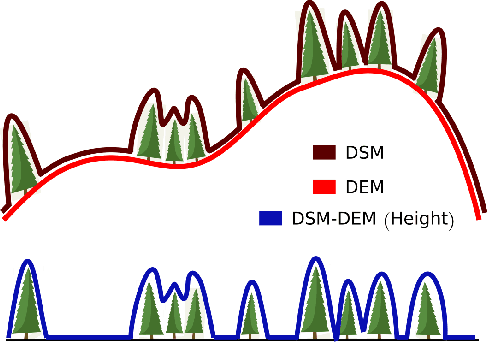
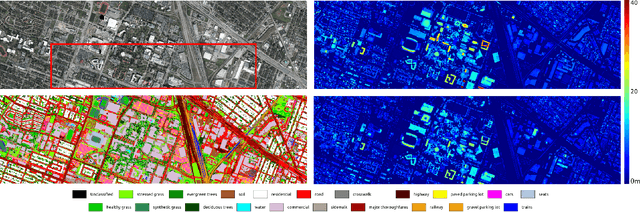

Aerial or satellite imagery is a great source for land surface analysis, which might yield land use maps or elevation models. In this investigation, we present a neural network framework for learning semantics and local height together. We show how this joint multi-task learning benefits to each task on the large dataset of the 2018 Data Fusion Contest. Moreover, our framework also yields an uncertainty map which allows assessing the prediction of the model. Code is available at https://github.com/marcelampc/mtl_aerial_images .
Deep Depth from Defocus: how can defocus blur improve 3D estimation using dense neural networks?
Sep 06, 2018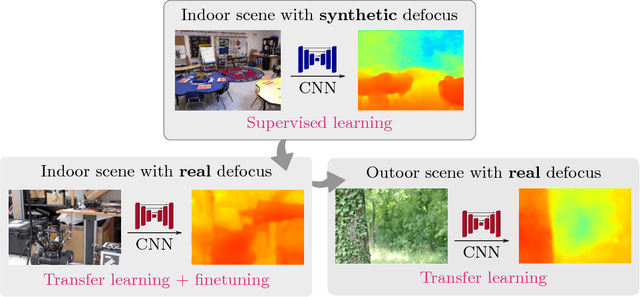
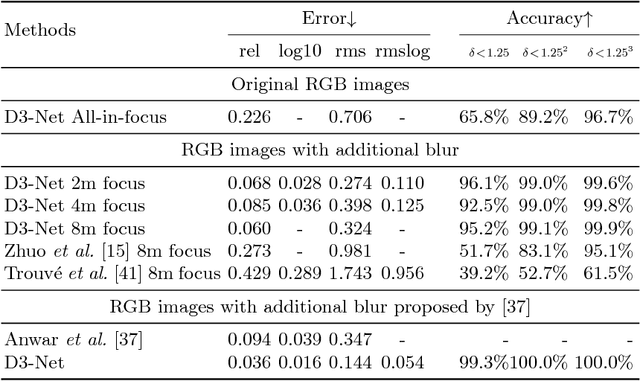
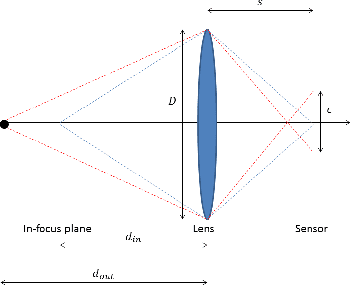

Depth estimation is of critical interest for scene understanding and accurate 3D reconstruction. Most recent approaches in depth estimation with deep learning exploit geometrical structures of standard sharp images to predict corresponding depth maps. However, cameras can also produce images with defocus blur depending on the depth of the objects and camera settings. Hence, these features may represent an important hint for learning to predict depth. In this paper, we propose a full system for single-image depth prediction in the wild using depth-from-defocus and neural networks. We carry out thorough experiments to test deep convolutional networks on real and simulated defocused images using a realistic model of blur variation with respect to depth. We also investigate the influence of blur on depth prediction observing model uncertainty with a Bayesian neural network approach. From these studies, we show that out-of-focus blur greatly improves the depth-prediction network performances. Furthermore, we transfer the ability learned on a synthetic, indoor dataset to real, indoor and outdoor images. For this purpose, we present a new dataset containing real all-focus and defocused images from a Digital Single-Lens Reflex (DSLR) camera, paired with ground truth depth maps obtained with an active 3D sensor for indoor scenes. The proposed approach is successfully validated on both this new dataset and standard ones as NYUv2 or Depth-in-the-Wild. Code and new datasets are available at https://github.com/marcelampc/d3net_depth_estimation