 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Domain Generalization Algorithms in Computational Pathology
Sep 25, 2024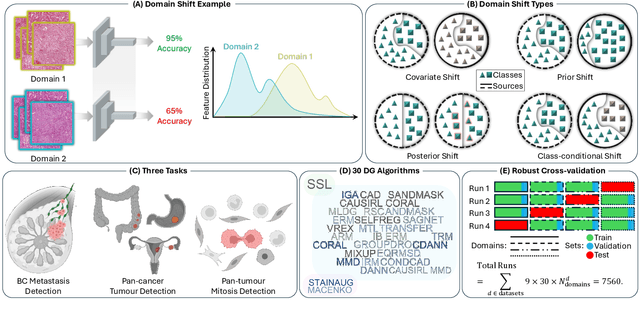
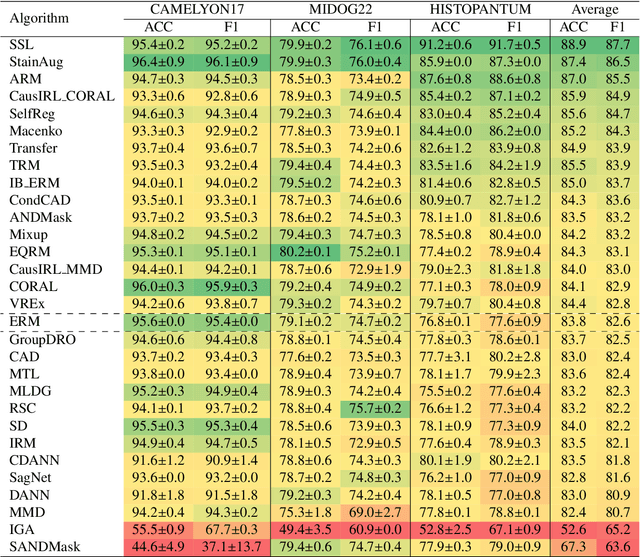
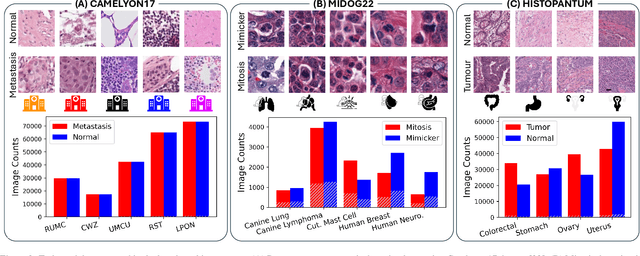
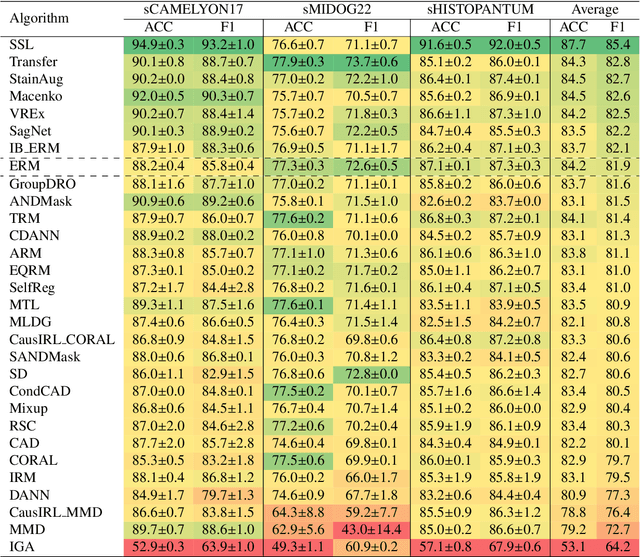
Deep learning models have shown immense promise in computational pathology (CPath) tasks, but their performance often suffers when applied to unseen data due to domain shifts. Addressing this requires domain generalization (DG) algorithms. However, a systematic evaluation of DG algorithms in the CPath context is lacking. This study aims to benchmark the effectiveness of 30 DG algorithms on 3 CPath tasks of varying difficulty through 7,560 cross-validation runs. We evaluate these algorithms using a unified and robust platform, incorporating modality-specific techniques and recent advances like pretrained foundation models. Our extensive cross-validation experiments provide insights into the relative performance of various DG strategies. We observe that self-supervised learning and stain augmentation consistently outperform other methods, highlighting the potential of pretrained models and data augmentation. Furthermore, we introduce a new pan-cancer tumor detection dataset (HISTOPANTUM) as a benchmark for future research. This study offers valuable guidance to researchers in selecting appropriate DG approaches for CPath tasks.