 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Recurrent Network Topologies for Dynamical Systems Reconstruction
Jun 07, 2024



In dynamical systems reconstruction (DSR) we seek to infer from time series measurements a generative model of the underlying dynamical process. This is a prime objective in any scientific discipline, where we are particularly interested in parsimonious models with a low parameter load. A common strategy here is parameter pruning, removing all parameters with small weights. However, here we find this strategy does not work for DSR, where even low magnitude parameters can contribute considerably to the system dynamics. On the other hand, it is well known that many natural systems which generate complex dynamics, like the brain or ecological networks, have a sparse topology with comparatively few links. Inspired by this, we show that geometric pruning, where in contrast to magnitude-based pruning weights with a low contribution to an attractor's geometrical structure are removed, indeed manages to reduce parameter load substantially without significantly hampering DSR quality. We further find that the networks resulting from geometric pruning have a specific type of topology, and that this topology, and not the magnitude of weights, is what is most crucial to performance. We provide an algorithm that automatically generates such topologies which can be used as priors for generative modeling of dynamical systems by RNNs, and compare it to other well studied topologies like small-world or scale-free networks.
Out-of-Domain Generalization in Dynamical Systems Reconstruction
Feb 28, 2024



In science we are interested in finding the governing equations, the dynamical rules, underlying empirical phenomena. While traditionally scientific models are derived through cycles of human insight and experimentation, recently deep learning (DL) techniques have been advanced to reconstruct dynamical systems (DS) directly from time series data. State-of-the-art dynamical systems reconstruction (DSR) methods show promise in capturing invariant and long-term properties of observed DS, but their ability to generalize to unobserved domains remains an open challenge. Yet, this is a crucial property we would expect from any viable scientific theory. In this work, we provide a formal framework that addresses generalization in DSR. We explain why and how out-of-domain (OOD) generalization (OODG) in DSR profoundly differs from OODG considered elsewhere in machine learning. We introduce mathematical notions based on topological concepts and ergodic theory to formalize the idea of learnability of a DSR model. We formally prove that black-box DL techniques, without adequate structural priors, generally will not be able to learn a generalizing DSR model. We also show this empirically, considering major classes of DSR algorithms proposed so far, and illustrate where and why they fail to generalize across the whole phase space. Our study provides the first comprehensive mathematical treatment of OODG in DSR, and gives a deeper conceptual understanding of where the fundamental problems in OODG lie and how they could possibly be addressed in practice.
Generalized Teacher Forcing for Learning Chaotic Dynamics
Jun 07, 2023



Chaotic dynamical systems (DS) are ubiquitous in nature and society. Often we are interested in reconstructing such systems from observed time series for prediction or mechanistic insight, where by reconstruction we mean learning geometrical and invariant temporal properties of the system in question (like attractors). However, training reconstruction algorithms like recurrent neural networks (RNNs) on such systems by gradient-descent based techniques faces severe challenges. This is mainly due to exploding gradients caused by the exponential divergence of trajectories in chaotic systems. Moreover, for (scientific) interpretability we wish to have as low dimensional reconstructions as possible, preferably in a model which is mathematically tractable. Here we report that a surprisingly simple modification of teacher forcing leads to provably strictly all-time bounded gradients in training on chaotic systems, and, when paired with a simple architectural rearrangement of a tractable RNN design, piecewise-linear RNNs (PLRNNs), allows for faithful reconstruction in spaces of at most the dimensionality of the observed system. We show on several DS that with these amendments we can reconstruct DS better than current SOTA algorithms, in much lower dimensions. Performance differences were particularly compelling on real world data with which most other methods severely struggled. This work thus led to a simple yet powerful DS reconstruction algorithm which is highly interpretable at the same time.
Tractable Dendritic RNNs for Reconstructing Nonlinear Dynamical Systems
Jul 06, 2022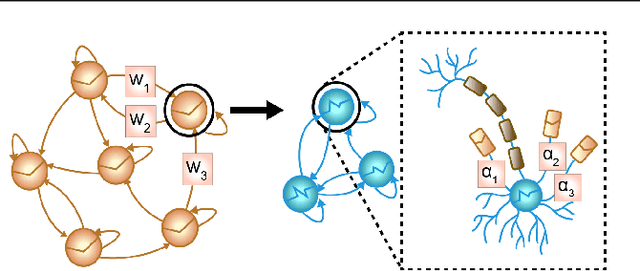
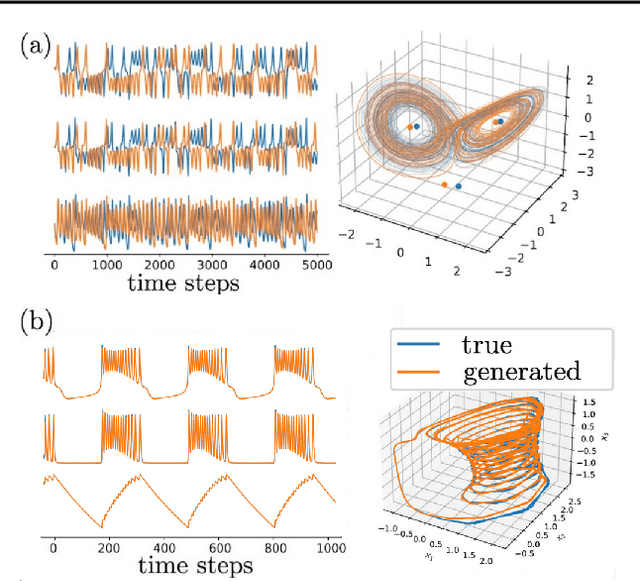
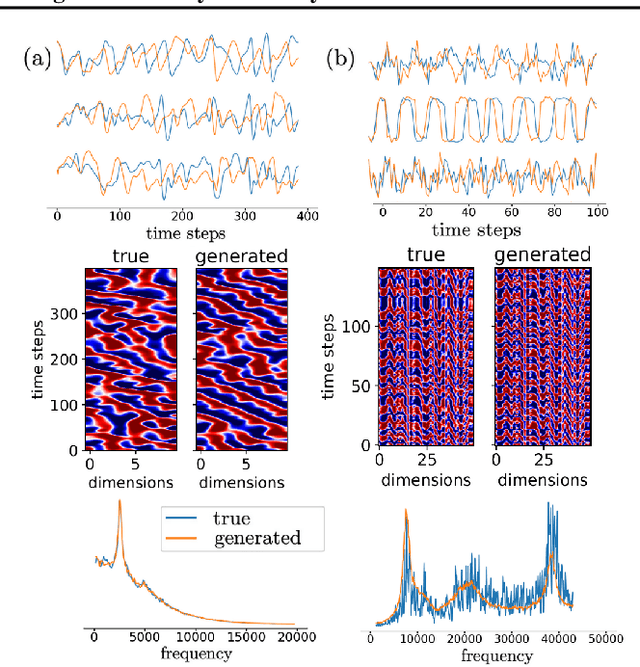
In many scientific disciplines, we are interested in inferring the nonlinear dynamical system underlying a set of observed time series, a challenging task in the face of chaotic behavior and noise. Previous deep learning approaches toward this goal often suffered from a lack of interpretability and tractability. In particular, the high-dimensional latent spaces often required for a faithful embedding, even when the underlying dynamics lives on a lower-dimensional manifold, can hamper theoretical analysis. Motivated by the emerging principles of dendritic computation, we augment a dynamically interpretable and mathematically tractable piecewise-linear (PL) recurrent neural network (RNN) by a linear spline basis expansion. We show that this approach retains all the theoretically appealing properties of the simple PLRNN, yet boosts its capacity for approximating arbitrary nonlinear dynamical systems in comparatively low dimensions. We employ two frameworks for training the system, one combining back-propagation-through-time (BPTT) with teacher forcing, and another based on fast and scalable variational inference. We show that the dendritically expanded PLRNN achieves better reconstructions with fewer parameters and dimensions on various dynamical systems benchmarks and compares favorably to other methods, while retaining a tractable and interpretable structure.