 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOfCaM: Global Human Mesh Recovery via Optimization-free Camera Motion Scale Calibration
Jun 30, 2024Accurate camera motion estimation is critical to estimate human motion in the global space. A standard and widely used method for estimating camera motion is Simultaneous Localization and Mapping (SLAM). However, SLAM only provides a trajectory up to an unknown scale factor. Different from previous attempts that optimize the scale factor, this paper presents Optimization-free Camera Motion Scale Calibration (OfCaM), a novel framework that utilizes prior knowledge from human mesh recovery (HMR) models to directly calibrate the unknown scale factor. Specifically, OfCaM leverages the absolute depth of human-background contact joints from HMR predictions as a calibration reference, enabling the precise recovery of SLAM camera trajectory scale in global space. With this correctly scaled camera motion and HMR's local motion predictions, we achieve more accurate global human motion estimation. To compensate for scenes where we detect SLAM failure, we adopt a local-to-global motion mapping to fuse with previously derived motion to enhance robustness. Simple yet powerful, our method sets a new standard for global human mesh estimation tasks, reducing global human motion error by 60% over the prior SOTA while also demanding orders of magnitude less inference time compared with optimization-based methods.
KITRO: Refining Human Mesh by 2D Clues and Kinematic-tree Rotation
May 30, 2024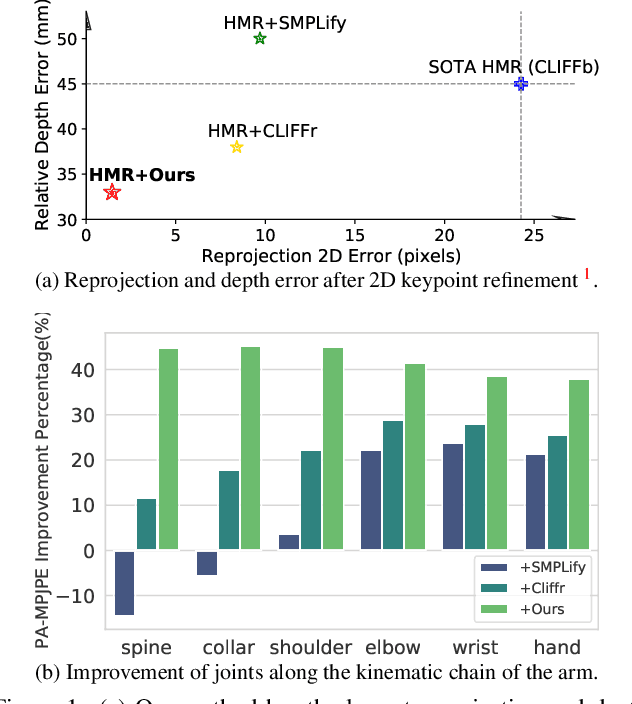

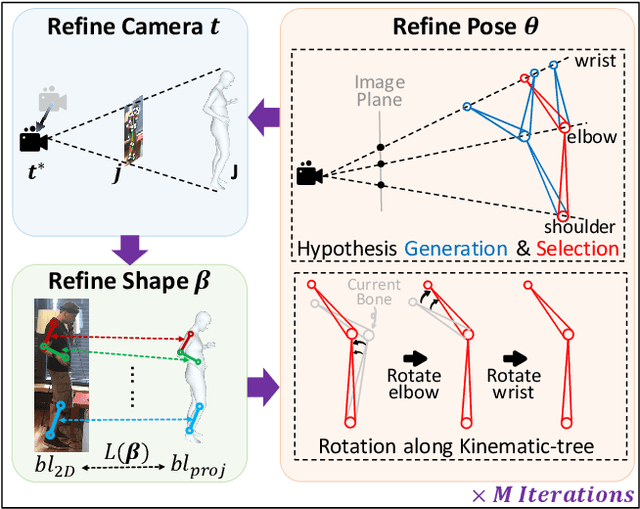
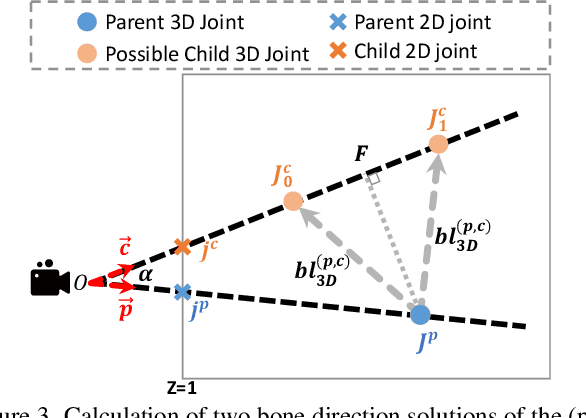
2D keypoints are commonly used as an additional cue to refine estimated 3D human meshes. Current methods optimize the pose and shape parameters with a reprojection loss on the provided 2D keypoints. Such an approach, while simple and intuitive, has limited effectiveness because the optimal solution is hard to find in ambiguous parameter space and may sacrifice depth. Additionally, divergent gradients from distal joints complicate and deviate the refinement of proximal joints in the kinematic chain. To address these, we introduce Kinematic-Tree Rotation (KITRO), a novel mesh refinement strategy that explicitly models depth and human kinematic-tree structure. KITRO treats refinement from a bone-wise perspective. Unlike previous methods which perform gradient-based optimizations, our method calculates bone directions in closed form. By accounting for the 2D pose, bone length, and parent joint's depth, the calculation results in two possible directions for each child joint. We then use a decision tree to trace binary choices for all bones along the human skeleton's kinematic-tree to select the most probable hypothesis. Our experiments across various datasets and baseline models demonstrate that KITRO significantly improves 3D joint estimation accuracy and achieves an ideal 2D fit simultaneously. Our code available at: https://github.com/MartaYang/KITRO.
SEGA: Semantic Guided Attention on Visual Prototype for Few-Shot Learning
Nov 08, 2021



Teaching machines to recognize a new category based on few training samples especially only one remains challenging owing to the incomprehensive understanding of the novel category caused by the lack of data. However, human can learn new classes quickly even given few samples since human can tell what discriminative features should be focused on about each category based on both the visual and semantic prior knowledge. To better utilize those prior knowledge, we propose the SEmantic Guided Attention (SEGA) mechanism where the semantic knowledge is used to guide the visual perception in a top-down manner about what visual features should be paid attention to when distinguishing a category from the others. As a result, the embedding of the novel class even with few samples can be more discriminative. Concretely, a feature extractor is trained to embed few images of each novel class into a visual prototype with the help of transferring visual prior knowledge from base classes. Then we learn a network that maps semantic knowledge to category-specific attention vectors which will be used to perform feature selection to enhance the visual prototypes. Extensive experiments on miniImageNet, tieredImageNet, CIFAR-FS, and CUB indicate that our semantic guided attention realizes anticipated function and outperforms state-of-the-art results.