 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolCLIP: A Molecular-Auxiliary CLIP Framework for Identifying Drug Mechanism of Action Based on Time-Lapsed Mitochondrial Images
Jul 10, 2025



Drug Mechanism of Action (MoA) mainly investigates how drug molecules interact with cells, which is crucial for drug discovery and clinical application. Recently, deep learning models have been used to recognize MoA by relying on high-content and fluorescence images of cells exposed to various drugs. However, these methods focus on spatial characteristics while overlooking the temporal dynamics of live cells. Time-lapse imaging is more suitable for observing the cell response to drugs. Additionally, drug molecules can trigger cellular dynamic variations related to specific MoA. This indicates that the drug molecule modality may complement the image counterpart. This paper proposes MolCLIP, the first visual language model to combine microscopic cell video- and molecule-modalities. MolCLIP designs a molecule-auxiliary CLIP framework to guide video features in learning the distribution of the molecular latent space. Furthermore, we integrate a metric learning strategy with MolCLIP to optimize the aggregation of video features. Experimental results on the MitoDataset demonstrate that MolCLIP achieves improvements of 51.2% and 20.5% in mAP for drug identification and MoA recognition, respectively.
Positive-unlabeled learning for binary and multi-class cell detection in histopathology images with incomplete annotations
Feb 16, 2023Cell detection in histopathology images is of great interest to clinical practice and research, and convolutional neural networks (CNNs) have achieved remarkable cell detection results. Typically, to train CNN-based cell detection models, every positive instance in the training images needs to be annotated, and instances that are not labeled as positive are considered negative samples. However, manual cell annotation is complicated due to the large number and diversity of cells, and it can be difficult to ensure the annotation of every positive instance. In many cases, only incomplete annotations are available, where some of the positive instances are annotated and the others are not, and the classification loss term for negative samples in typical network training becomes incorrect. In this work, to address this problem of incomplete annotations, we propose to reformulate the training of the detection network as a positive-unlabeled learning problem. Since the instances in unannotated regions can be either positive or negative, they have unknown labels. Using the samples with unknown labels and the positively labeled samples, we first derive an approximation of the classification loss term corresponding to negative samples for binary cell detection, and based on this approximation we further extend the proposed framework to multi-class cell detection. For evaluation, experiments were performed on four publicly available datasets. The experimental results show that our method improves the performance of cell detection in histopathology images given incomplete annotations for network training.
* Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://melba-journal.org/2022:027. arXiv admin note: text overlap with arXiv:2106.15918
Positive-unlabeled Learning for Cell Detection in Histopathology Images with Incomplete Annotations
Jun 30, 2021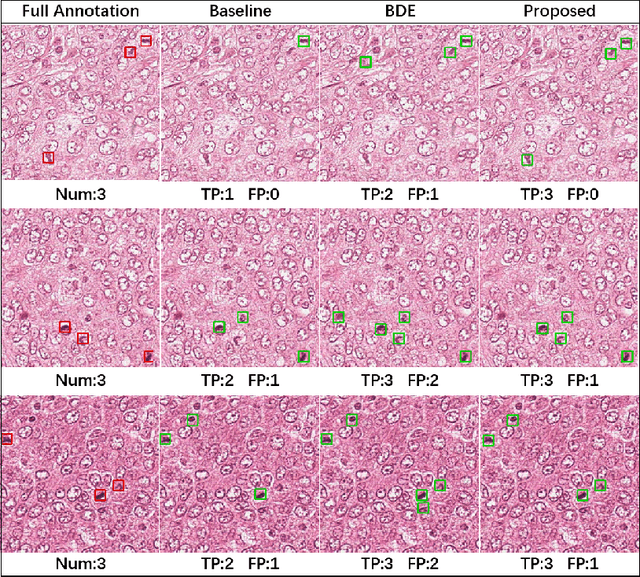

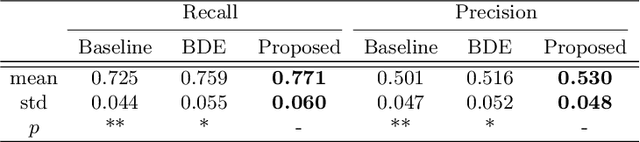
Cell detection in histopathology images is of great value in clinical practice. \textit{Convolutional neural networks} (CNNs) have been applied to cell detection to improve the detection accuracy, where cell annotations are required for network training. However, due to the variety and large number of cells, complete annotations that include every cell of interest in the training images can be challenging. Usually, incomplete annotations can be achieved, where positive labeling results are carefully examined to ensure their reliability but there can be other positive instances, i.e., cells of interest, that are not included in the annotations. This annotation strategy leads to a lack of knowledge about true negative samples. Most existing methods simply treat instances that are not labeled as positive as truly negative during network training, which can adversely affect the network performance. In this work, to address the problem of incomplete annotations, we formulate the training of detection networks as a positive-unlabeled learning problem. Specifically, the classification loss in network training is revised to take into account incomplete annotations, where the terms corresponding to negative samples are approximated with the true positive samples and the other samples of which the labels are unknown. To evaluate the proposed method, experiments were performed on a publicly available dataset for mitosis detection in breast cancer cells, and the experimental results show that our method improves the performance of cell detection given incomplete annotations for training.