 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalanced Hierarchical Contrastive Learning with Decoupled Queries for Fine-grained Object Detection in Remote Sensing Images
Dec 30, 2025Fine-grained remote sensing datasets often use hierarchical label structures to differentiate objects in a coarse-to-fine manner, with each object annotated across multiple levels. However, embedding this semantic hierarchy into the representation learning space to improve fine-grained detection performance remains challenging. Previous studies have applied supervised contrastive learning at different hierarchical levels to group objects under the same parent class while distinguishing sibling subcategories. Nevertheless, they overlook two critical issues: (1) imbalanced data distribution across the label hierarchy causes high-frequency classes to dominate the learning process, and (2) learning semantic relationships among categories interferes with class-agnostic localization. To address these issues, we propose a balanced hierarchical contrastive loss combined with a decoupled learning strategy within the detection transformer (DETR) framework. The proposed loss introduces learnable class prototypes and equilibrates gradients contributed by different classes at each hierarchical level, ensuring that each hierarchical class contributes equally to the loss computation in every mini-batch. The decoupled strategy separates DETR's object queries into classification and localization sets, enabling task-specific feature extraction and optimization. Experiments on three fine-grained datasets with hierarchical annotations demonstrate that our method outperforms state-of-the-art approaches.
SUIT: Spatial-Spectral Union-Intersection Interaction Network for Hyperspectral Object Tracking
Aug 10, 2025



Hyperspectral videos (HSVs), with their inherent spatial-spectral-temporal structure, offer distinct advantages in challenging tracking scenarios such as cluttered backgrounds and small objects. However, existing methods primarily focus on spatial interactions between the template and search regions, often overlooking spectral interactions, leading to suboptimal performance. To address this issue, this paper investigates spectral interactions from both the architectural and training perspectives. At the architectural level, we first establish band-wise long-range spatial relationships between the template and search regions using Transformers. We then model spectral interactions using the inclusion-exclusion principle from set theory, treating them as the union of spatial interactions across all bands. This enables the effective integration of both shared and band-specific spatial cues. At the training level, we introduce a spectral loss to enforce material distribution alignment between the template and predicted regions, enhancing robustness to shape deformation and appearance variations. Extensive experiments demonstrate that our tracker achieves state-of-the-art tracking performance. The source code, trained models and results will be publicly available via https://github.com/bearshng/suit to support reproducibility.
SSUMamba: Spatial-Spectral Selective State Space Model for Hyperspectral Image Denoising
May 06, 2024



Denoising hyperspectral images (HSIs) is a crucial preprocessing procedure due to the noise originating from intra-imaging mechanisms and environmental factors. Utilizing domain-specific knowledge of HSIs, such as spectral correlation, spatial self-similarity, and spatial-spectral correlation, is essential for deep learning-based denoising. Existing methods are often constrained by running time, space complexity, and computational complexity, employing strategies that explore these priors separately. While these strategies can avoid some redundant information, they inevitably overlook broader and more underlying long-range spatial-spectral information that positively impacts image restoration. This paper proposes a Spatial-Spectral Selective State Space Model-based U-shaped network, termed Spatial-Spectral U-Mamba (SSUMamba), for hyperspectral image denoising. We can obtain complete global spatial-spectral correlation within a module thanks to the linear space complexity in State Space Model (SSM) computations. We introduce a Spatial-Spectral Alternating Scan (SSAS) strategy for HSIs, which helps model the information flow in multiple directions in 3-D HSIs. Experimental results demonstrate that our method outperforms compared methods. The source code will be available at https://github.com/lronkitty/SSUMamba.
Hyperspectral Image Denoising via Spatial-Spectral Recurrent Transformer
Jan 09, 2024



Hyperspectral images (HSIs) often suffer from noise arising from both intra-imaging mechanisms and environmental factors. Leveraging domain knowledge specific to HSIs, such as global spectral correlation (GSC) and non-local spatial self-similarity (NSS), is crucial for effective denoising. Existing methods tend to independently utilize each of these knowledge components with multiple blocks, overlooking the inherent 3D nature of HSIs where domain knowledge is strongly interlinked, resulting in suboptimal performance. To address this challenge, this paper introduces a spatial-spectral recurrent transformer U-Net (SSRT-UNet) for HSI denoising. The proposed SSRT-UNet integrates NSS and GSC properties within a single SSRT block. This block consists of a spatial branch and a spectral branch. The spectral branch employs a combination of transformer and recurrent neural network to perform recurrent computations across bands, allowing for GSC exploitation beyond a fixed number of bands. Concurrently, the spatial branch encodes NSS for each band by sharing keys and values with the spectral branch under the guidance of GSC. This interaction between the two branches enables the joint utilization of NSS and GSC, avoiding their independent treatment. Experimental results demonstrate that our method outperforms several alternative approaches. The source code will be available at https://github.com/lronkitty/SSRT.
SMDS-Net: Model Guided Spectral-Spatial Network for Hyperspectral Image Denoising
Dec 03, 2020
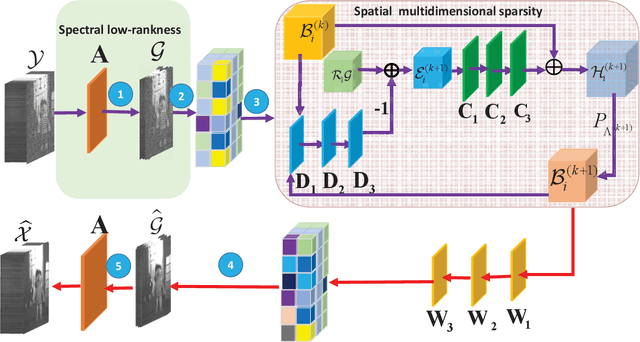


Deep learning (DL) based hyperspectral images (HSIs) denoising approaches directly learn the nonlinear mapping between observed noisy images and underlying clean images. They normally do not consider the physical characteristics of HSIs, therefore making them lack of interpretability that is key to understand their denoising mechanism.. In order to tackle this problem, we introduce a novel model guided interpretable network for HSI denoising. Specifically, fully considering the spatial redundancy, spectral low-rankness and spectral-spatial properties of HSIs, we first establish a subspace based multi-dimensional sparse model. This model first projects the observed HSIs into a low-dimensional orthogonal subspace, and then represents the projected image with a multidimensional dictionary. After that, the model is unfolded into an end-to-end network named SMDS-Net whose fundamental modules are seamlessly connected with the denoising procedure and optimization of the model. This makes SMDS-Net convey clear physical meanings, i.e., learning the low-rankness and sparsity of HSIs. Finally, all key variables including dictionaries and thresholding parameters are obtained by the end-to-end training. Extensive experiments and comprehensive analysis confirm the denoising ability and interpretability of our method against the state-of-the-art HSI denoising methods.
Spectral-spatial features for material based object tracking in hyperspectral videos
Dec 23, 2018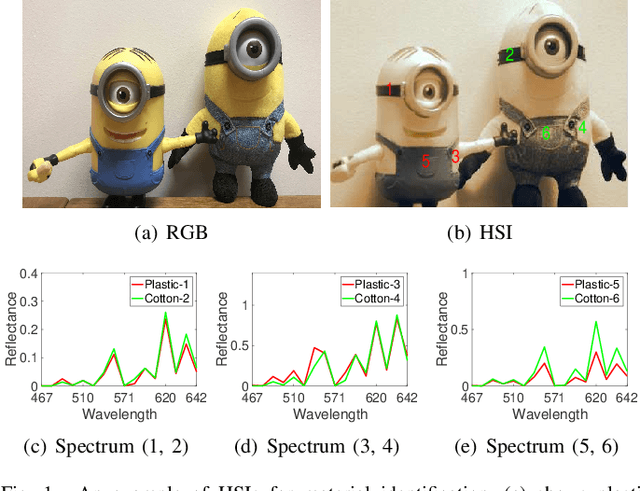
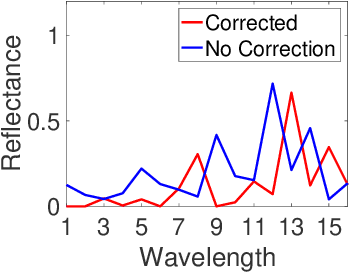
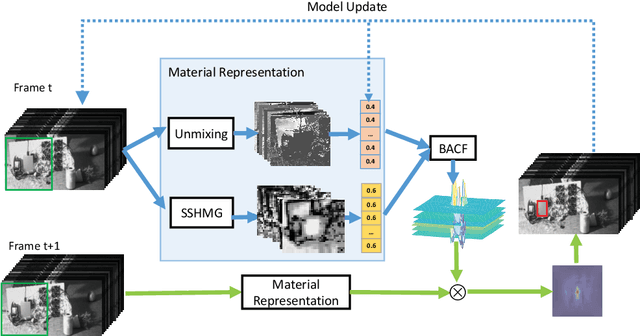
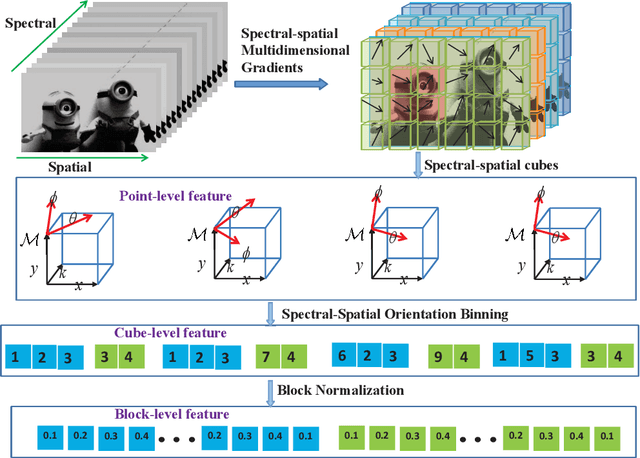
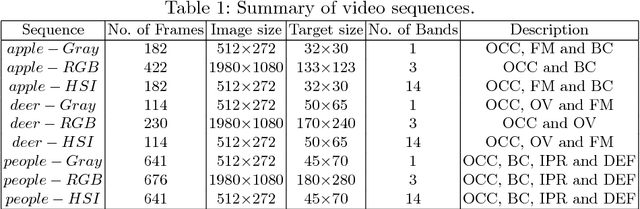
Traditional color images only depict color intensities in red, green and blue channels, often making object trackers fail when a target shares similar color or texture as its surrounding environment. Alternatively, material information of targets contained in a large amount of bands of hyperspectral images (HSI) is more robust to these challenging conditions. In this paper, we conduct a comprehensive study on how HSIs can be utilized to boost object tracking from three aspects: benchmark dataset, material feature representation and material based tracking. In terms of benchmark, we construct a dataset of fully-annotated videos which contain both hyperspectral and color sequences of the same scene. We extract two types of material features from these videos. We first introduce a novel 3D spectral-spatial histogram of gradient to describe the local spectral-spatial structure in an HSI. Then an HSI is decomposed into the detailed constituent materials and associate abundances, i.e., proportions of materials at each location, to encode the underlying information on material distribution. These two types of features are embedded into correlation filters, yielding material based tracking. Experimental results on the collected benchmark dataset show the potentials and advantages of material based object tracking.
Object Tracking in Hyperspectral Videos with Convolutional Features and Kernelized Correlation Filter
Oct 28, 2018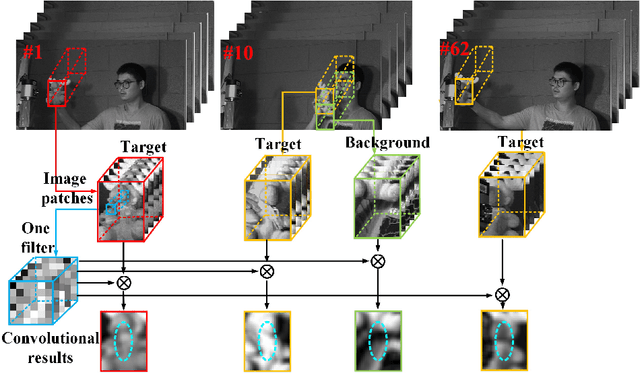
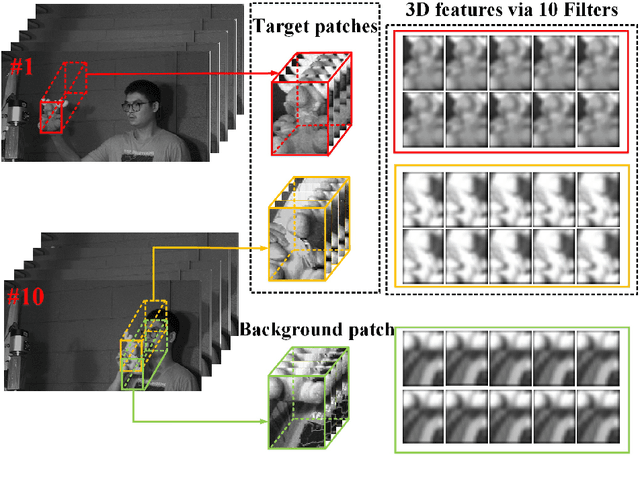
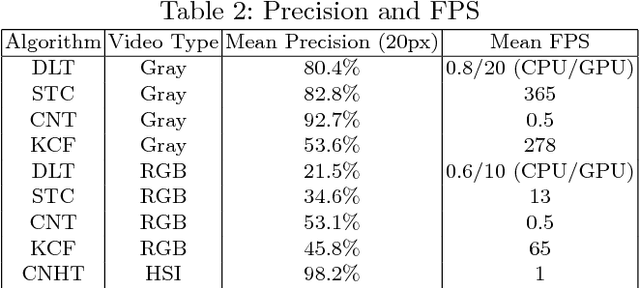
Target tracking in hyperspectral videos is a new research topic. In this paper, a novel method based on convolutional network and Kernelized Correlation Filter (KCF) framework is presented for tracking objects of interest in hyperspectral videos. We extract a set of normalized three-dimensional cubes from the target region as fixed convolution filters which contain spectral information surrounding a target. The feature maps generated by convolutional operations are combined to form a three-dimensional representation of an object, thereby providing effective encoding of local spectral-spatial information. We show that a simple two-layer convolutional networks is sufficient to learn robust representations without the need of offline training with a large dataset. In the tracking step, KCF is adopted to distinguish targets from neighboring environment. Experimental results demonstrate that the proposed method performs well on sample hyperspectral videos, and outperforms several state-of-the-art methods tested on grayscale and color videos in the same scene.