 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Pass Filtering Improves Behavioral Alignment of Vision Models
Feb 14, 2026Despite their impressive performance on computer vision benchmarks, Deep Neural Networks (DNNs) still fall short of adequately modeling human visual behavior, as measured by error consistency and shape bias. Recent work hypothesized that behavioral alignment can be drastically improved through \emph{generative} -- rather than \emph{discriminative} -- classifiers, with far-reaching implications for models of human vision. Here, we instead show that the increased alignment of generative models can be largely explained by a seemingly innocuous resizing operation in the generative model which effectively acts as a low-pass filter. In a series of controlled experiments, we show that removing high-frequency spatial information from discriminative models like CLIP drastically increases their behavioral alignment. Simply blurring images at test-time -- rather than training on blurred images -- achieves a new state-of-the-art score on the model-vs-human benchmark, halving the current alignment gap between DNNs and human observers. Furthermore, low-pass filters are likely optimal, which we demonstrate by directly optimizing filters for alignment. To contextualize the performance of optimal filters, we compute the frontier of all possible pareto-optimal solutions to the benchmark, which was formerly unknown. We explain our findings by observing that the frequency spectrum of optimal Gaussian filters roughly matches the spectrum of band-pass filters implemented by the human visual system. We show that the contrast sensitivity function, describing the inverse of the contrast threshold required for humans to detect a sinusoidal grating as a function of spatiotemporal frequency, is approximated well by Gaussian filters of the specific width that also maximizes error consistency.
MentisOculi: Revealing the Limits of Reasoning with Mental Imagery
Feb 02, 2026Frontier models are transitioning from multimodal large language models (MLLMs) that merely ingest visual information to unified multimodal models (UMMs) capable of native interleaved generation. This shift has sparked interest in using intermediate visualizations as a reasoning aid, akin to human mental imagery. Central to this idea is the ability to form, maintain, and manipulate visual representations in a goal-oriented manner. To evaluate and probe this capability, we develop MentisOculi, a procedural, stratified suite of multi-step reasoning problems amenable to visual solution, tuned to challenge frontier models. Evaluating visual strategies ranging from latent tokens to explicit generated imagery, we find they generally fail to improve performance. Analysis of UMMs specifically exposes a critical limitation: While they possess the textual reasoning capacity to solve a task and can sometimes generate correct visuals, they suffer from compounding generation errors and fail to leverage even ground-truth visualizations. Our findings suggest that despite their inherent appeal, visual thoughts do not yet benefit model reasoning. MentisOculi establishes the necessary foundation to analyze and close this gap across diverse model families.
How Aligned are Different Alignment Metrics?
Jul 10, 2024



In recent years, various methods and benchmarks have been proposed to empirically evaluate the alignment of artificial neural networks to human neural and behavioral data. But how aligned are different alignment metrics? To answer this question, we analyze visual data from Brain-Score (Schrimpf et al., 2018), including metrics from the model-vs-human toolbox (Geirhos et al., 2021), together with human feature alignment (Linsley et al., 2018; Fel et al., 2022) and human similarity judgements (Muttenthaler et al., 2022). We find that pairwise correlations between neural scores and behavioral scores are quite low and sometimes even negative. For instance, the average correlation between those 80 models on Brain-Score that were fully evaluated on all 69 alignment metrics we considered is only 0.198. Assuming that all of the employed metrics are sound, this implies that alignment with human perception may best be thought of as a multidimensional concept, with different methods measuring fundamentally different aspects. Our results underline the importance of integrative benchmarking, but also raise questions about how to correctly combine and aggregate individual metrics. Aggregating by taking the arithmetic average, as done in Brain-Score, leads to the overall performance currently being dominated by behavior (95.25% explained variance) while the neural predictivity plays a less important role (only 33.33% explained variance). As a first step towards making sure that different alignment metrics all contribute fairly towards an integrative benchmark score, we therefore conclude by comparing three different aggregation options.
Estimation of perceptual scales using ordinal embedding
Aug 21, 2019



In this paper, we address the problem of measuring and analysing sensation, the subjective magnitude of one's experience. We do this in the context of the method of triads: the sensation of the stimulus is evaluated via relative judgments of the form: "Is stimulus S_i more similar to stimulus S_j or to stimulus S_k?". We propose to use ordinal embedding methods from machine learning to estimate the scaling function from the relative judgments. We review two relevant and well-known methods in psychophysics which are partially applicable in our setting: non-metric multi-dimensional scaling (NMDS) and the method of maximum likelihood difference scaling (MLDS). We perform an extensive set of simulations, considering various scaling functions, to demonstrate the performance of the ordinal embedding methods. We show that in contrast to existing approaches our ordinal embedding approach allows, first, to obtain reasonable scaling function from comparatively few relative judgments, second, the estimation of non-monotonous scaling functions, and, third, multi-dimensional perceptual scales. In addition to the simulations, we analyse data from two real psychophysics experiments using ordinal embedding methods. Our results show that in the one-dimensional, monotonically increasing perceptual scale our ordinal embedding approach works as well as MLDS, while in higher dimensions, only our ordinal embedding methods can produce a desirable scaling function. To make our methods widely accessible, we provide an R-implementation and general rules of thumb on how to use ordinal embedding in the context of psychophysics.
Comparison-Based Framework for Psychophysics: Lab versus Crowdsourcing
May 17, 2019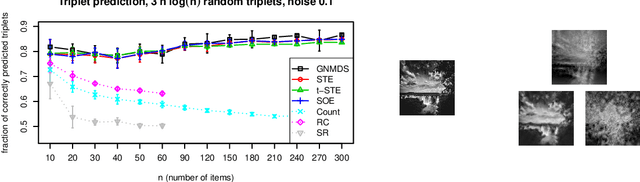
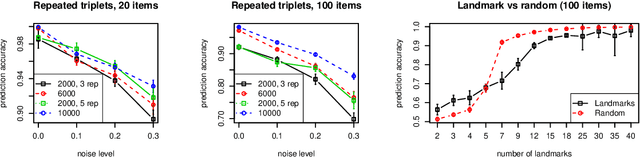
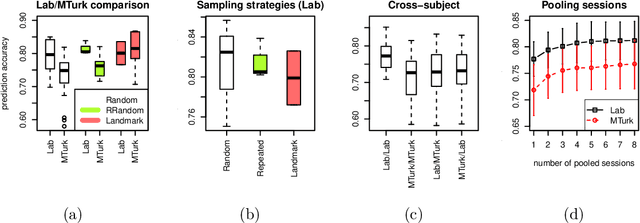
Traditionally, psychophysical experiments are conducted by repeated measurements on a few well-trained participants under well-controlled conditions, often resulting in, if done properly, high quality data. In recent years, however, crowdsourcing platforms are becoming increasingly popular means of data collection, measuring many participants at the potential cost of obtaining data of worse quality. In this paper we study whether the use of comparison-based (ordinal) data, combined with machine learning algorithms, can boost the reliability of crowdsourcing studies for psychophysics, such that they can achieve performance close to a lab experiment. To this end, we compare three setups: simulations, a psychophysics lab experiment, and the same experiment on Amazon Mechanical Turk. All these experiments are conducted in a comparison-based setting where participants have to answer triplet questions of the form "is object x closer to y or to z?". We then use machine learning to solve the triplet prediction problem: given a subset of triplet questions with corresponding answers, we predict the answer to the remaining questions. Considering the limitations and noise on MTurk, we find that the accuracy of triplet prediction is surprisingly close---but not equal---to our lab study.