 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing Missing EHRs Using Time-Aware Within- and Cross-Visit Information for Septic Shock Early Prediction
Mar 15, 2022

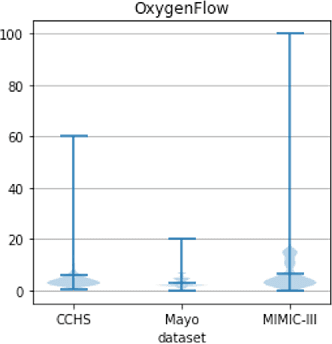
Real-world Electronic Health Records (EHRs) are often plagued by a high rate of missing data. In our EHRs, for example, the missing rates can be as high as 90% for some features, with an average missing rate of around 70% across all features. We propose a Time-Aware Dual-Cross-Visit missing value imputation method, named TA-DualCV, which spontaneously leverages multivariate dependencies across features and longitudinal dependencies both within- and cross-visit to maximize the information extracted from limited observable records in EHRs. Specifically, TA-DualCV captures the latent structure of missing patterns across measurements of different features and it also considers the time continuity and capture the latent temporal missing patterns based on both time-steps and irregular time-intervals. TA-DualCV is evaluated using three large real-world EHRs on two types of tasks: an unsupervised imputation task by varying mask rates up to 90% and a supervised 24-hour early prediction of septic shock using Long Short-Term Memory (LSTM). Our results show that TA-DualCV performs significantly better than all of the existing state-of-the-art imputation baselines, such as DETROIT and TAME, on both types of tasks.
An Adversarial Domain Separation Framework for Septic Shock Early Prediction Across EHR Systems
Oct 26, 2020

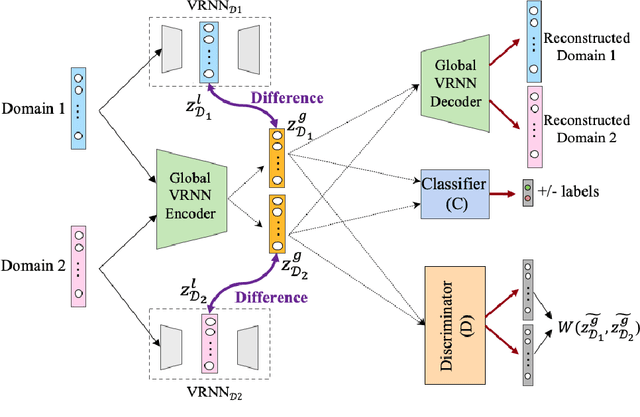
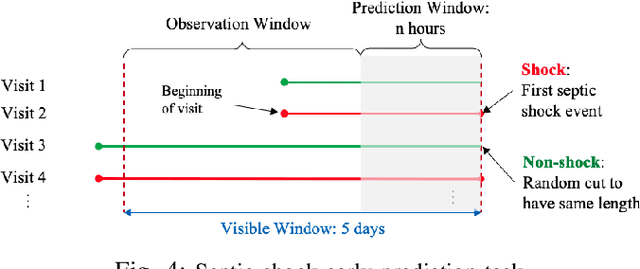
Modeling patient disease progression using Electronic Health Records (EHRs) is critical to assist clinical decision making. While most of prior work has mainly focused on developing effective disease progression models using EHRs collected from an individual medical system, relatively little work has investigated building robust yet generalizable diagnosis models across different systems. In this work, we propose a general domain adaptation (DA) framework that tackles two categories of discrepancies in EHRs collected from different medical systems: one is caused by heterogeneous patient populations (covariate shift) and the other is caused by variations in data collection procedures (systematic bias). Prior research in DA has mainly focused on addressing covariate shift but not systematic bias. In this work, we propose an adversarial domain separation framework that addresses both categories of discrepancies by maintaining one globally-shared invariant latent representation across all systems} through an adversarial learning process, while also allocating a domain-specific model for each system to extract local latent representations that cannot and should not be unified across systems. Moreover, our proposed framework is based on variational recurrent neural network (VRNN) because of its ability to capture complex temporal dependencies and handling missing values in time-series data. We evaluate our framework for early diagnosis of an extremely challenging condition, septic shock, using two real-world EHRs from distinct medical systems in the U.S. The results show that by separating globally-shared from domain-specific representations, our framework significantly improves septic shock early prediction performance in both EHRs and outperforms the current state-of-the-art DA models.
Improving Robustness on Seasonality-Heavy Multivariate Time Series Anomaly Detection
Jul 25, 2020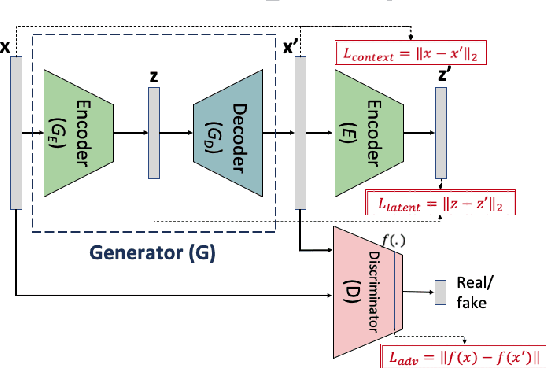
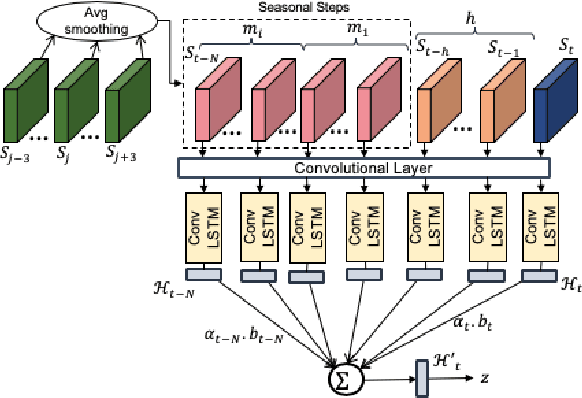
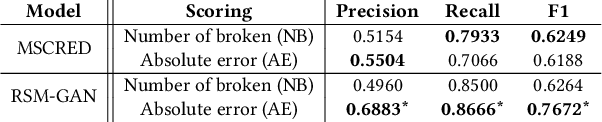
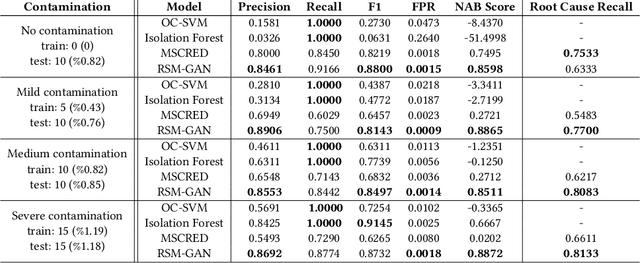
Robust Anomaly Detection (AD) on time series data is a key component for monitoring many complex modern systems. These systems typically generate high-dimensional time series that can be highly noisy, seasonal, and inter-correlated. This paper explores some of the challenges in such data, and proposes a new approach that makes inroads towards increased robustness on seasonal and contaminated data, while providing a better root cause identification of anomalies. In particular, we propose the use of Robust Seasonal Multivariate Generative Adversarial Network (RSM-GAN) that extends recent advancements in GAN with the adoption of convolutional-LSTM layers and attention mechanisms to produce excellent performance on various settings. We conduct extensive experiments in which not only do this model displays more robust behavior on complex seasonality patterns, but also shows increased resistance to training data contamination. We compare it with existing classical and deep-learning AD models, and show that this architecture is associated with the lowest false positive rate and improves precision by 30% and 16% in real-world and synthetic data, respectively.
* arXiv admin note: substantial text overlap with arXiv:1911.07104
RSM-GAN: A Convolutional Recurrent GAN for Anomaly Detection in Contaminated Seasonal Multivariate Time Series
Nov 16, 2019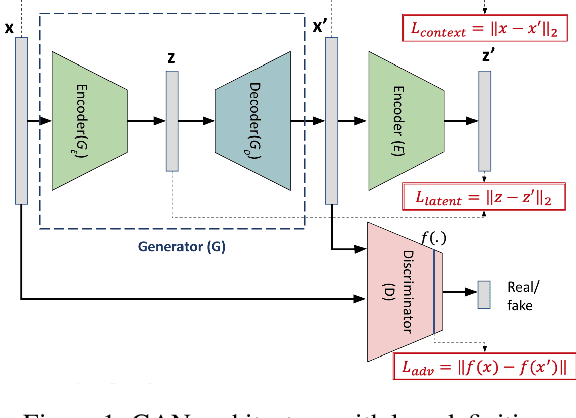
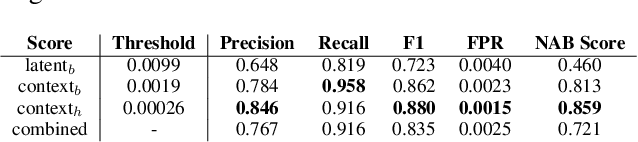
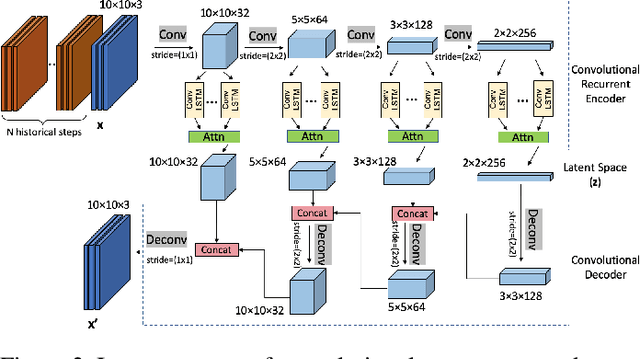
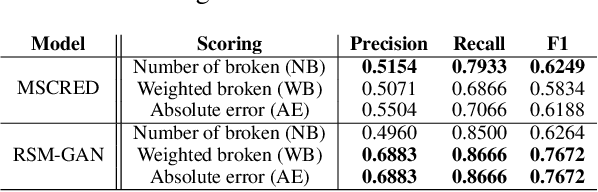
Robust anomaly detection is a requirement for monitoring complex modern systems with applications such as cyber-security, fraud prevention, and maintenance. These systems generate multiple correlated time series that are highly seasonal and noisy. This paper presents a novel unsupervised deep learning architecture for multivariate time series anomaly detection, called Robust Seasonal Multivariate Generative Adversarial Network (RSM-GAN). It extends recent advancements in GANs with adoption of convolutional-LSTM layers and an attention mechanism to produce state-of-the-art performance. We conduct extensive experiments to demonstrate the strength of our architecture in adjusting for complex seasonality patterns and handling severe levels of training data contamination. We also propose a novel anomaly score assignment and causal inference framework. We compare RSM-GAN with existing classical and deep-learning based anomaly detection models, and the results show that our architecture is associated with the lowest false positive rate and improves precision by 30% and 16% in real-world and synthetic data, respectively. Furthermore, we report the superiority of RSM-GAN regarding accurate root cause identification and NAB scores in all data settings.
Your Actions or Your Associates? Predicting Certification and Dropout in MOOCs with Behavioral and Social Features
Aug 31, 2018
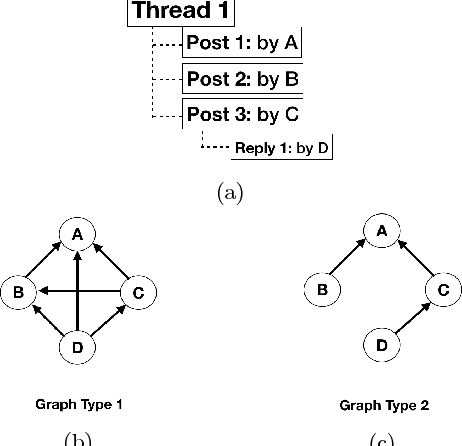
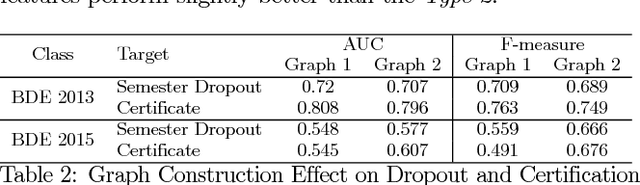
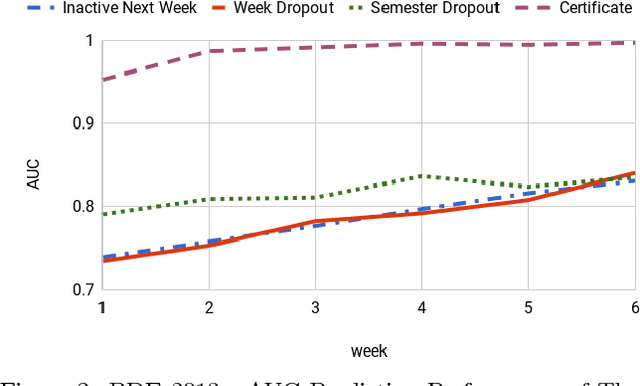
The high level of attrition and low rate of certification in Massive Open Online Courses (MOOCs) has prompted a great deal of research. Prior researchers have focused on predicting dropout based upon behavioral features such as student confusion, click-stream patterns, and social interactions. However, few studies have focused on combining student logs with forum data. In this work, we use data from two different offerings of the same MOOC. We conduct a survival analysis to identify likely dropouts. We then examine two classes of features, social and behavioral, and apply a combination of modeling and feature-selection methods to identify the most relevant features to predict both dropout and certification. We examine the utility of three different model types and we consider the impact of different definitions of dropout on the predictors. Finally, we assess the reliability of the models over time by evaluating whether or not models from week 1 can predict dropout in week 2, and so on. The outcomes of this study will help instructors identify students likely to fail or dropout as soon as the first two weeks and provide them with more support.