 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVocal Melody Construction for Persian Lyrics Using LSTM Recurrent Neural Networks
Oct 23, 2024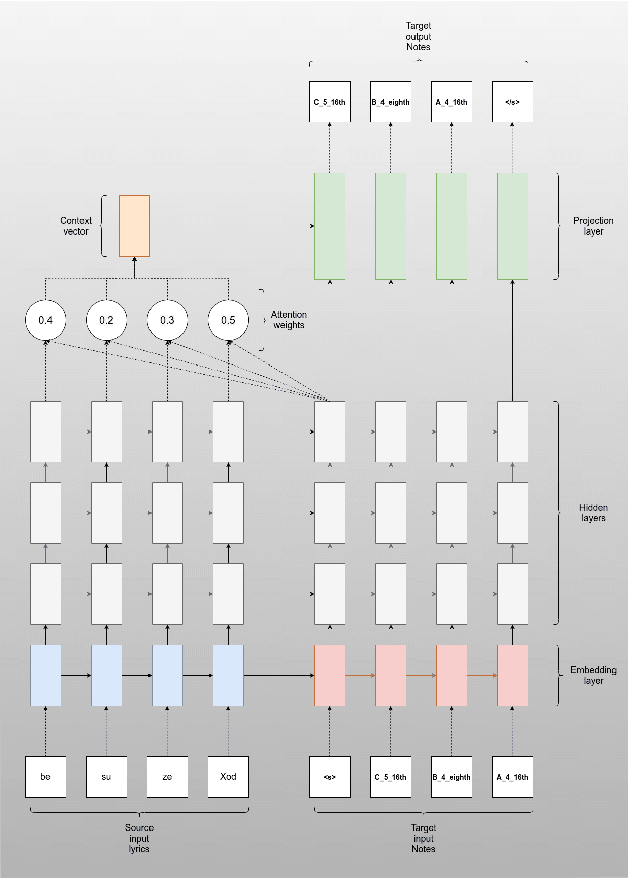
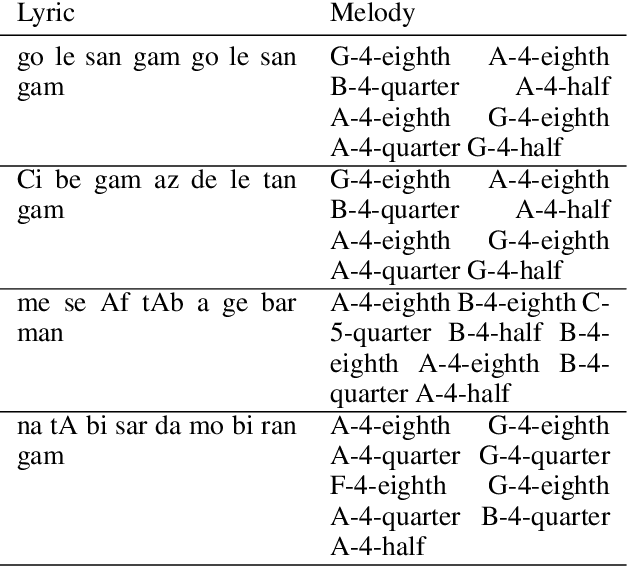
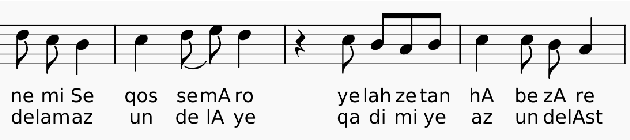

The present paper investigated automatic melody construction for Persian lyrics as an input. It was assumed that there is a phonological correlation between the lyric syllables and the melody in a song. A seq2seq neural network was developed to investigate this assumption, trained on parallel syllable and note sequences in Persian songs to suggest a pleasant melody for a new sequence of syllables. More than 100 pieces of Persian music were collected and converted from the printed version to the digital format due to the lack of a dataset on Persian digital music. Finally, 14 new lyrics were given to the model as input, and the suggested melodies were performed and recorded by music experts to evaluate the trained model. The evaluation was conducted using an audio questionnaire, which more than 170 persons answered. According to the answers about the pleasantness of melody, the system outputs scored an average of 3.005 from 5, while the human-made melodies for the same lyrics obtained an average score of 4.078.
Melody Construction for Persian lyrics using LSTM recurrent neural networks
Oct 23, 2024The present paper investigated automatic melody construction for Persian lyrics as an input. It was assumed that there is a phonological correlation between the lyric syllables and the melody in a song. A seq2seq neural network was developed to investigate this assumption, trained on parallel syllable and note sequences in Persian songs to suggest a pleasant melody for a new sequence of syllables. More than 100 pieces of Persian music were collected and converted from the printed version to the digital format due to the lack of a dataset on Persian digital music. Finally, 14 new lyrics were given to the model as input, and the suggested melodies were performed and recorded by music experts to evaluate the trained model. The evaluation was conducted using an audio questionnaire, which more than 170 persons answered. According to the answers about the pleasantness of melody, the system outputs scored an average of 3.005 from 5, while the human-made melodies for the same lyrics obtained an average score of 4.078.
Iranian Modal Music (Dastgah) detection using deep neural networks
Mar 29, 2022


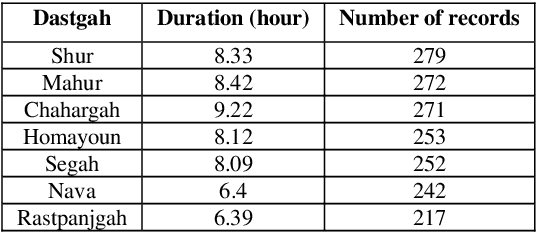
In this work, several deep neural networks are implemented to recognize Iranian modal music in seven high correlated categories. The best model, which achieved 92 percent overall accuracy, uses an architecture inspired by autoencoder, including BiLSTM and BiGRU layers. This model is trained using the Nava dataset, with 1786 records and up to 55 hours of music played solo by Kamanche, Tar, Setar, Reed, and Santoor (Dulcimer). Features that have been studied through this research contain MFCC, Chroma CENS, and Mel spectrogram. The results indicate that MFCC carries more valuable information for detecting Iranian modal music (Dastgah) than other sound representations. Moreover, the architecture, which is inspired by autoencoder, is robust in distinguishing high correlated data like Dastgahs. It also shows that because of the precise order in Iranian Dastgah Music, Bidirectional Recurrent networks are more efficient than any other networks that have been implemented in this study.
Clustering validity based on the most similarity
Feb 16, 2013One basic requirement of many studies is the necessity of classifying data. Clustering is a proposed method for summarizing networks. Clustering methods can be divided into two categories named model-based approaches and algorithmic approaches. Since the most of clustering methods depend on their input parameters, it is important to evaluate the result of a clustering algorithm with its different input parameters, to choose the most appropriate one. There are several clustering validity techniques based on inner density and outer density of clusters that represent different metrics to choose the most appropriate clustering independent of the input parameters. According to dependency of previous methods on the input parameters, one challenge in facing with large systems, is to complete data incrementally that effects on the final choice of the most appropriate clustering. Those methods define the existence of high intensity in a cluster, and low intensity among different clusters as the measure of choosing the optimal clustering. This measure has a tremendous problem, not availing all data at the first stage. In this paper, we introduce an efficient measure in which maximum number of repetitions for various initial values occurs.
Modification of the Elite Ant System in Order to Avoid Local Optimum Points in the Traveling Salesman Problem
Feb 07, 2012This article presents a new algorithm which is a modified version of the elite ant system (EAS) algorithm. The new version utilizes an effective criterion for escaping from the local optimum points. In contrast to the classical EAC algorithms, the proposed algorithm uses only a global updating, which will increase pheromone on the edges of the best (i.e. the shortest) route and will at the same time decrease the amount of pheromone on the edges of the worst (i.e. the longest) route. In order to assess the efficiency of the new algorithm, some standard traveling salesman problems (TSPs) were studied and their results were compared with classical EAC and other well-known meta-heuristic algorithms. The results indicate that the proposed algorithm has been able to improve the efficiency of the algorithms in all instances and it is competitive with other algorithms.
A Novel Template-Based Learning Model
Jan 26, 2011This article presents a model which is capable of learning and abstracting new concepts based on comparing observations and finding the resemblance between the observations. In the model, the new observations are compared with the templates which have been derived from the previous experiences. In the first stage, the objects are first represented through a geometric description which is used for finding the object boundaries and a descriptor which is inspired by the human visual system and then they are fed into the model. Next, the new observations are identified through comparing them with the previously-learned templates and are used for producing new templates. The comparisons are made based on measures like Euclidean or correlation distance. The new template is created by applying onion-pealing algorithm. The algorithm consecutively uses convex hulls which are made by the points representing the objects. If the new observation is remarkably similar to one of the observed categories, it is no longer utilized in creating a new template. The existing templates are used to provide a description of the new observation. This description is provided in the templates space. Each template represents a dimension of the feature space. The degree of the resemblance each template bears to each object indicates the value associated with the object in that dimension of the templates space. In this way, the description of the new observation becomes more accurate and detailed as the time passes and the experiences increase. We have used this model for learning and recognizing the new polygons in the polygon space. Representing the polygons was made possible through employing a geometric method and a method inspired by human visual system. Various implementations of the model have been compared. The evaluation results of the model prove its efficiency in learning and deriving new templates.
On Defining 'I' "I logy"
Jun 06, 2009Could we define I? Throughout this article we give a negative answer to this question. More exactly, we show that there is no definition for I in a certain way. But this negative answer depends on our definition of definability. Here, we try to consider sufficient generalized definition of definability. In the middle of paper a paradox will arise which makes us to modify the way we use the concept of property and definability.