 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVocal Melody Construction for Persian Lyrics Using LSTM Recurrent Neural Networks
Oct 23, 2024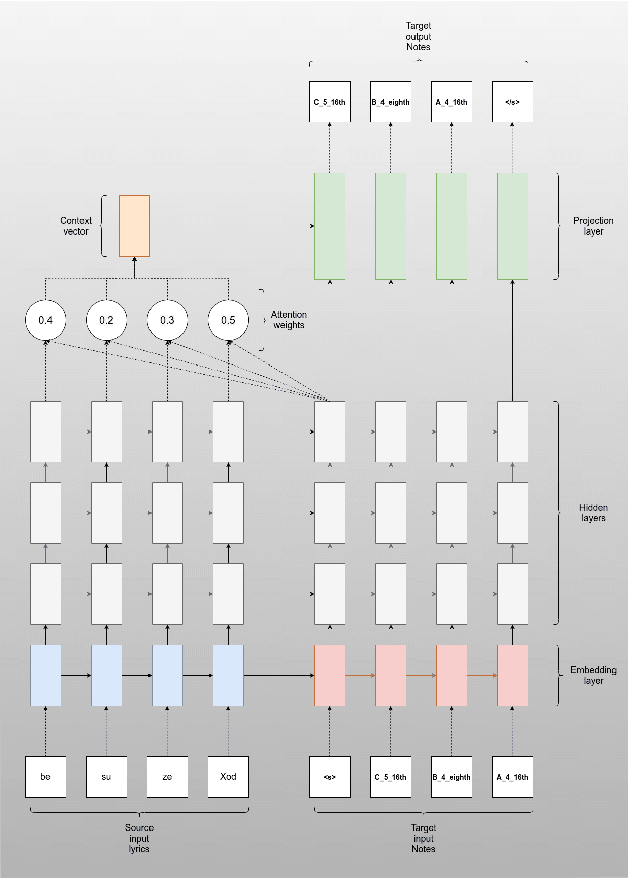
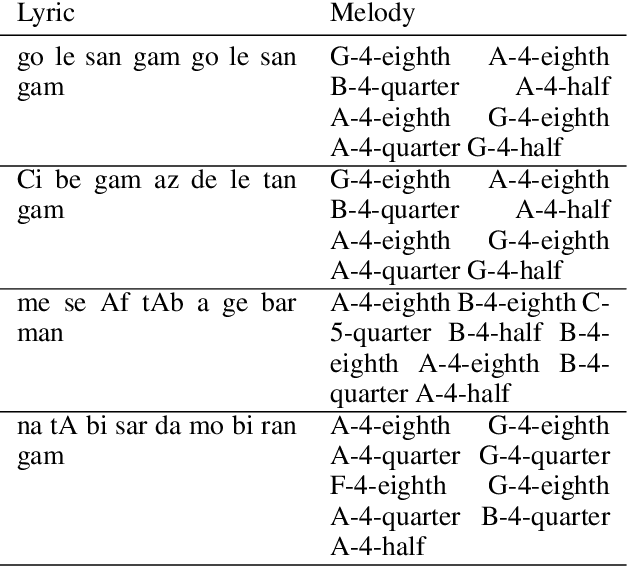
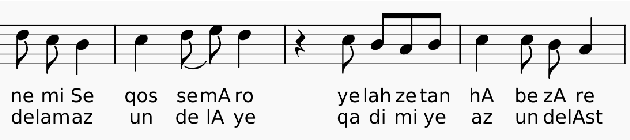

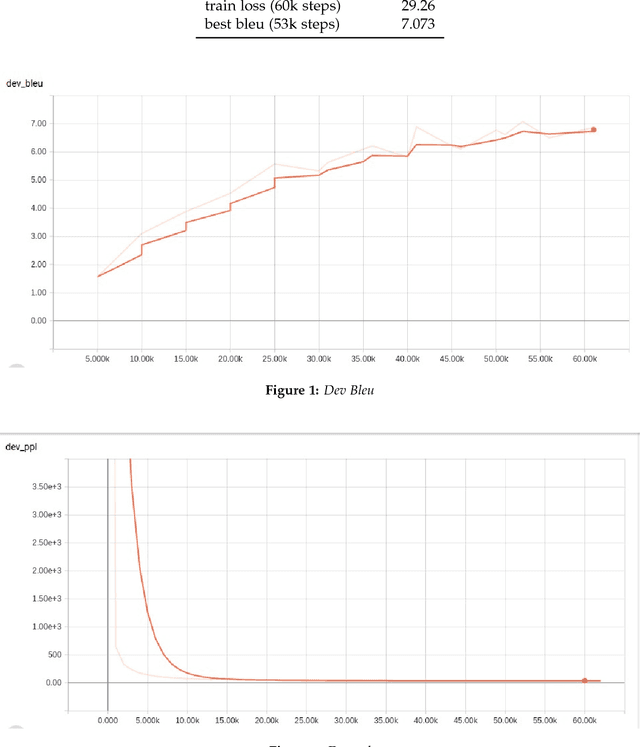
The present paper investigated automatic melody construction for Persian lyrics as an input. It was assumed that there is a phonological correlation between the lyric syllables and the melody in a song. A seq2seq neural network was developed to investigate this assumption, trained on parallel syllable and note sequences in Persian songs to suggest a pleasant melody for a new sequence of syllables. More than 100 pieces of Persian music were collected and converted from the printed version to the digital format due to the lack of a dataset on Persian digital music. Finally, 14 new lyrics were given to the model as input, and the suggested melodies were performed and recorded by music experts to evaluate the trained model. The evaluation was conducted using an audio questionnaire, which more than 170 persons answered. According to the answers about the pleasantness of melody, the system outputs scored an average of 3.005 from 5, while the human-made melodies for the same lyrics obtained an average score of 4.078.
Melody Construction for Persian lyrics using LSTM recurrent neural networks
Oct 23, 2024The present paper investigated automatic melody construction for Persian lyrics as an input. It was assumed that there is a phonological correlation between the lyric syllables and the melody in a song. A seq2seq neural network was developed to investigate this assumption, trained on parallel syllable and note sequences in Persian songs to suggest a pleasant melody for a new sequence of syllables. More than 100 pieces of Persian music were collected and converted from the printed version to the digital format due to the lack of a dataset on Persian digital music. Finally, 14 new lyrics were given to the model as input, and the suggested melodies were performed and recorded by music experts to evaluate the trained model. The evaluation was conducted using an audio questionnaire, which more than 170 persons answered. According to the answers about the pleasantness of melody, the system outputs scored an average of 3.005 from 5, while the human-made melodies for the same lyrics obtained an average score of 4.078.
Traversing Emotional Landscapes and Linguistic Patterns in Bernard-Marie Koltès' Plays: An NLP Perspective
Oct 12, 2024This study employs Natural Language Processing (NLP) to analyze the intricate linguistic and emotional dimensions within the plays of Bernard-Marie Kolt\`es, a central figure in contemporary French theatre. By integrating advanced computational techniques, we dissect Kolt\`es' narrative style, revealing the subtle interplay between language and emotion across his dramatic oeuvre. Our findings highlight how Kolt\`es crafts his narratives, enriching our understanding of his thematic explorations and contributing to the broader field of digital humanities in literary analysis.
I or Not I: Unraveling the Linguistic Echoes of Identity in Samuel Beckett's "Not I" Through Natural Language Processing
Oct 12, 2024



Exploring the depths of Samuel Beckett's "Not I" through advanced natural language processing techniques, this research uncovers the intricate linguistic structures that underpin the text. By analyzing word frequency, detecting emotional sentiments with a BERT-based model, and examining repetitive motifs, we unveil how Beckett's minimalist yet complex language reflects the protagonist's fragmented psyche. Our results demonstrate that recurring themes of time, memory, and existential angst are artfully woven through recursive linguistic patterns and rhythmic repetition. This innovative approach not only deepens our understanding of Beckett's stylistic contributions but also highlights his unique role in modern literature, where language transcends simple communication to explore profound existential questions.
Generating Multilingual Parallel Corpus Using Subtitles
Apr 11, 2018

Neural Machine Translation with its significant results, still has a great problem: lack or absence of parallel corpus for many languages. This article suggests a method for generating considerable amount of parallel corpus for any language pairs, extracted from open source materials existing on the Internet. Parallel corpus contents will be derived from video subtitles. It needs a set of video titles, with some attributes like release date, rating, duration and etc. Process of finding and downloading subtitle pairs for desired language pairs is automated by using a crawler. Finally sentence pairs will be extracted from synchronous dialogues in subtitles. The main problem of this method is unsynchronized subtitle pairs. Therefore subtitles will be verified before downloading. If two subtitle were not synchronized, then another subtitle of that video will be processed till it finds the matching subtitle. Using this approach gives ability to make context based parallel corpus through filtering videos by genre. Context based corpus can be used in complex translators which decode sentences by different networks after determining contents subject. Languages have many differences in their formal and informal styles, including words and syntax. Other advantage of this method is to make corpus of informal style of languages. Because most of movies dialogues are parts of a conversation. So they had informal style. This feature of generated corpus can be used in real-time translators to have more accurate conversation translations.