 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Multilingual Parallel Corpus Using Subtitles
Paper and Code

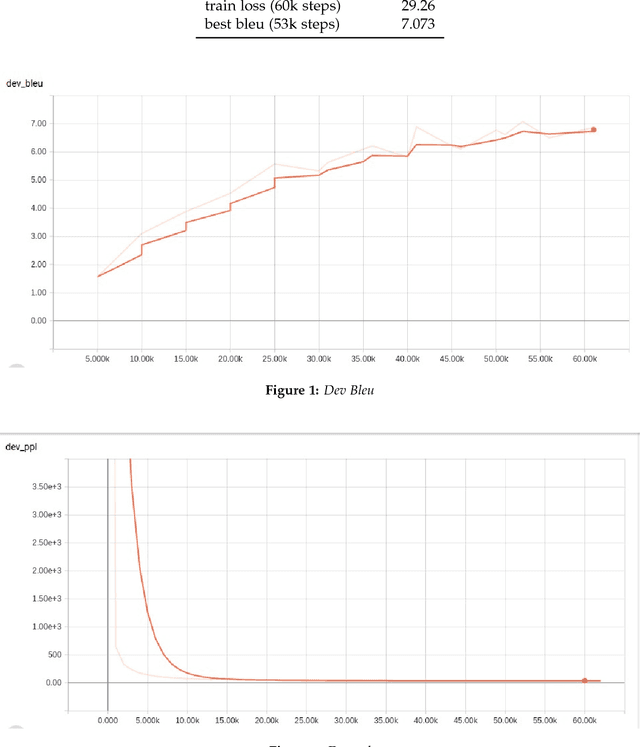

Neural Machine Translation with its significant results, still has a great problem: lack or absence of parallel corpus for many languages. This article suggests a method for generating considerable amount of parallel corpus for any language pairs, extracted from open source materials existing on the Internet. Parallel corpus contents will be derived from video subtitles. It needs a set of video titles, with some attributes like release date, rating, duration and etc. Process of finding and downloading subtitle pairs for desired language pairs is automated by using a crawler. Finally sentence pairs will be extracted from synchronous dialogues in subtitles. The main problem of this method is unsynchronized subtitle pairs. Therefore subtitles will be verified before downloading. If two subtitle were not synchronized, then another subtitle of that video will be processed till it finds the matching subtitle. Using this approach gives ability to make context based parallel corpus through filtering videos by genre. Context based corpus can be used in complex translators which decode sentences by different networks after determining contents subject. Languages have many differences in their formal and informal styles, including words and syntax. Other advantage of this method is to make corpus of informal style of languages. Because most of movies dialogues are parts of a conversation. So they had informal style. This feature of generated corpus can be used in real-time translators to have more accurate conversation translations.