 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVectorized Context-Aware Embeddings for GAT-Based Collaborative Filtering
Oct 30, 2025Recommender systems often struggle with data sparsity and cold-start scenarios, limiting their ability to provide accurate suggestions for new or infrequent users. This paper presents a Graph Attention Network (GAT) based Collaborative Filtering (CF) framework enhanced with Large Language Model (LLM) driven context aware embeddings. Specifically, we generate concise textual user profiles and unify item metadata (titles, genres, overviews) into rich textual embeddings, injecting these as initial node features in a bipartite user item graph. To further optimize ranking performance, we introduce a hybrid loss function that combines Bayesian Personalized Ranking (BPR) with a cosine similarity term and robust negative sampling, ensuring explicit negative feedback is distinguished from unobserved data. Experiments on the MovieLens 100k and 1M datasets show consistent improvements over state-of-the-art baselines in Precision, NDCG, and MAP while demonstrating robustness for users with limited interaction history. Ablation studies confirm the critical role of LLM-augmented embeddings and the cosine similarity term in capturing nuanced semantic relationships. Our approach effectively mitigates sparsity and cold-start limitations by integrating LLM-derived contextual understanding into graph-based architectures. Future directions include balancing recommendation accuracy with coverage and diversity, and introducing fairness-aware constraints and interpretability features to enhance system performance further.
Lusifer: LLM-based User SImulated Feedback Environment for online Recommender systems
May 22, 2024Training reinforcement learning-based recommender systems are often hindered by the lack of dynamic and realistic user interactions. Lusifer, a novel environment leveraging Large Language Models (LLMs), addresses this limitation by generating simulated user feedback. It synthesizes user profiles and interaction histories to simulate responses and behaviors toward recommended items. In addition, user profiles are updated after each rating to reflect evolving user characteristics. Using the MovieLens100K dataset as proof of concept, Lusifer demonstrates accurate emulation of user behavior and preferences. This paper presents Lusifer's operational pipeline, including prompt generation and iterative user profile updates. While validating Lusifer's ability to produce realistic dynamic feedback, future research could utilize this environment to train reinforcement learning systems, offering a scalable and adjustable framework for user simulation in online recommender systems.
Iranian Modal Music (Dastgah) detection using deep neural networks
Mar 29, 2022


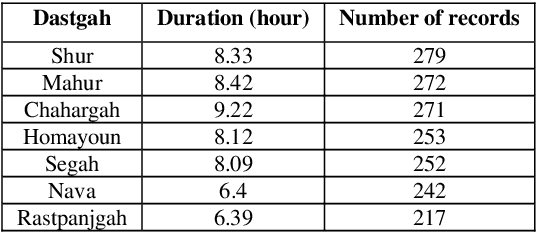
In this work, several deep neural networks are implemented to recognize Iranian modal music in seven high correlated categories. The best model, which achieved 92 percent overall accuracy, uses an architecture inspired by autoencoder, including BiLSTM and BiGRU layers. This model is trained using the Nava dataset, with 1786 records and up to 55 hours of music played solo by Kamanche, Tar, Setar, Reed, and Santoor (Dulcimer). Features that have been studied through this research contain MFCC, Chroma CENS, and Mel spectrogram. The results indicate that MFCC carries more valuable information for detecting Iranian modal music (Dastgah) than other sound representations. Moreover, the architecture, which is inspired by autoencoder, is robust in distinguishing high correlated data like Dastgahs. It also shows that because of the precise order in Iranian Dastgah Music, Bidirectional Recurrent networks are more efficient than any other networks that have been implemented in this study.