 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Sophisticated Framework for the Accurate Detection of Phishing Websites
Mar 13, 2024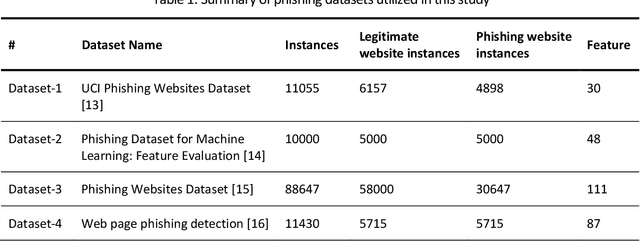
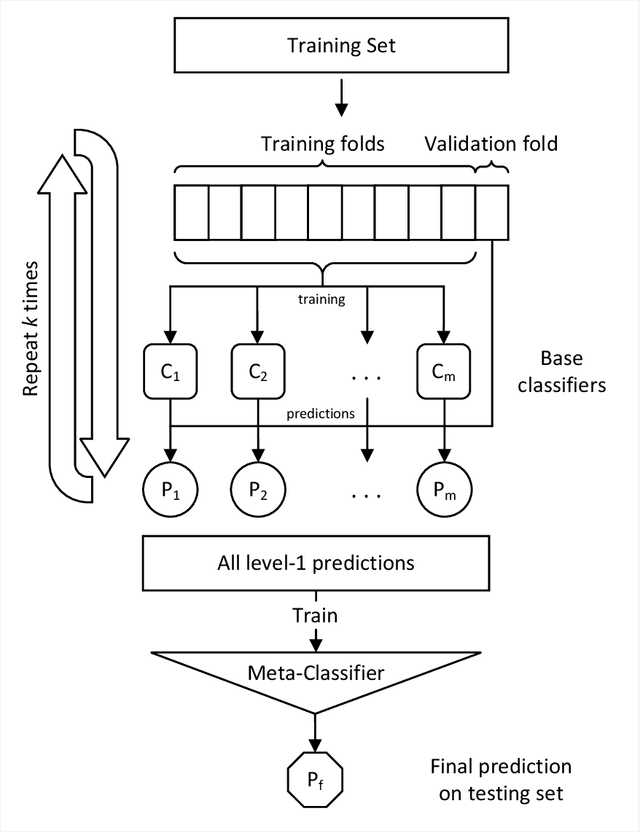

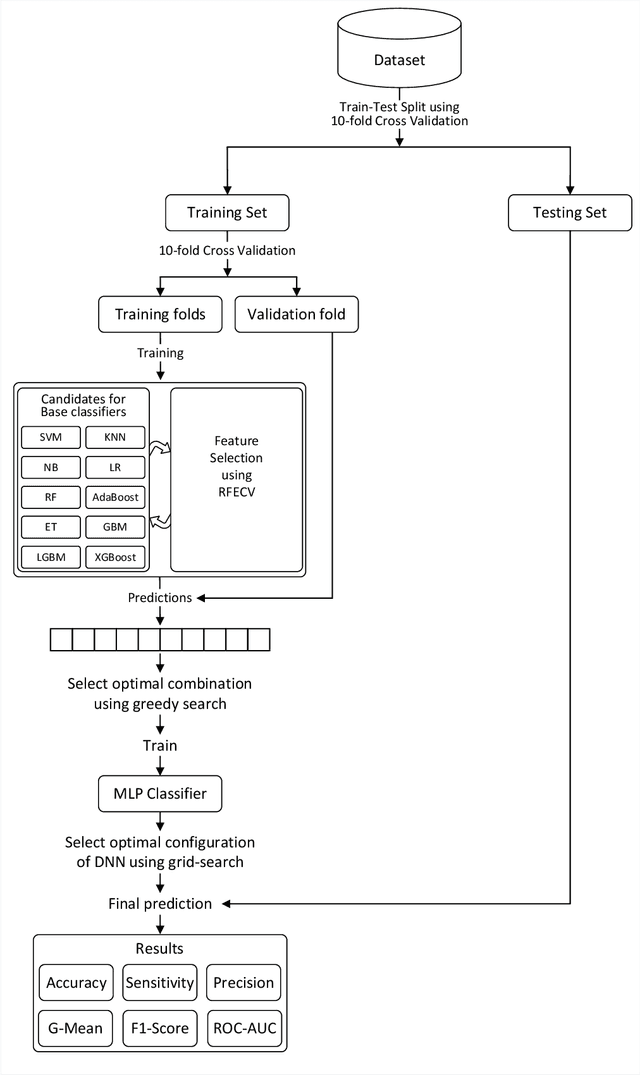
Phishing is an increasingly sophisticated form of cyberattack that is inflicting huge financial damage to corporations throughout the globe while also jeopardizing individuals' privacy. Attackers are constantly devising new methods of launching such assaults and detecting them has become a daunting task. Many different techniques have been suggested, each with its own pros and cons. While machine learning-based techniques have been most successful in identifying such attacks, they continue to fall short in terms of performance and generalizability. This paper proposes a comprehensive methodology for detecting phishing websites. The goal is to design a system that is capable of accurately distinguishing phishing websites from legitimate ones and provides generalized performance over a broad variety of datasets. A combination of feature selection, greedy algorithm, cross-validation, and deep learning methods have been utilized to construct a sophisticated stacking ensemble classifier. Extensive experimentation on four different phishing datasets was conducted to evaluate the performance of the proposed technique. The proposed algorithm outperformed the other existing phishing detection models obtaining accuracy of 97.49%, 98.23%, 97.48%, and 98.20% on dataset-1 (UCI Phishing Websites Dataset), dataset-2 (Phishing Dataset for Machine Learning: Feature Evaluation), dataset-3 (Phishing Websites Dataset), and dataset-4 (Web page phishing detection), respectively. The high accuracy values obtained across all datasets imply the models' generalizability and effectiveness in the accurate identification of phishing websites.
An Empirical Analysis of the Efficacy of Different Sampling Techniques for Imbalanced Classification
Aug 25, 2022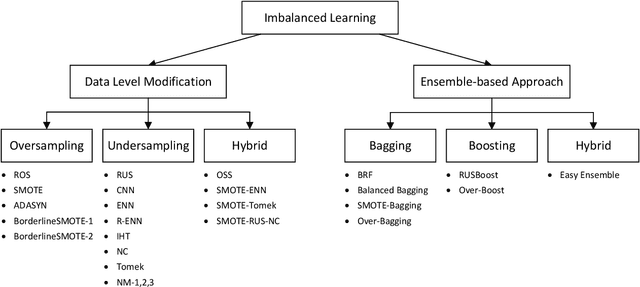
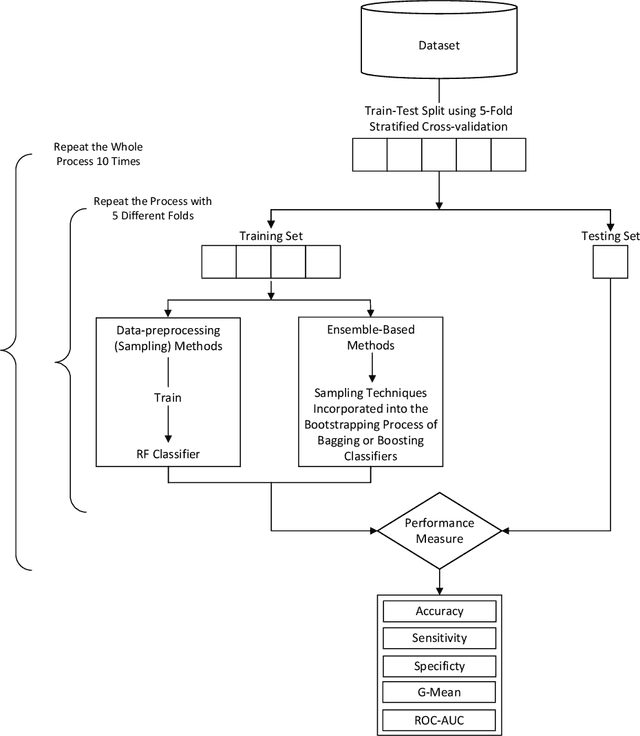
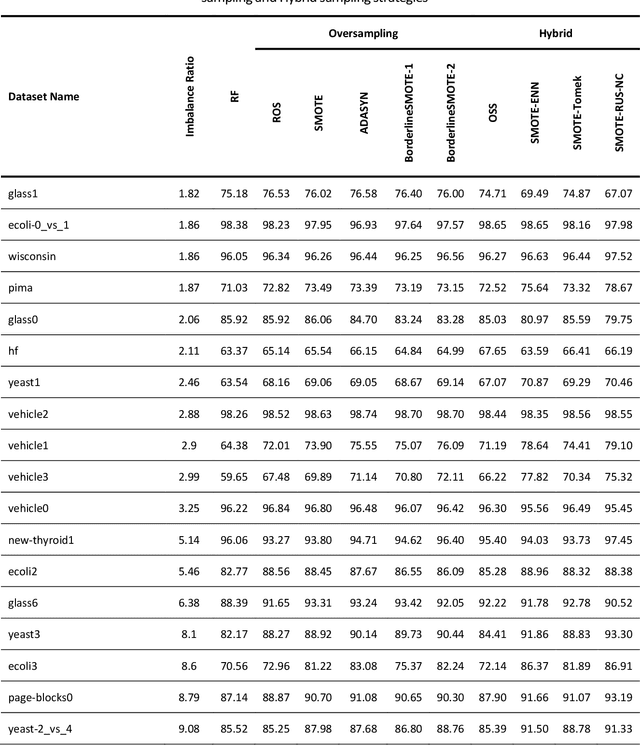
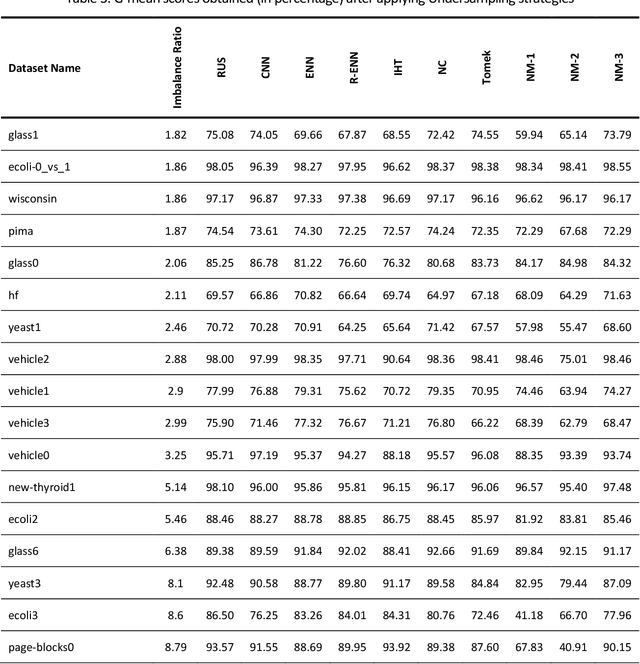
Learning from imbalanced data is a challenging task. Standard classification algorithms tend to perform poorly when trained on imbalanced data. Some special strategies need to be adopted, either by modifying the data distribution or by redesigning the underlying classification algorithm to achieve desirable performance. The prevalence of imbalance in real-world datasets has led to the creation of a multitude of strategies for the class imbalance issue. However, not all the strategies are useful or provide good performance in different imbalance scenarios. There are numerous approaches to dealing with imbalanced data, but the efficacy of such techniques or an experimental comparison among those techniques has not been conducted. In this study, we present a comprehensive analysis of 26 popular sampling techniques to understand their effectiveness in dealing with imbalanced data. Rigorous experiments have been conducted on 50 datasets with different degrees of imbalance to thoroughly investigate the performance of these techniques. A detailed discussion of the advantages and limitations of the techniques, as well as how to overcome such limitations, has been presented. We identify some critical factors that affect the sampling strategies and provide recommendations on how to choose an appropriate sampling technique for a particular application.
A Novel Hybrid Sampling Framework for Imbalanced Learning
Aug 20, 2022



Class imbalance is a frequently occurring scenario in classification tasks. Learning from imbalanced data poses a major challenge, which has instigated a lot of research in this area. Data preprocessing using sampling techniques is a standard approach to deal with the imbalance present in the data. Since standard classification algorithms do not perform well on imbalanced data, the dataset needs to be adequately balanced before training. This can be accomplished by oversampling the minority class or undersampling the majority class. In this study, a novel hybrid sampling algorithm has been proposed. To overcome the limitations of the sampling techniques while ensuring the quality of the retained sampled dataset, a sophisticated framework has been developed to properly combine three different sampling techniques. Neighborhood Cleaning rule is first applied to reduce the imbalance. Random undersampling is then strategically coupled with the SMOTE algorithm to obtain an optimal balance in the dataset. This proposed hybrid methodology, termed "SMOTE-RUS-NC", has been compared with other state-of-the-art sampling techniques. The strategy is further incorporated into the ensemble learning framework to obtain a more robust classification algorithm, termed "SRN-BRF". Rigorous experimentation has been conducted on 26 imbalanced datasets with varying degrees of imbalance. In virtually all datasets, the proposed two algorithms outperformed existing sampling strategies, in many cases by a substantial margin. Especially in highly imbalanced datasets where popular sampling techniques failed utterly, they achieved unparalleled performance. The superior results obtained demonstrate the efficacy of the proposed models and their potential to be powerful sampling algorithms in imbalanced domain.