 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Analysis of the Efficacy of Different Sampling Techniques for Imbalanced Classification
Paper and Code
Aug 25, 2022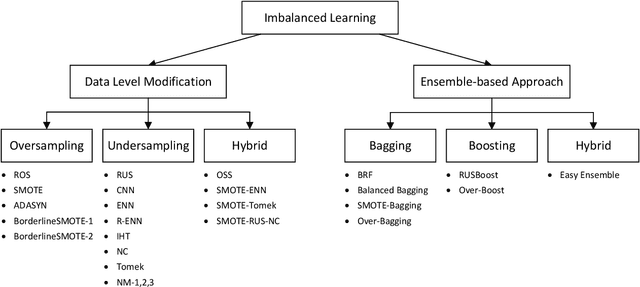
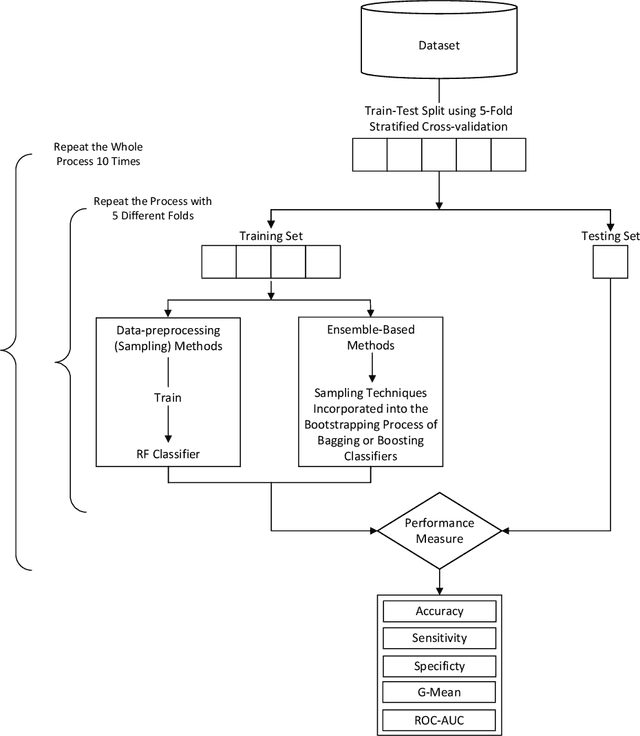
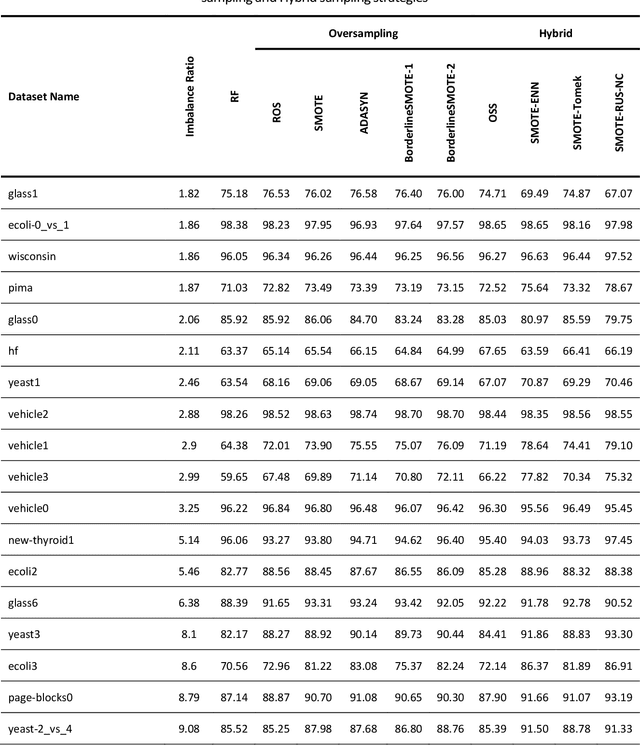
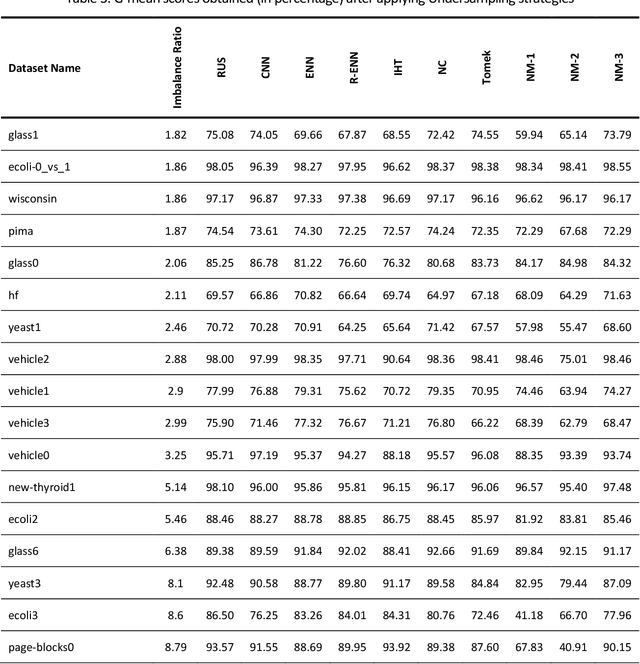
Learning from imbalanced data is a challenging task. Standard classification algorithms tend to perform poorly when trained on imbalanced data. Some special strategies need to be adopted, either by modifying the data distribution or by redesigning the underlying classification algorithm to achieve desirable performance. The prevalence of imbalance in real-world datasets has led to the creation of a multitude of strategies for the class imbalance issue. However, not all the strategies are useful or provide good performance in different imbalance scenarios. There are numerous approaches to dealing with imbalanced data, but the efficacy of such techniques or an experimental comparison among those techniques has not been conducted. In this study, we present a comprehensive analysis of 26 popular sampling techniques to understand their effectiveness in dealing with imbalanced data. Rigorous experiments have been conducted on 50 datasets with different degrees of imbalance to thoroughly investigate the performance of these techniques. A detailed discussion of the advantages and limitations of the techniques, as well as how to overcome such limitations, has been presented. We identify some critical factors that affect the sampling strategies and provide recommendations on how to choose an appropriate sampling technique for a particular application.