 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn End-to-End Deep Learning Framework for Arsenicosis Diagnosis Using Mobile-Captured Skin Images
Sep 10, 2025Background: Arsenicosis is a serious public health concern in South and Southeast Asia, primarily caused by long-term consumption of arsenic-contaminated water. Its early cutaneous manifestations are clinically significant but often underdiagnosed, particularly in rural areas with limited access to dermatologists. Automated, image-based diagnostic solutions can support early detection and timely interventions. Methods: In this study, we propose an end-to-end framework for arsenicosis diagnosis using mobile phone-captured skin images. A dataset comprising 20 classes and over 11000 images of arsenic-induced and other dermatological conditions was curated. Multiple deep learning architectures, including convolutional neural networks (CNNs) and Transformer-based models, were benchmarked for arsenicosis detection. Model interpretability was integrated via LIME and Grad-CAM, while deployment feasibility was demonstrated through a web-based diagnostic tool. Results: Transformer-based models significantly outperformed CNNs, with the Swin Transformer achieving the best results (86\\% accuracy). LIME and Grad-CAM visualizations confirmed that the models attended to lesion-relevant regions, increasing clinical transparency and aiding in error analysis. The framework also demonstrated strong performance on external validation samples, confirming its ability to generalize beyond the curated dataset. Conclusion: The proposed framework demonstrates the potential of deep learning for non-invasive, accessible, and explainable diagnosis of arsenicosis from mobile-acquired images. By enabling reliable image-based screening, it can serve as a practical diagnostic aid in rural and resource-limited communities, where access to dermatologists is scarce, thereby supporting early detection and timely intervention.
Toward Accessible Dermatology: Skin Lesion Classification Using Deep Learning Models on Mobile-Acquired Images
Sep 05, 2025



Skin diseases are among the most prevalent health concerns worldwide, yet conventional diagnostic methods are often costly, complex, and unavailable in low-resource settings. Automated classification using deep learning has emerged as a promising alternative, but existing studies are mostly limited to dermoscopic datasets and a narrow range of disease classes. In this work, we curate a large dataset of over 50 skin disease categories captured with mobile devices, making it more representative of real-world conditions. We evaluate multiple convolutional neural networks and Transformer-based architectures, demonstrating that Transformer models, particularly the Swin Transformer, achieve superior performance by effectively capturing global contextual features. To enhance interpretability, we incorporate Gradient-weighted Class Activation Mapping (Grad-CAM), which highlights clinically relevant regions and provides transparency in model predictions. Our results underscore the potential of Transformer-based approaches for mobile-acquired skin lesion classification, paving the way toward accessible AI-assisted dermatological screening and early diagnosis in resource-limited environments.
iBRF: Improved Balanced Random Forest Classifier
Mar 14, 2024Class imbalance poses a major challenge in different classification tasks, which is a frequently occurring scenario in many real-world applications. Data resampling is considered to be the standard approach to address this issue. The goal of the technique is to balance the class distribution by generating new samples or eliminating samples from the data. A wide variety of sampling techniques have been proposed over the years to tackle this challenging problem. Sampling techniques can also be incorporated into the ensemble learning framework to obtain more generalized prediction performance. Balanced Random Forest (BRF) and SMOTE-Bagging are some of the popular ensemble approaches. In this study, we propose a modification to the BRF classifier to enhance the prediction performance. In the original algorithm, the Random Undersampling (RUS) technique was utilized to balance the bootstrap samples. However, randomly eliminating too many samples from the data leads to significant data loss, resulting in a major decline in performance. We propose to alleviate the scenario by incorporating a novel hybrid sampling approach to balance the uneven class distribution in each bootstrap sub-sample. Our proposed hybrid sampling technique, when incorporated into the framework of the Random Forest classifier, termed as iBRF: improved Balanced Random Forest classifier, achieves better prediction performance than other sampling techniques used in imbalanced classification tasks. Experiments were carried out on 44 imbalanced datasets on which the original BRF classifier produced an average MCC score of 47.03% and an F1 score of 49.09%. Our proposed algorithm outperformed the approach by producing a far better MCC score of 53.04% and an F1 score of 55%. The results obtained signify the superiority of the iBRF algorithm and its potential to be an effective sampling technique in imbalanced learning.
A Sophisticated Framework for the Accurate Detection of Phishing Websites
Mar 13, 2024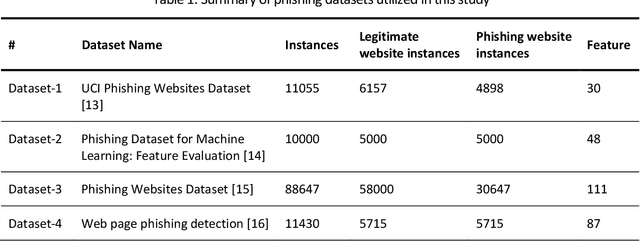
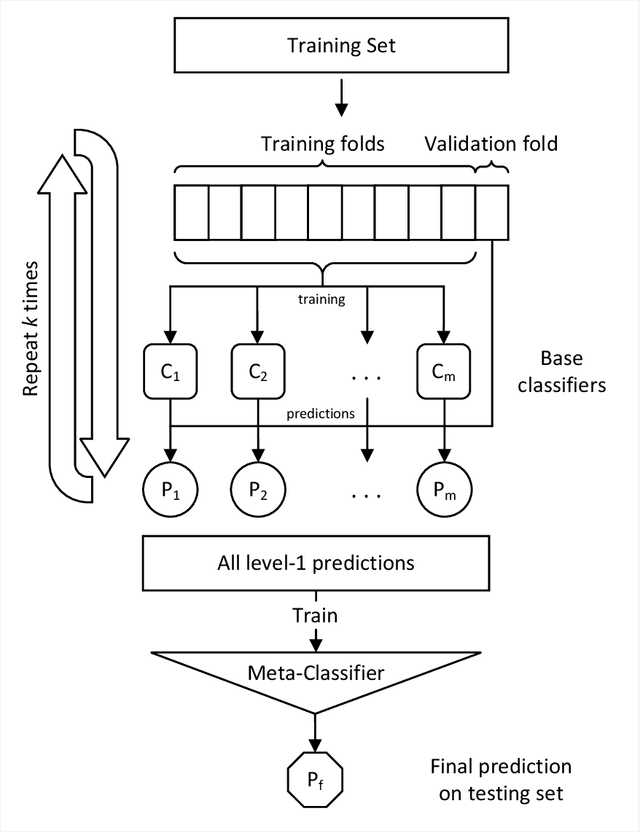

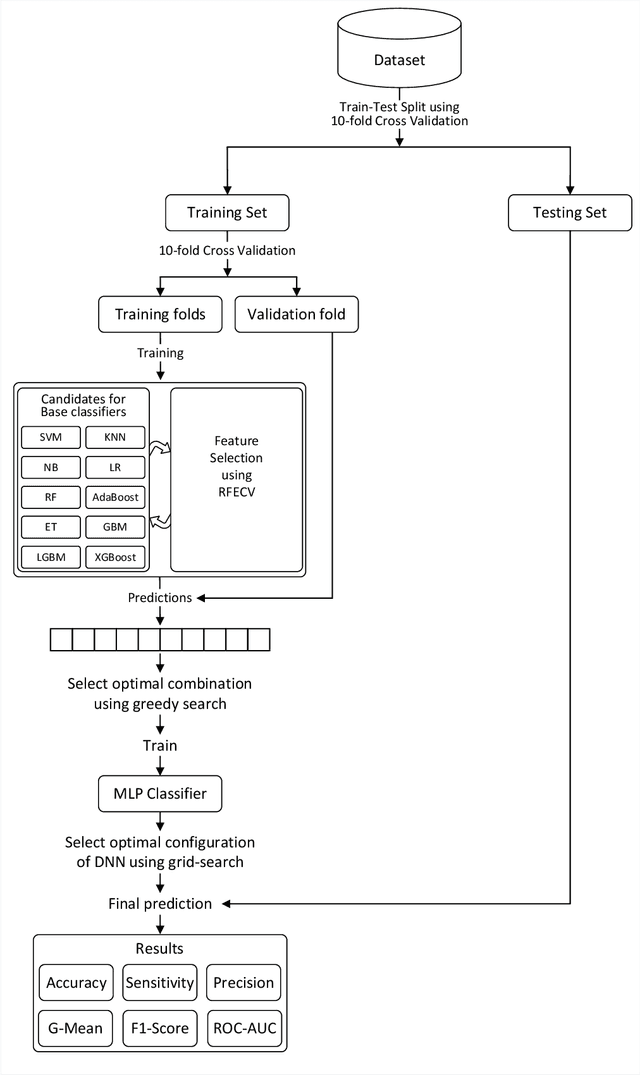
Phishing is an increasingly sophisticated form of cyberattack that is inflicting huge financial damage to corporations throughout the globe while also jeopardizing individuals' privacy. Attackers are constantly devising new methods of launching such assaults and detecting them has become a daunting task. Many different techniques have been suggested, each with its own pros and cons. While machine learning-based techniques have been most successful in identifying such attacks, they continue to fall short in terms of performance and generalizability. This paper proposes a comprehensive methodology for detecting phishing websites. The goal is to design a system that is capable of accurately distinguishing phishing websites from legitimate ones and provides generalized performance over a broad variety of datasets. A combination of feature selection, greedy algorithm, cross-validation, and deep learning methods have been utilized to construct a sophisticated stacking ensemble classifier. Extensive experimentation on four different phishing datasets was conducted to evaluate the performance of the proposed technique. The proposed algorithm outperformed the other existing phishing detection models obtaining accuracy of 97.49%, 98.23%, 97.48%, and 98.20% on dataset-1 (UCI Phishing Websites Dataset), dataset-2 (Phishing Dataset for Machine Learning: Feature Evaluation), dataset-3 (Phishing Websites Dataset), and dataset-4 (Web page phishing detection), respectively. The high accuracy values obtained across all datasets imply the models' generalizability and effectiveness in the accurate identification of phishing websites.
An Explainable Machine Learning Framework for the Accurate Diagnosis of Ovarian Cancer
Dec 11, 2023



Ovarian cancer (OC) is one of the most prevalent types of cancer in women. Early and accurate diagnosis is crucial for the survival of the patients. However, the majority of women are diagnosed in advanced stages due to the lack of effective biomarkers and accurate screening tools. While previous studies sought a common biomarker, our study suggests different biomarkers for the premenopausal and postmenopausal populations. This can provide a new perspective in the search for novel predictors for the effective diagnosis of OC. Lack of explainability is one major limitation of current AI systems. The stochastic nature of the ML algorithms raises concerns about the reliability of the system as it is difficult to interpret the reasons behind the decisions. To increase the trustworthiness and accountability of the diagnostic system as well as to provide transparency and explanations behind the predictions, explainable AI has been incorporated into the ML framework. SHAP is employed to quantify the contributions of the selected biomarkers and determine the most discriminative features. A hybrid decision support system has been established that can eliminate the bottlenecks caused by the black-box nature of the ML algorithms providing a safe and trustworthy AI tool. The diagnostic accuracy obtained from the proposed system outperforms the existing methods as well as the state-of-the-art ROMA algorithm by a substantial margin which signifies its potential to be an effective tool in the differential diagnosis of OC.
A Hybrid Transfer Learning Assisted Decision Support System for Accurate Prediction of Alzheimer Disease
Oct 13, 2023

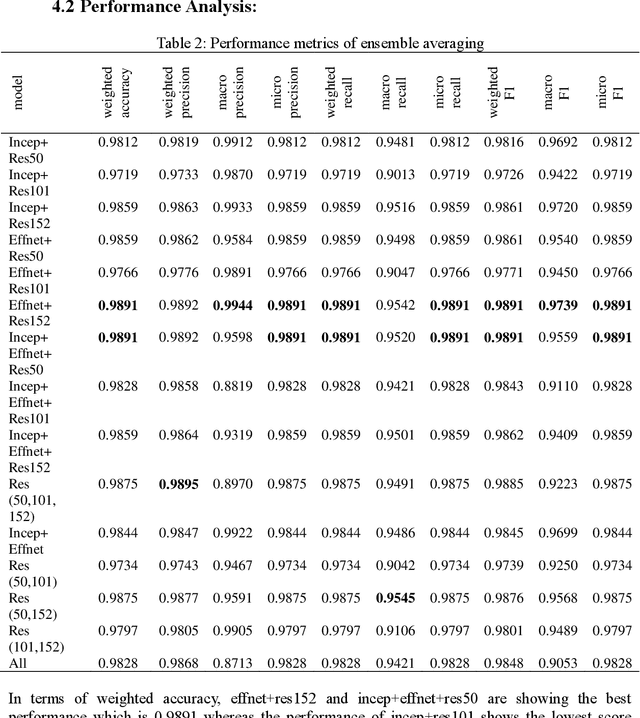

Alzheimer's disease (AD) is the most common long-term illness in elderly people. In recent years, deep learning has become popular in the area of medical imaging and has had a lot of success there. It has become the most effective way to look at medical images. When it comes to detecting AD, the deep neural model is more accurate and effective than general machine learning. Our research contributes to the development of a more comprehensive understanding and detection of the disease by identifying four distinct classes that are predictive of AD with a high weighted accuracy of 98.91%. A unique strategy has been proposed to improve the accuracy of the imbalance dataset classification problem via the combination of ensemble averaging models and five different transfer learning models in this study. EfficientNetB0+Resnet152(effnet+res152) and InceptionV3+EfficientNetB0+Resnet50(incep+effnet+res50) models have been fine-tuned and have reached the highest weighted accuracy for multi-class AD stage classifications.
An Empirical Analysis of the Efficacy of Different Sampling Techniques for Imbalanced Classification
Aug 25, 2022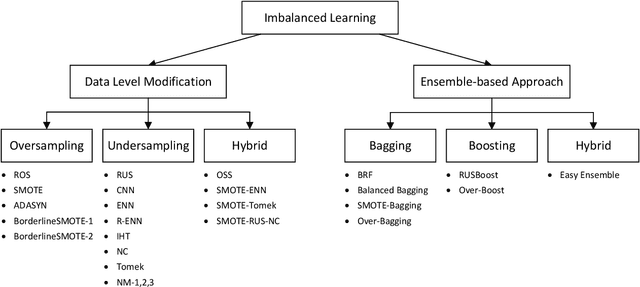
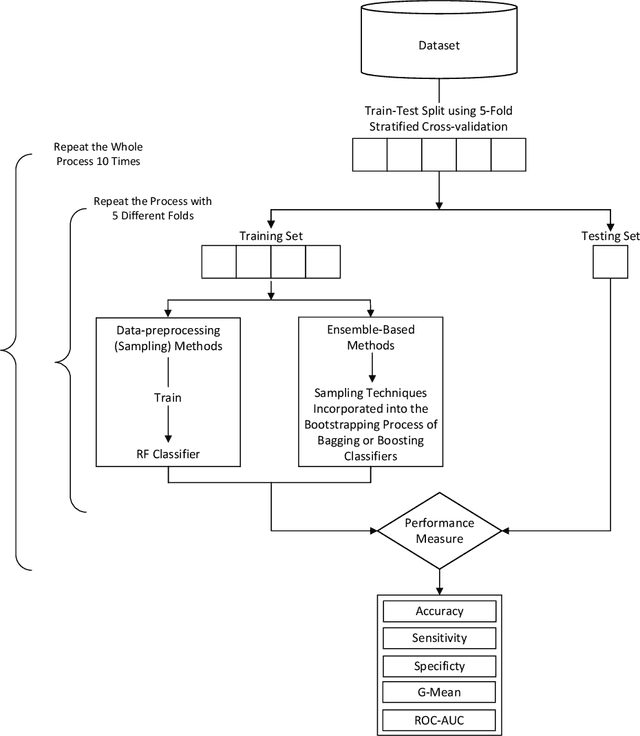
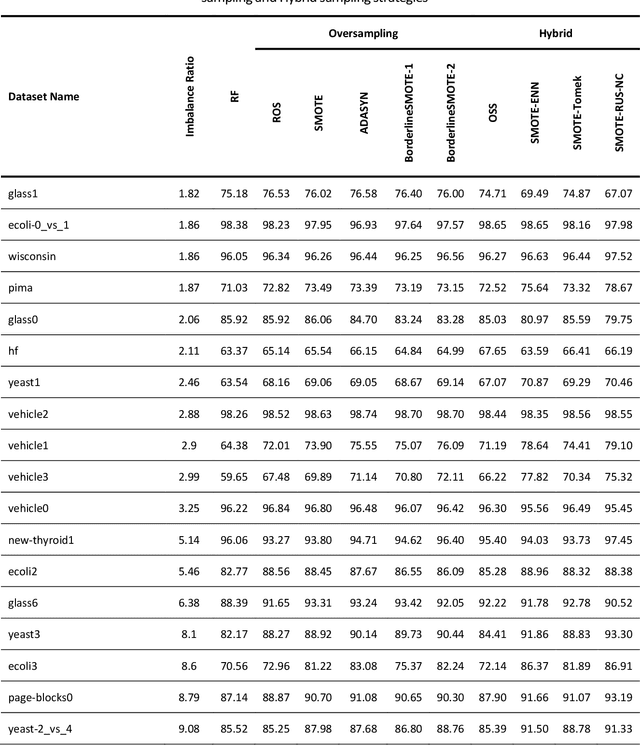
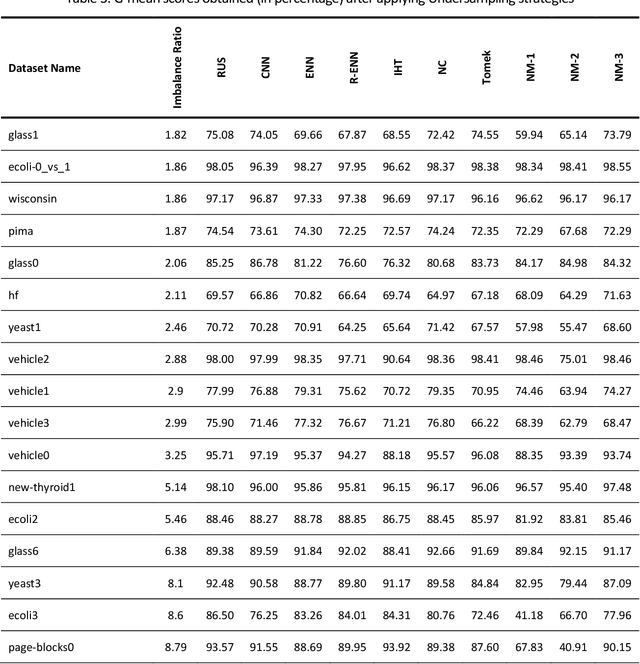
Learning from imbalanced data is a challenging task. Standard classification algorithms tend to perform poorly when trained on imbalanced data. Some special strategies need to be adopted, either by modifying the data distribution or by redesigning the underlying classification algorithm to achieve desirable performance. The prevalence of imbalance in real-world datasets has led to the creation of a multitude of strategies for the class imbalance issue. However, not all the strategies are useful or provide good performance in different imbalance scenarios. There are numerous approaches to dealing with imbalanced data, but the efficacy of such techniques or an experimental comparison among those techniques has not been conducted. In this study, we present a comprehensive analysis of 26 popular sampling techniques to understand their effectiveness in dealing with imbalanced data. Rigorous experiments have been conducted on 50 datasets with different degrees of imbalance to thoroughly investigate the performance of these techniques. A detailed discussion of the advantages and limitations of the techniques, as well as how to overcome such limitations, has been presented. We identify some critical factors that affect the sampling strategies and provide recommendations on how to choose an appropriate sampling technique for a particular application.
A Novel Hybrid Sampling Framework for Imbalanced Learning
Aug 20, 2022



Class imbalance is a frequently occurring scenario in classification tasks. Learning from imbalanced data poses a major challenge, which has instigated a lot of research in this area. Data preprocessing using sampling techniques is a standard approach to deal with the imbalance present in the data. Since standard classification algorithms do not perform well on imbalanced data, the dataset needs to be adequately balanced before training. This can be accomplished by oversampling the minority class or undersampling the majority class. In this study, a novel hybrid sampling algorithm has been proposed. To overcome the limitations of the sampling techniques while ensuring the quality of the retained sampled dataset, a sophisticated framework has been developed to properly combine three different sampling techniques. Neighborhood Cleaning rule is first applied to reduce the imbalance. Random undersampling is then strategically coupled with the SMOTE algorithm to obtain an optimal balance in the dataset. This proposed hybrid methodology, termed "SMOTE-RUS-NC", has been compared with other state-of-the-art sampling techniques. The strategy is further incorporated into the ensemble learning framework to obtain a more robust classification algorithm, termed "SRN-BRF". Rigorous experimentation has been conducted on 26 imbalanced datasets with varying degrees of imbalance. In virtually all datasets, the proposed two algorithms outperformed existing sampling strategies, in many cases by a substantial margin. Especially in highly imbalanced datasets where popular sampling techniques failed utterly, they achieved unparalleled performance. The superior results obtained demonstrate the efficacy of the proposed models and their potential to be powerful sampling algorithms in imbalanced domain.