 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Investigation on Machine Learning Predictive Accuracy Improvement and Uncertainty Reduction using VAE-based Data Augmentation
Oct 24, 2024



The confluence of ultrafast computers with large memory, rapid progress in Machine Learning (ML) algorithms, and the availability of large datasets place multiple engineering fields at the threshold of dramatic progress. However, a unique challenge in nuclear engineering is data scarcity because experimentation on nuclear systems is usually more expensive and time-consuming than most other disciplines. One potential way to resolve the data scarcity issue is deep generative learning, which uses certain ML models to learn the underlying distribution of existing data and generate synthetic samples that resemble the real data. In this way, one can significantly expand the dataset to train more accurate predictive ML models. In this study, our objective is to evaluate the effectiveness of data augmentation using variational autoencoder (VAE)-based deep generative models. We investigated whether the data augmentation leads to improved accuracy in the predictions of a deep neural network (DNN) model trained using the augmented data. Additionally, the DNN prediction uncertainties are quantified using Bayesian Neural Networks (BNN) and conformal prediction (CP) to assess the impact on predictive uncertainty reduction. To test the proposed methodology, we used TRACE simulations of steady-state void fraction data based on the NUPEC Boiling Water Reactor Full-size Fine-mesh Bundle Test (BFBT) benchmark. We found that augmenting the training dataset using VAEs has improved the DNN model's predictive accuracy, improved the prediction confidence intervals, and reduced the prediction uncertainties.
Predicting Critical Heat Flux with Uncertainty Quantification and Domain Generalization Using Conditional Variational Autoencoders and Deep Neural Networks
Sep 09, 2024Deep generative models (DGMs) have proven to be powerful in generating realistic data samples. Their capability to learn the underlying distribution of a dataset enable them to generate synthetic data samples that closely resemble the original training dataset, thus addressing the challenge of data scarcity. In this work, we investigated the capabilities of DGMs by developing a conditional variational autoencoder (CVAE) model to augment the critical heat flux (CHF) measurement data that was used to generate the 2006 Groeneveld lookup table. To determine how this approach compared to traditional methods, a fine-tuned deep neural network (DNN) regression model was created and evaluated with the same dataset. Both the CVAE and DNN models achieved small mean absolute relative errors, with the CVAE model maintaining more favorable results. To quantify the uncertainty in the model's predictions, uncertainty quantification (UQ) was performed with repeated sampling of the CVAE model and ensembling of the DNN model. Following UQ, the DNN ensemble notably improved performance when compared to the baseline DNN model, while the CVAE model achieved similar results to its non-UQ results. The CVAE model was shown to have significantly less variability and a higher confidence after assessment of the prediction-wise relative standard deviations. Evaluating domain generalization, both models achieved small mean error values when predicting both inside and outside the training domain, with predictions outside the training domain showing slightly larger errors. Overall, the CVAE model was comparable to the DNN regression model in predicting CHF values but with better uncertainty behavior.
Data-Driven Prediction and Uncertainty Quantification of PWR Crud-Induced Power Shift Using Convolutional Neural Networks
Jun 27, 2024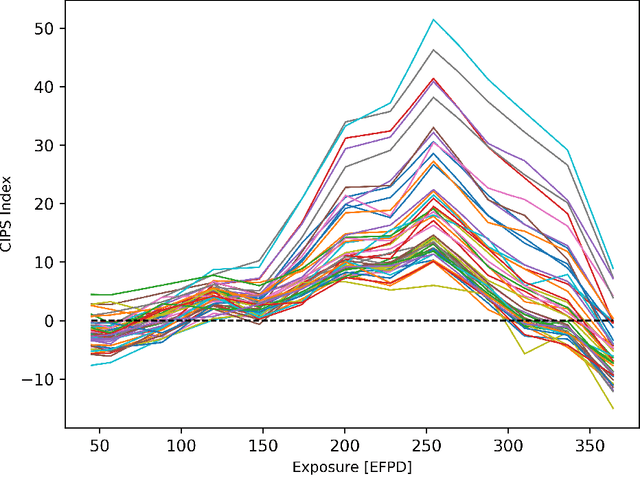
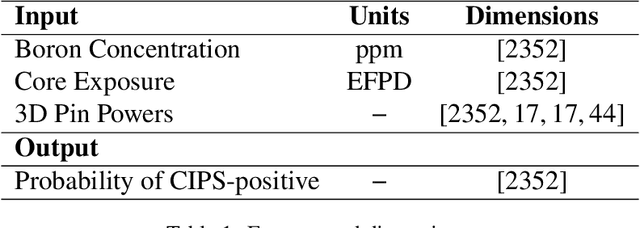
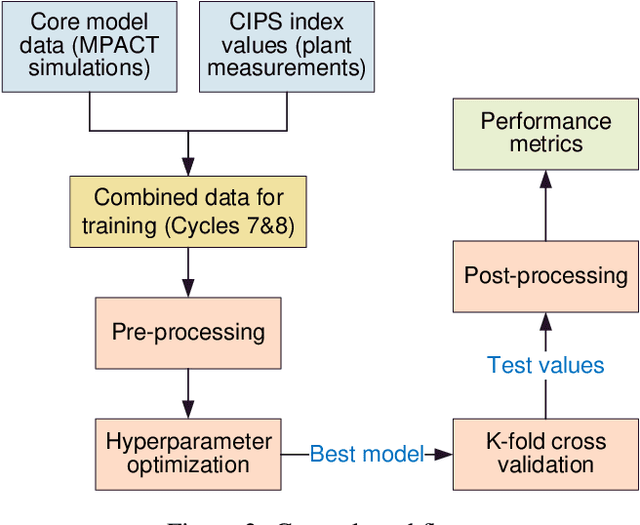

The development of Crud-Induced Power Shift (CIPS) is an operational challenge in Pressurized Water Reactors that is due to the development of crud on the fuel rod cladding. The available predictive tools developed previously, usually based on fundamental physics, are computationally expensive and have shown differing degrees of accuracy. This work proposes a completely top-down approach to predict CIPS instances on an assembly level with reactor-specific calibration built-in. Built using artificial neural networks, this work uses a three-dimensional convolutional approach to leverage the image-like layout of the input data. As a classifier, the convolutional neural network model predicts whether a given assembly will experience CIPS as well as the time of occurrence during a given cycle. This surrogate model is both trained and tested using a combination of calculated core model parameters and measured plant data from Unit 1 of the Catawba Nuclear Station. After the evaluation of its performance using various metrics, Monte Carlo dropout is employed for extensive uncertainty quantification of the model predictions. The results indicate that this methodology could be a viable approach in predicting CIPS with an assembly-level resolution across both clean and afflicted cycles, while using limited computational resources.
Deep Generative Modeling-based Data Augmentation with Demonstration using the BFBT Benchmark Void Fraction Datasets
Aug 19, 2023Deep learning (DL) has achieved remarkable successes in many disciplines such as computer vision and natural language processing due to the availability of ``big data''. However, such success cannot be easily replicated in many nuclear engineering problems because of the limited amount of training data, especially when the data comes from high-cost experiments. To overcome such a data scarcity issue, this paper explores the applications of deep generative models (DGMs) that have been widely used for image data generation to scientific data augmentation. DGMs, such as generative adversarial networks (GANs), normalizing flows (NFs), variational autoencoders (VAEs), and conditional VAEs (CVAEs), can be trained to learn the underlying probabilistic distribution of the training dataset. Once trained, they can be used to generate synthetic data that are similar to the training data and significantly expand the dataset size. By employing DGMs to augment TRACE simulated data of the steady-state void fractions based on the NUPEC Boiling Water Reactor Full-size Fine-mesh Bundle Test (BFBT) benchmark, this study demonstrates that VAEs, CVAEs, and GANs have comparable generative performance with similar errors in the synthetic data, with CVAEs achieving the smallest errors. The findings shows that DGMs have a great potential to augment scientific data in nuclear engineering, which proves effective for expanding the training dataset and enabling other DL models to be trained more accurately.