 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-dimensional multiple imputation (HDMI) for partially observed confounders including natural language processing-derived auxiliary covariates
May 17, 2024Multiple imputation (MI) models can be improved by including auxiliary covariates (AC), but their performance in high-dimensional data is not well understood. We aimed to develop and compare high-dimensional MI (HDMI) approaches using structured and natural language processing (NLP)-derived AC in studies with partially observed confounders. We conducted a plasmode simulation study using data from opioid vs. non-steroidal anti-inflammatory drug (NSAID) initiators (X) with observed serum creatinine labs (Z2) and time-to-acute kidney injury as outcome. We simulated 100 cohorts with a null treatment effect, including X, Z2, atrial fibrillation (U), and 13 other investigator-derived confounders (Z1) in the outcome generation. We then imposed missingness (MZ2) on 50% of Z2 measurements as a function of Z2 and U and created different HDMI candidate AC using structured and NLP-derived features. We mimicked scenarios where U was unobserved by omitting it from all AC candidate sets. Using LASSO, we data-adaptively selected HDMI covariates associated with Z2 and MZ2 for MI, and with U to include in propensity score models. The treatment effect was estimated following propensity score matching in MI datasets and we benchmarked HDMI approaches against a baseline imputation and complete case analysis with Z1 only. HDMI using claims data showed the lowest bias (0.072). Combining claims and sentence embeddings led to an improvement in the efficiency displaying the lowest root-mean-squared-error (0.173) and coverage (94%). NLP-derived AC alone did not perform better than baseline MI. HDMI approaches may decrease bias in studies with partially observed confounders where missingness depends on unobserved factors.
Social Vehicle Swarms: A Novel Perspective on Social-aware Vehicular Communication Architecture
Oct 29, 2018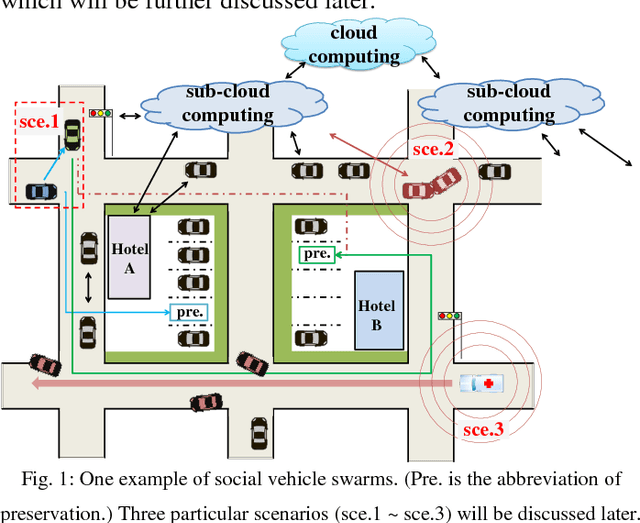
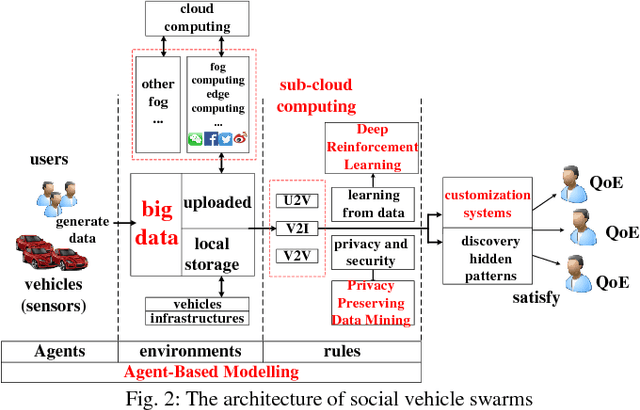
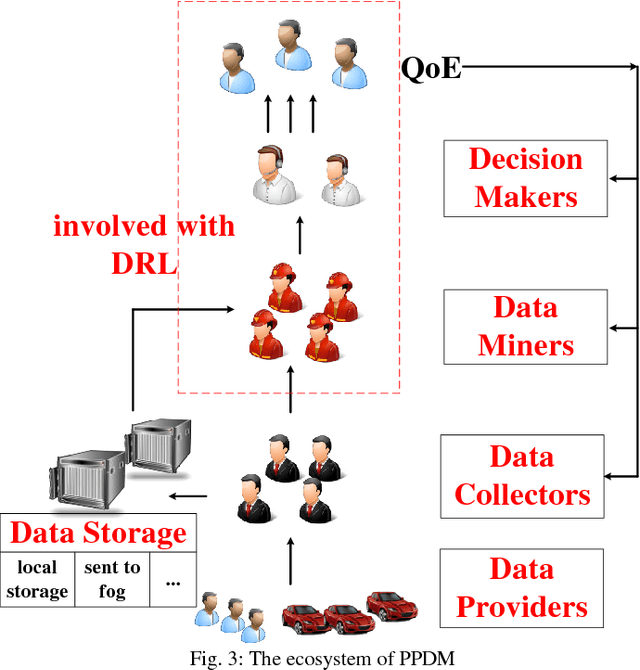
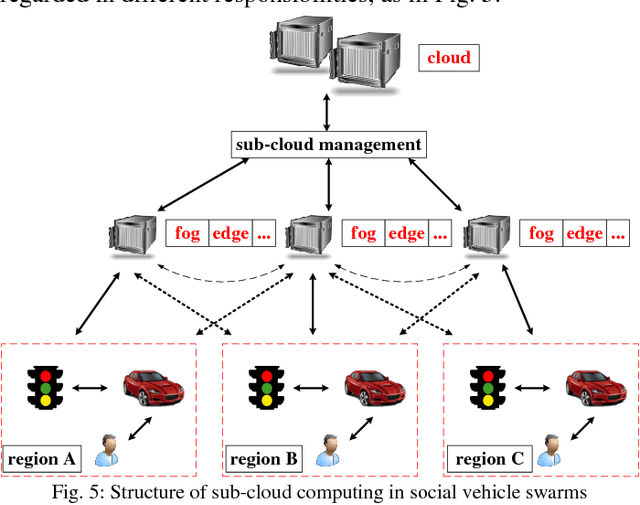
Internet of vehicles is a promising area related to D2D communication and internet of things. We present a novel perspective for vehicular communications, social vehicle swarms, to study and analyze socially aware internet of vehicles with the assistance of an agent-based model intended to reveal hidden patterns behind superficial data. After discussing its components, namely its agents, environments, and rules, we introduce supportive technology and methods, deep reinforcement learning, privacy preserving data mining and sub-cloud computing, in order to detect the most significant and interesting information for each individual effectively, which is the key desire. Finally, several relevant research topics and challenges are discussed.