 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnriched Functional Tree-Based Classifiers: A Novel Approach Leveraging Derivatives and Geometric Features
Sep 26, 2024



The positioning of this research falls within the scalar-on-function classification literature, a field of significant interest across various domains, particularly in statistics, mathematics, and computer science. This study introduces an advanced methodology for supervised classification by integrating Functional Data Analysis (FDA) with tree-based ensemble techniques for classifying high-dimensional time series. The proposed framework, Enriched Functional Tree-Based Classifiers (EFTCs), leverages derivative and geometric features, benefiting from the diversity inherent in ensemble methods to further enhance predictive performance and reduce variance. While our approach has been tested on the enrichment of Functional Classification Trees (FCTs), Functional K-NN (FKNN), Functional Random Forest (FRF), Functional XGBoost (FXGB), and Functional LightGBM (FLGBM), it could be extended to other tree-based and non-tree-based classifiers, with appropriate considerations emerging from this investigation. Through extensive experimental evaluations on seven real-world datasets and six simulated scenarios, this proposal demonstrates fascinating improvements over traditional approaches, providing new insights into the application of FDA in complex, high-dimensional learning problems.
Randomized Spline Trees for Functional Data Classification: Theory and Application to Environmental Time Series
Sep 12, 2024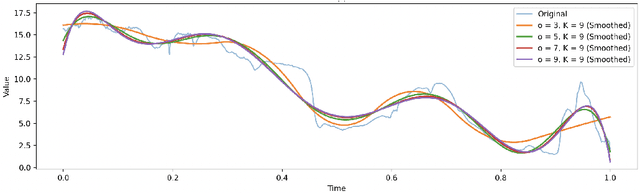
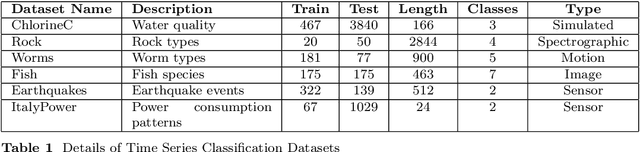

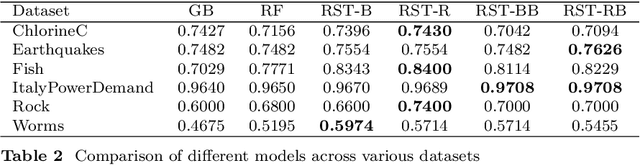
Functional data analysis (FDA) and ensemble learning can be powerful tools for analyzing complex environmental time series. Recent literature has highlighted the key role of diversity in enhancing accuracy and reducing variance in ensemble methods.This paper introduces Randomized Spline Trees (RST), a novel algorithm that bridges these two approaches by incorporating randomized functional representations into the Random Forest framework. RST generates diverse functional representations of input data using randomized B-spline parameters, creating an ensemble of decision trees trained on these varied representations. We provide a theoretical analysis of how this functional diversity contributes to reducing generalization error and present empirical evaluations on six environmental time series classification tasks from the UCR Time Series Archive. Results show that RST variants outperform standard Random Forests and Gradient Boosting on most datasets, improving classification accuracy by up to 14\%. The success of RST demonstrates the potential of adaptive functional representations in capturing complex temporal patterns in environmental data. This work contributes to the growing field of machine learning techniques focused on functional data and opens new avenues for research in environmental time series analysis.
Augmented Functional Random Forests: Classifier Construction and Unbiased Functional Principal Components Importance through Ad-Hoc Conditional Permutations
Aug 23, 2024



This paper introduces a novel supervised classification strategy that integrates functional data analysis (FDA) with tree-based methods, addressing the challenges of high-dimensional data and enhancing the classification performance of existing functional classifiers. Specifically, we propose augmented versions of functional classification trees and functional random forests, incorporating a new tool for assessing the importance of functional principal components. This tool provides an ad-hoc method for determining unbiased permutation feature importance in functional data, particularly when dealing with correlated features derived from successive derivatives. Our study demonstrates that these additional features can significantly enhance the predictive power of functional classifiers. Experimental evaluations on both real-world and simulated datasets showcase the effectiveness of the proposed methodology, yielding promising results compared to existing methods.
Demystifying Functional Random Forests: Novel Explainability Tools for Model Transparency in High-Dimensional Spaces
Aug 22, 2024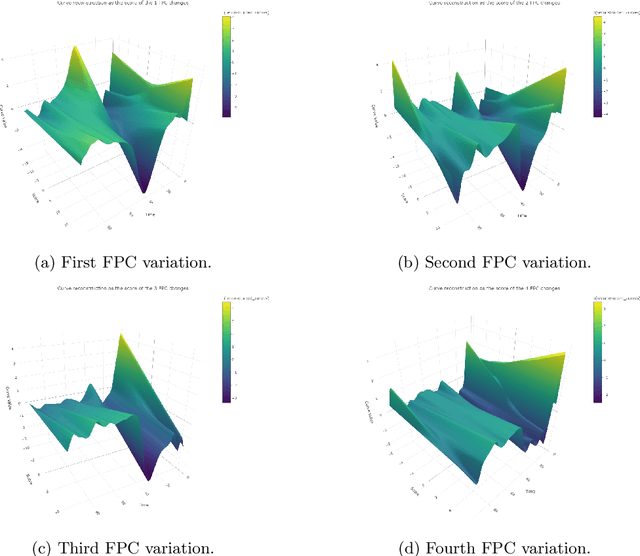
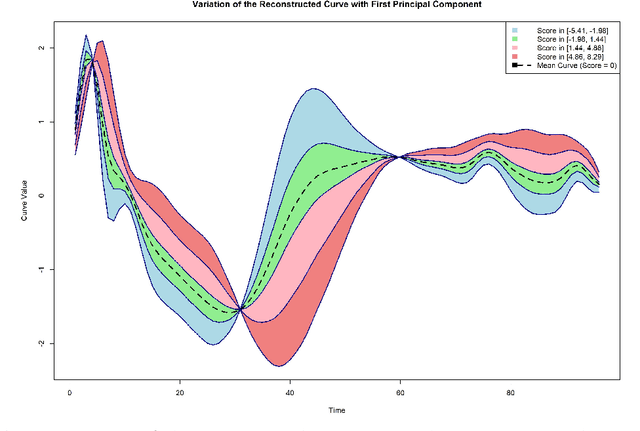
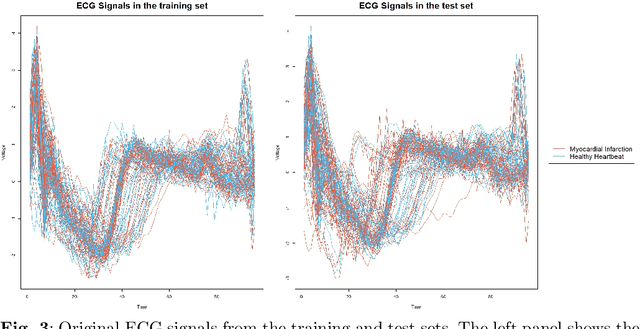
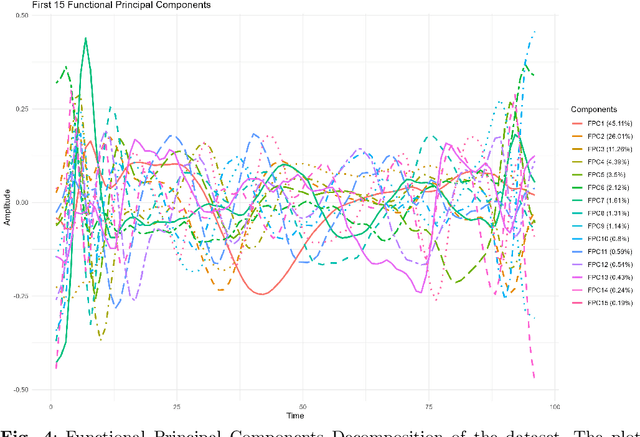
The advent of big data has raised significant challenges in analysing high-dimensional datasets across various domains such as medicine, ecology, and economics. Functional Data Analysis (FDA) has proven to be a robust framework for addressing these challenges, enabling the transformation of high-dimensional data into functional forms that capture intricate temporal and spatial patterns. However, despite advancements in functional classification methods and very high performance demonstrated by combining FDA and ensemble methods, a critical gap persists in the literature concerning the transparency and interpretability of black-box models, e.g. Functional Random Forests (FRF). In response to this need, this paper introduces a novel suite of explainability tools to illuminate the inner mechanisms of FRF. We propose using Functional Partial Dependence Plots (FPDPs), Functional Principal Component (FPC) Probability Heatmaps, various model-specific and model-agnostic FPCs' importance metrics, and the FPC Internal-External Importance and Explained Variance Bubble Plot. These tools collectively enhance the transparency of FRF models by providing a detailed analysis of how individual FPCs contribute to model predictions. By applying these methods to an ECG dataset, we demonstrate the effectiveness of these tools in revealing critical patterns and improving the explainability of FRF.
Random Survival Forest for Censored Functional Data
Jul 22, 2024This paper introduces a Random Survival Forest (RSF) method for functional data. The focus is specifically on defining a new functional data structure, the Censored Functional Data (CFD), for dealing with temporal observations that are censored due to study limitations or incomplete data collection. This approach allows for precise modelling of functional survival trajectories, leading to improved interpretation and prediction of survival dynamics across different groups. A medical survival study on the benchmark SOFA data set is presented. Results show good performance of the proposed approach, particularly in ranking the importance of predicting variables, as captured through dynamic changes in SOFA scores and patient mortality rates.
Supervised Learning via Ensembles of Diverse Functional Representations: the Functional Voting Classifier
Mar 23, 2024Many conventional statistical and machine learning methods face challenges when applied directly to high dimensional temporal observations. In recent decades, Functional Data Analysis (FDA) has gained widespread popularity as a framework for modeling and analyzing data that are, by their nature, functions in the domain of time. Although supervised classification has been extensively explored in recent decades within the FDA literature, ensemble learning of functional classifiers has only recently emerged as a topic of significant interest. Thus, the latter subject presents unexplored facets and challenges from various statistical perspectives. The focal point of this paper lies in the realm of ensemble learning for functional data and aims to show how different functional data representations can be used to train ensemble members and how base model predictions can be combined through majority voting. The so-called Functional Voting Classifier (FVC) is proposed to demonstrate how different functional representations leading to augmented diversity can increase predictive accuracy. Many real-world datasets from several domains are used to display that the FVC can significantly enhance performance compared to individual models. The framework presented provides a foundation for voting ensembles with functional data and can stimulate a highly encouraging line of research in the FDA context.