 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomized Spline Trees for Functional Data Classification: Theory and Application to Environmental Time Series
Sep 12, 2024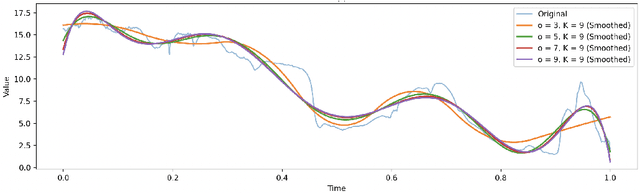
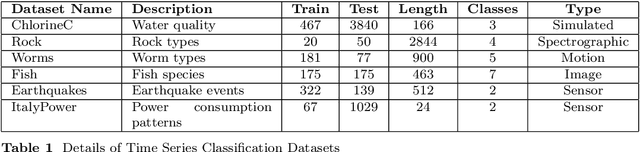

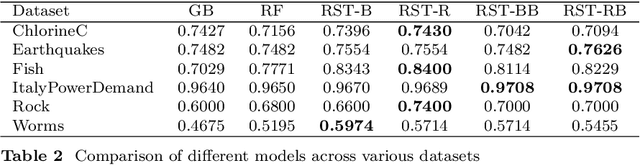
Functional data analysis (FDA) and ensemble learning can be powerful tools for analyzing complex environmental time series. Recent literature has highlighted the key role of diversity in enhancing accuracy and reducing variance in ensemble methods.This paper introduces Randomized Spline Trees (RST), a novel algorithm that bridges these two approaches by incorporating randomized functional representations into the Random Forest framework. RST generates diverse functional representations of input data using randomized B-spline parameters, creating an ensemble of decision trees trained on these varied representations. We provide a theoretical analysis of how this functional diversity contributes to reducing generalization error and present empirical evaluations on six environmental time series classification tasks from the UCR Time Series Archive. Results show that RST variants outperform standard Random Forests and Gradient Boosting on most datasets, improving classification accuracy by up to 14\%. The success of RST demonstrates the potential of adaptive functional representations in capturing complex temporal patterns in environmental data. This work contributes to the growing field of machine learning techniques focused on functional data and opens new avenues for research in environmental time series analysis.
Supervised Learning via Ensembles of Diverse Functional Representations: the Functional Voting Classifier
Mar 23, 2024Many conventional statistical and machine learning methods face challenges when applied directly to high dimensional temporal observations. In recent decades, Functional Data Analysis (FDA) has gained widespread popularity as a framework for modeling and analyzing data that are, by their nature, functions in the domain of time. Although supervised classification has been extensively explored in recent decades within the FDA literature, ensemble learning of functional classifiers has only recently emerged as a topic of significant interest. Thus, the latter subject presents unexplored facets and challenges from various statistical perspectives. The focal point of this paper lies in the realm of ensemble learning for functional data and aims to show how different functional data representations can be used to train ensemble members and how base model predictions can be combined through majority voting. The so-called Functional Voting Classifier (FVC) is proposed to demonstrate how different functional representations leading to augmented diversity can increase predictive accuracy. Many real-world datasets from several domains are used to display that the FVC can significantly enhance performance compared to individual models. The framework presented provides a foundation for voting ensembles with functional data and can stimulate a highly encouraging line of research in the FDA context.