 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to generate feasible graphs using graph grammars
Jan 10, 2025Generative methods for graphs need to be sufficiently flexible to model complex dependencies between sets of nodes. At the same time, the generated graphs need to satisfy domain-dependent feasibility conditions, that is, they should not violate certain constraints that would make their interpretation impossible within the given application domain (e.g. a molecular graph where an atom has a very large number of chemical bounds). Crucially, constraints can involve not only local but also long-range dependencies: for example, the maximal length of a cycle can be bounded. Currently, a large class of generative approaches for graphs, such as methods based on artificial neural networks, is based on message passing schemes. These approaches suffer from information 'dilution' issues that severely limit the maximal range of the dependencies that can be modeled. To address this problem, we propose a generative approach based on the notion of graph grammars. The key novel idea is to introduce a domain-dependent coarsening procedure to provide short-cuts for long-range dependencies. We show the effectiveness of our proposal in two domains: 1) small drugs and 2) RNA secondary structures. In the first case, we compare the quality of the generated molecular graphs via the Molecular Sets (MOSES) benchmark suite, which evaluates the distance between generated and real molecules, their lipophilicity, synthesizability, and drug-likeness. In the second case, we show that the approach can generate very large graphs (with hundreds of nodes) that are accepted as valid examples for a desired RNA family by the "Infernal" covariance model, a state-of-the-art RNA classifier. Our implementation is available on github: github.com/fabriziocosta/GraphLearn
kLog: A Language for Logical and Relational Learning with Kernels
Jul 28, 2014
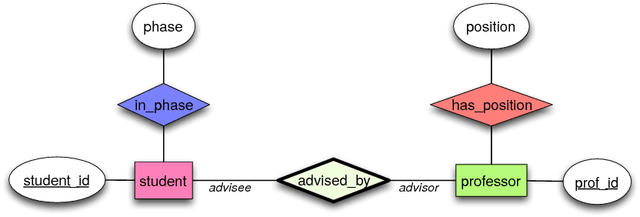
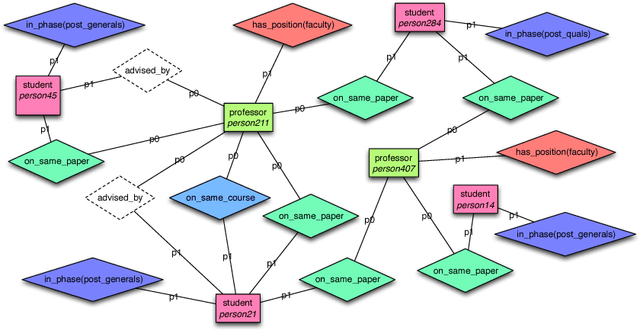

We introduce kLog, a novel approach to statistical relational learning. Unlike standard approaches, kLog does not represent a probability distribution directly. It is rather a language to perform kernel-based learning on expressive logical and relational representations. kLog allows users to specify learning problems declaratively. It builds on simple but powerful concepts: learning from interpretations, entity/relationship data modeling, logic programming, and deductive databases. Access by the kernel to the rich representation is mediated by a technique we call graphicalization: the relational representation is first transformed into a graph --- in particular, a grounded entity/relationship diagram. Subsequently, a choice of graph kernel defines the feature space. kLog supports mixed numerical and symbolic data, as well as background knowledge in the form of Prolog or Datalog programs as in inductive logic programming systems. The kLog framework can be applied to tackle the same range of tasks that has made statistical relational learning so popular, including classification, regression, multitask learning, and collective classification. We also report about empirical comparisons, showing that kLog can be either more accurate, or much faster at the same level of accuracy, than Tilde and Alchemy. kLog is GPLv3 licensed and is available at http://klog.dinfo.unifi.it along with tutorials.