 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Language Models Outperform Non-Experts in Poetry Evaluation? A Comparative Study Using the Consensual Assessment Technique
Feb 26, 2025The Consensual Assessment Technique (CAT) evaluates creativity through holistic expert judgments. We investigate the use of two advanced Large Language Models (LLMs), Claude-3-Opus and GPT-4o, to evaluate poetry by a methodology inspired by the CAT. Using a dataset of 90 poems, we found that these LLMs can surpass the results achieved by non-expert human judges at matching a ground truth based on publication venue, particularly when assessing smaller subsets of poems. Claude-3-Opus exhibited slightly superior performance than GPT-4o. We show that LLMs are viable tools for accurately assessing poetry, paving the way for their broader application into other creative domains.
Are Frontier Large Language Models Suitable for Q&A in Science Centres?
Dec 06, 2024
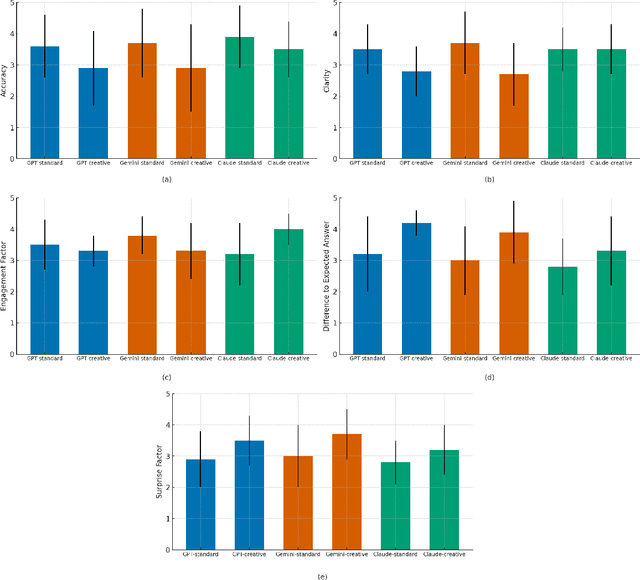


This paper investigates the suitability of frontier Large Language Models (LLMs) for Q&A interactions in science centres, with the aim of boosting visitor engagement while maintaining factual accuracy. Using a dataset of questions collected from the National Space Centre in Leicester (UK), we evaluated responses generated by three leading models: OpenAI's GPT-4, Claude 3.5 Sonnet, and Google Gemini 1.5. Each model was prompted for both standard and creative responses tailored to an 8-year-old audience, and these responses were assessed by space science experts based on accuracy, engagement, clarity, novelty, and deviation from expected answers. The results revealed a trade-off between creativity and accuracy, with Claude outperforming GPT and Gemini in both maintaining clarity and engaging young audiences, even when asked to generate more creative responses. Nonetheless, experts observed that higher novelty was generally associated with reduced factual reliability across all models. This study highlights the potential of LLMs in educational settings, emphasizing the need for careful prompt engineering to balance engagement with scientific rigor.
Do LLMs Agree on the Creativity Evaluation of Alternative Uses?
Nov 26, 2024



This paper investigates whether large language models (LLMs) show agreement in assessing creativity in responses to the Alternative Uses Test (AUT). While LLMs are increasingly used to evaluate creative content, previous studies have primarily focused on a single model assessing responses generated by the same model or humans. This paper explores whether LLMs can impartially and accurately evaluate creativity in outputs generated by both themselves and other models. Using an oracle benchmark set of AUT responses, categorized by creativity level (common, creative, and highly creative), we experiment with four state-of-the-art LLMs evaluating these outputs. We test both scoring and ranking methods and employ two evaluation settings (comprehensive and segmented) to examine if LLMs agree on the creativity evaluation of alternative uses. Results reveal high inter-model agreement, with Spearman correlations averaging above 0.7 across models and reaching over 0.77 with respect to the oracle, indicating a high level of agreement and validating the reliability of LLMs in creativity assessment of alternative uses. Notably, models do not favour their own responses, instead they provide similar creativity assessment scores or rankings for alternative uses generated by other models. These findings suggest that LLMs exhibit impartiality and high alignment in creativity evaluation, offering promising implications for their use in automated creativity assessment.