 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAMOS-OCTA: Vessel-Aware Multi-Axis Orthogonal Supervision for Inpainting Motion-Corrupted OCT Angiography Volumes
Feb 01, 2026Handheld Optical Coherence Tomography Angiography (OCTA) enables noninvasive retinal imaging in uncooperative or pediatric subjects, but is highly susceptible to motion artifacts that severely degrade volumetric image quality. Sudden motion during 3D acquisition can lead to unsampled retinal regions across entire B-scans (cross-sectional slices), resulting in blank bands in en face projections. We propose VAMOS-OCTA, a deep learning framework for inpainting motion-corrupted B-scans using vessel-aware multi-axis supervision. We employ a 2.5D U-Net architecture that takes a stack of neighboring B-scans as input to reconstruct a corrupted center B-scan, guided by a novel Vessel-Aware Multi-Axis Orthogonal Supervision (VAMOS) loss. This loss combines vessel-weighted intensity reconstruction with axial and lateral projection consistency, encouraging vascular continuity in native B-scans and across orthogonal planes. Unlike prior work that focuses primarily on restoring the en face MIP, VAMOS-OCTA jointly enhances both cross-sectional B-scan sharpness and volumetric projection accuracy, even under severe motion corruptions. We trained our model on both synthetic and real-world corrupted volumes and evaluated its performance using both perceptual quality and pixel-wise accuracy metrics. VAMOS-OCTA consistently outperforms prior methods, producing reconstructions with sharp capillaries, restored vessel continuity, and clean en face projections. These results demonstrate that multi-axis supervision offers a powerful constraint for restoring motion-degraded 3D OCTA data. Our source code is available at https://github.com/MedICL-VU/VAMOS-OCTA.
Are Frontier Large Language Models Suitable for Q&A in Science Centres?
Dec 06, 2024
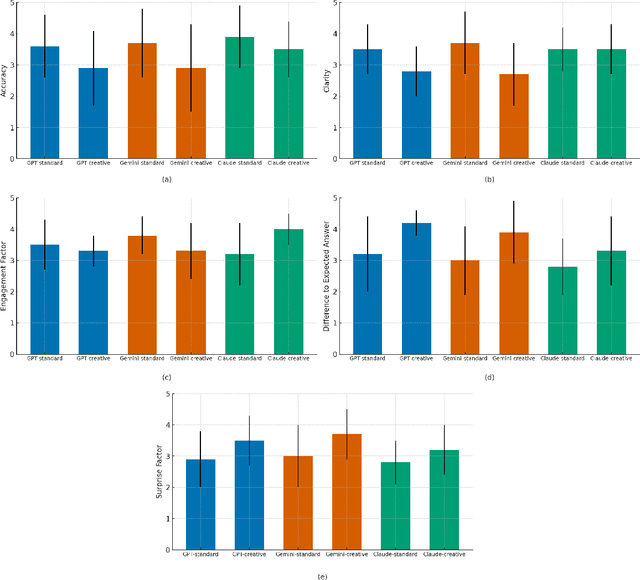


This paper investigates the suitability of frontier Large Language Models (LLMs) for Q&A interactions in science centres, with the aim of boosting visitor engagement while maintaining factual accuracy. Using a dataset of questions collected from the National Space Centre in Leicester (UK), we evaluated responses generated by three leading models: OpenAI's GPT-4, Claude 3.5 Sonnet, and Google Gemini 1.5. Each model was prompted for both standard and creative responses tailored to an 8-year-old audience, and these responses were assessed by space science experts based on accuracy, engagement, clarity, novelty, and deviation from expected answers. The results revealed a trade-off between creativity and accuracy, with Claude outperforming GPT and Gemini in both maintaining clarity and engaging young audiences, even when asked to generate more creative responses. Nonetheless, experts observed that higher novelty was generally associated with reduced factual reliability across all models. This study highlights the potential of LLMs in educational settings, emphasizing the need for careful prompt engineering to balance engagement with scientific rigor.