 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData downlink prioritization using image classification on-board a 6U CubeSat
Aug 27, 2024Nanosatellites are proliferating as low-cost dedicated sensing systems with lean development cycles. Kyushu Institute of Technology and collaborators have launched a joint venture for a nanosatellite mission, VERTECS. The primary mission is to elucidate the formation history of stars by observing the optical-wavelength cosmic background radiation. The VERTECS satellite will be equipped with a small-aperture telescope and a high-precision attitude control system to capture the cosmic data for analysis on the ground. However, nanosatellites are limited by their onboard memory resources and downlink speed capabilities. Additionally, due to a limited number of ground stations, the satellite mission will face issues meeting the required data budget for mission success. To alleviate this issue, we propose an on-orbit system to autonomously classify and then compress desirable image data for data downlink prioritization and optimization. The system comprises a prototype Camera Controller Board (CCB) which carries a Raspberry Pi Compute Module 4 which is used for classification and compression. The system uses a lightweight Convolutional Neural Network (CNN) model to classify and determine the desirability of captured image data. The model is designed to be lean and robust to reduce the computational and memory load on the satellite. The model is trained and tested on a novel star field dataset consisting of data captured by the Sloan Digital Sky Survey (SDSS). The dataset is meant to simulate the expected data produced by the 6U satellite. The compression step implements GZip, RICE or HCOMPRESS compression, which are standards for astronomical data. Preliminary testing on the proposed CNN model results in a classification accuracy of about 100\% on the star field dataset, with compression ratios of 3.99, 5.16 and 5.43 for GZip, RICE and HCOMPRESS that were achieved on tested FITS image data.
* 14 pages
The Classification of Optical Galaxy Morphology Using Unsupervised Learning Techniques
Jun 13, 2022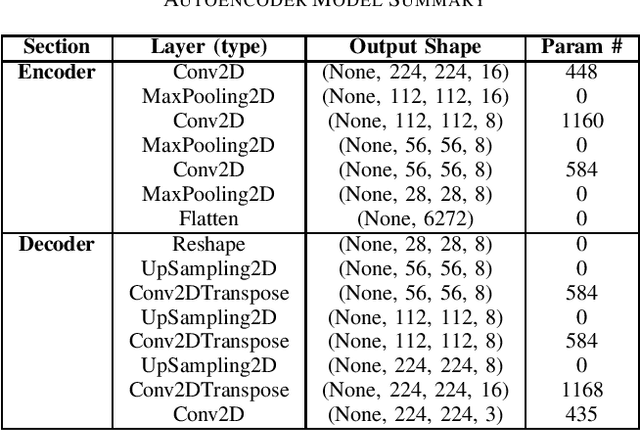
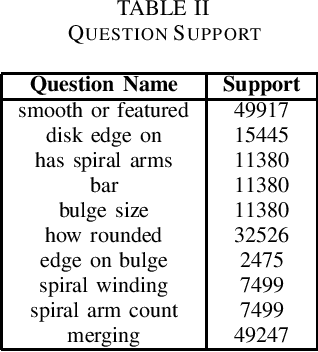
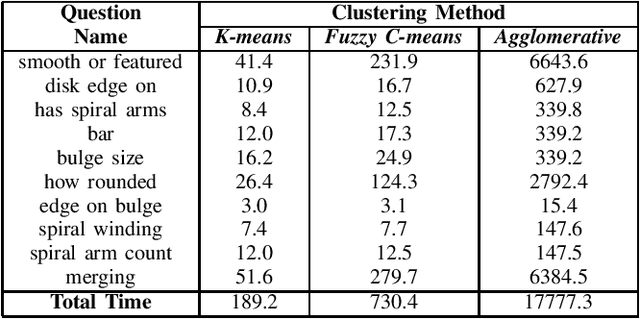
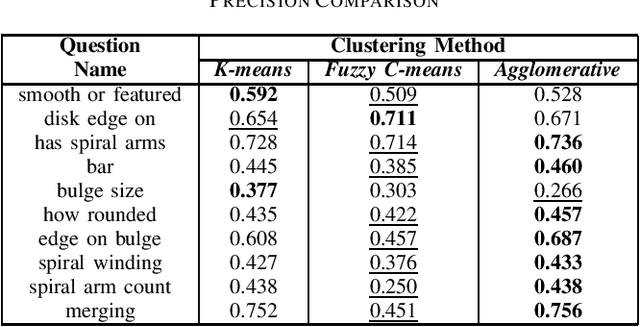
The advent of large scale, data intensive astronomical surveys has caused the viability of human-based galaxy morphology classification methods to come into question. Put simply, too much astronomical data is being produced for scientists to visually label. Attempts have been made to crowd-source this work by recruiting volunteers from the general public. However, even these efforts will soon fail to keep up with data produced by modern surveys. Unsupervised learning techniques do not require existing labels to classify data and could pave the way to unplanned discoveries. Therefore, this paper aims to implement unsupervised learning algorithms to classify the Galaxy Zoo DECaLS dataset without human supervision. First, a convolutional autoencoder was implemented as a feature extractor. The extracted features were then clustered via k-means, fuzzy c-means and agglomerative clustering to provide classifications. The results were compared to the volunteer classifications of the Galaxy Zoo DECaLS dataset. Agglomerative clustering generally produced the best results, however, the performance gain over k-means clustering was not significant. With the appropriate optimizations, this approach could be used to provide classifications for the better performing Galaxy Zoo DECaLS decision tree questions. Ultimately, this unsupervised learning approach provided valuable insights and results that were useful to scientists.
A Comparison of Deep Learning Architectures for Optical Galaxy Morphology Classification
Nov 08, 2021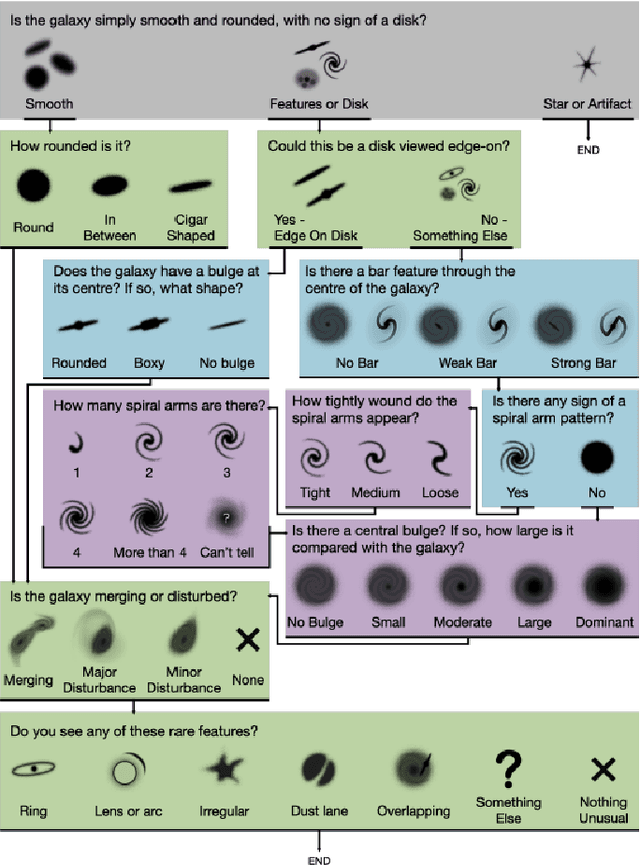
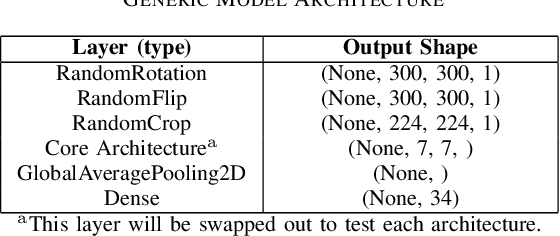

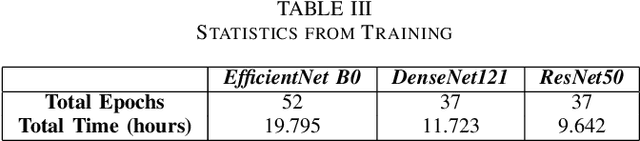
The classification of galaxy morphology plays a crucial role in understanding galaxy formation and evolution. Traditionally, this process is done manually. The emergence of deep learning techniques has given room for the automation of this process. As such, this paper offers a comparison of deep learning architectures to determine which is best suited for optical galaxy morphology classification. Adapting the model training method proposed by Walmsley et al in 2021, the Zoobot Python library is used to train models to predict Galaxy Zoo DECaLS decision tree responses, made by volunteers, using EfficientNet B0, DenseNet121 and ResNet50 as core model architectures. The predicted results are then used to generate accuracy metrics per decision tree question to determine architecture performance. DenseNet121 was found to produce the best results, in terms of accuracy, with a reasonable training time. In future, further testing with more deep learning architectures could prove beneficial.