 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Grade Prediction Using Students' Grades and Demographics
Feb 28, 2026Student repetition in secondary education imposes significant resource burdens, particularly in resource-constrained contexts. Addressing this challenge, this study introduces a unified machine learning framework that simultaneously predicts pass/fail outcomes and continuous grades, a departure from prior research that treats classification and regression as separate tasks. Six models were evaluated: Logistic Regression, Decision Tree, and Random Forest for classification, and Linear Regression, Decision Tree Regressor, and Random Forest Regressor for regression, with hyperparameters optimized via exhaustive grid search. Using academic and demographic data from 4424 secondary school students, classification models achieved accuracies of up to 96%, while regression models attained a coefficient of determination of 0.70, surpassing baseline approaches. These results confirm the feasibility of early, data-driven identification of at-risk students and highlight the value of integrating dual-task prediction for more comprehensive insights. By enabling timely, personalized interventions, the framework offers a practical pathway to reducing grade repetition and optimizing resource allocation.
Semi-Supervised Anomaly Detection for the Determination of Vehicle Hijacking Tweets
Aug 19, 2023In South Africa, there is an ever-growing issue of vehicle hijackings. This leads to travellers constantly being in fear of becoming a victim to such an incident. This work presents a new semi-supervised approach to using tweets to identify hijacking incidents by using unsupervised anomaly detection algorithms. Tweets consisting of the keyword "hijacking" are obtained, stored, and processed using the term frequency-inverse document frequency (TF-IDF) and further analyzed by using two anomaly detection algorithms: 1) K-Nearest Neighbour (KNN); 2) Cluster Based Outlier Factor (CBLOF). The comparative evaluation showed that the KNN method produced an accuracy of 89%, whereas the CBLOF produced an accuracy of 90%. The CBLOF method was also able to obtain a F1-Score of 0.8, whereas the KNN produced a 0.78. Therefore, there is a slight difference between the two approaches, in favour of CBLOF, which has been selected as a preferred unsupervised method for the determination of relevant hijacking tweets. In future, a comparison will be done between supervised learning methods and the unsupervised methods presented in this work on larger dataset. Optimisation mechanisms will also be employed in order to increase the overall performance.
A Twitter-Driven Deep Learning Mechanism for the Determination of Vehicle Hijacking Spots in Cities
Aug 11, 2022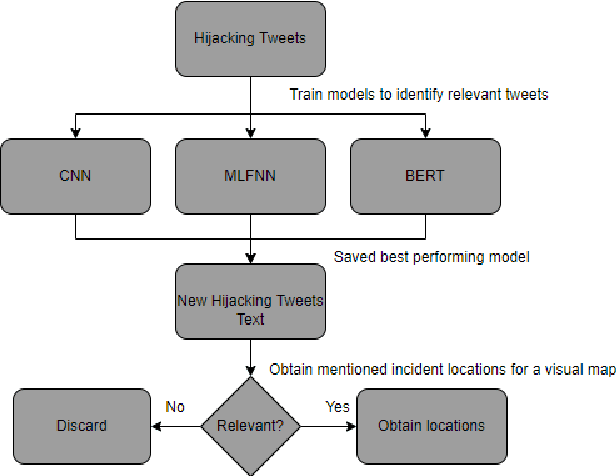
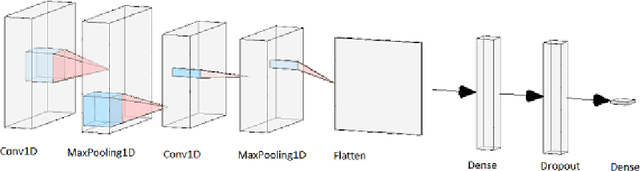
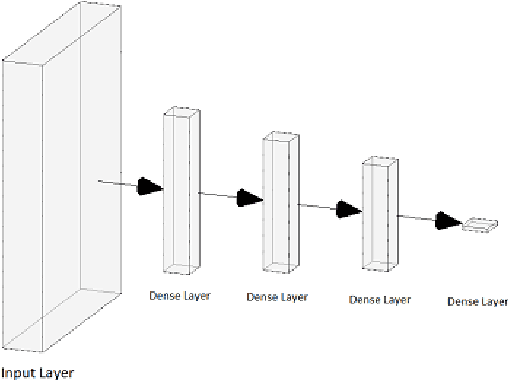
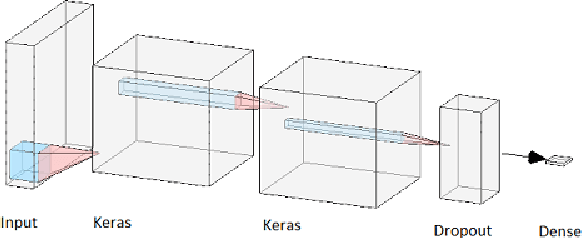
Vehicle hijacking is one of the leading crimes in many cities. For instance, in South Africa, drivers must constantly remain vigilant on the road in order to ensure that they do not become hijacking victims. This work is aimed at developing a map depicting hijacking spots in a city by using Twitter data. Tweets, which include the keyword "hijacking", are obtained in a designated city of Cape Town, in this work. In order to extract relevant tweets, these tweets are analyzed by using the following machine learning techniques: 1) a Multi-layer Feed-forward Neural Network (MLFNN); 2) Convolutional Neural Network; and Bidirectional Encoder Representations from Transformers (BERT). Through training and testing, CNN achieved an accuracy of 99.66%, while MLFNN and BERT achieve accuracies of 98.99% and 73.99% respectively. In terms of Recall, Precision and F1-score, CNN also achieved the best results. Therefore, CNN was used for the identification of relevant tweets. The relevant reports that it generates are visually presented on a points map of the City of Cape Town. This work used a small dataset of 426 tweets. In future, the use of evolutionary computation will be explored for purposes of optimizing the deep learning models. A mobile application is under development to make this information usable by the general public.
The Classification of Optical Galaxy Morphology Using Unsupervised Learning Techniques
Jun 13, 2022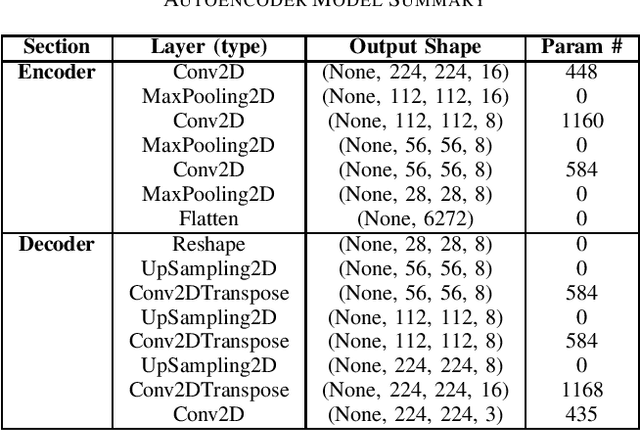
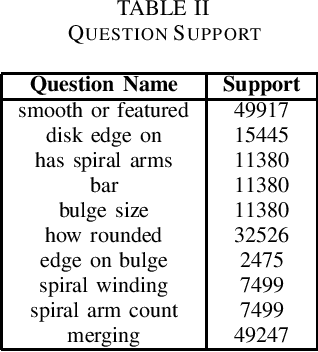
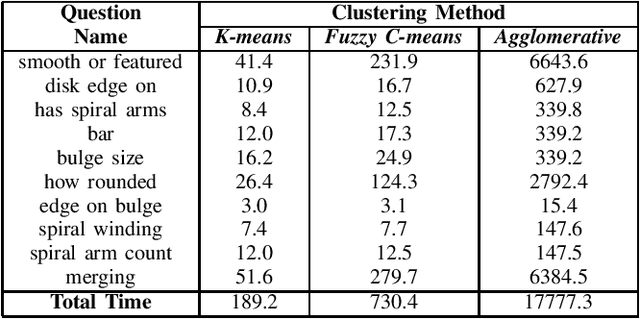
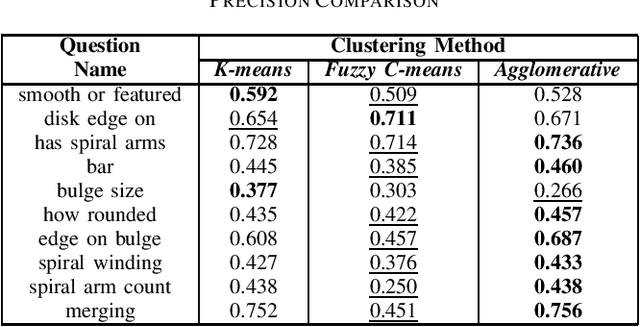
The advent of large scale, data intensive astronomical surveys has caused the viability of human-based galaxy morphology classification methods to come into question. Put simply, too much astronomical data is being produced for scientists to visually label. Attempts have been made to crowd-source this work by recruiting volunteers from the general public. However, even these efforts will soon fail to keep up with data produced by modern surveys. Unsupervised learning techniques do not require existing labels to classify data and could pave the way to unplanned discoveries. Therefore, this paper aims to implement unsupervised learning algorithms to classify the Galaxy Zoo DECaLS dataset without human supervision. First, a convolutional autoencoder was implemented as a feature extractor. The extracted features were then clustered via k-means, fuzzy c-means and agglomerative clustering to provide classifications. The results were compared to the volunteer classifications of the Galaxy Zoo DECaLS dataset. Agglomerative clustering generally produced the best results, however, the performance gain over k-means clustering was not significant. With the appropriate optimizations, this approach could be used to provide classifications for the better performing Galaxy Zoo DECaLS decision tree questions. Ultimately, this unsupervised learning approach provided valuable insights and results that were useful to scientists.
A Comparison of Deep Learning Architectures for Optical Galaxy Morphology Classification
Nov 08, 2021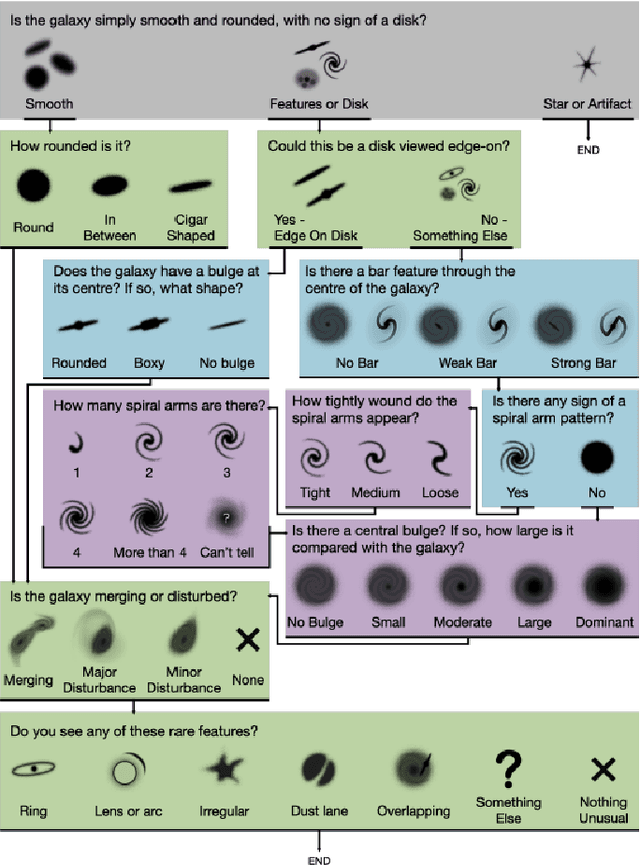
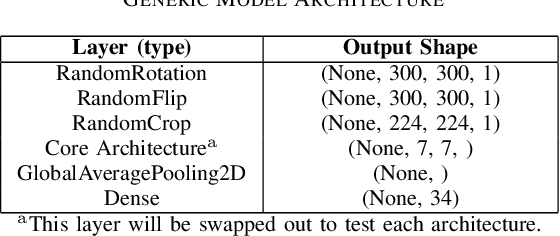

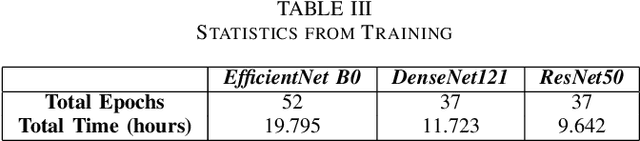
The classification of galaxy morphology plays a crucial role in understanding galaxy formation and evolution. Traditionally, this process is done manually. The emergence of deep learning techniques has given room for the automation of this process. As such, this paper offers a comparison of deep learning architectures to determine which is best suited for optical galaxy morphology classification. Adapting the model training method proposed by Walmsley et al in 2021, the Zoobot Python library is used to train models to predict Galaxy Zoo DECaLS decision tree responses, made by volunteers, using EfficientNet B0, DenseNet121 and ResNet50 as core model architectures. The predicted results are then used to generate accuracy metrics per decision tree question to determine architecture performance. DenseNet121 was found to produce the best results, in terms of accuracy, with a reasonable training time. In future, further testing with more deep learning architectures could prove beneficial.
A Comparative Evaluation of Population-based Optimization Algorithms for Workflow Scheduling in Cloud-Fog Environments
Dec 12, 2020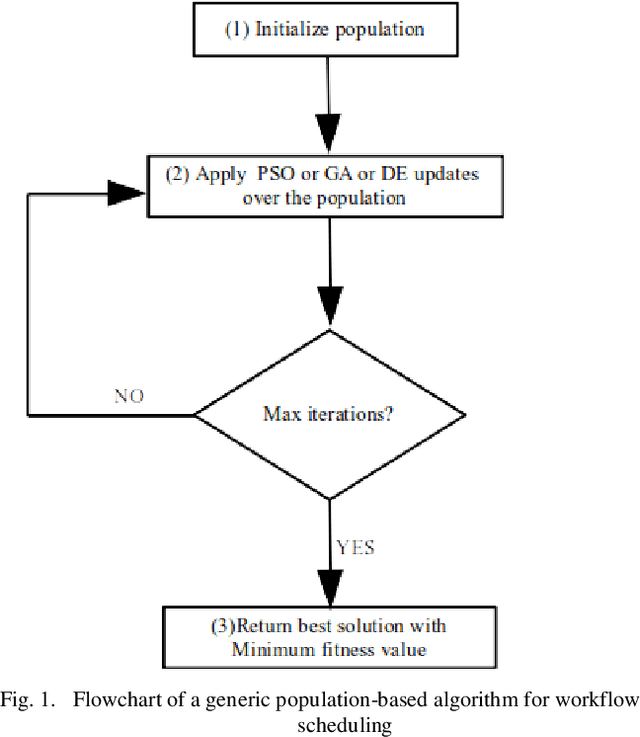
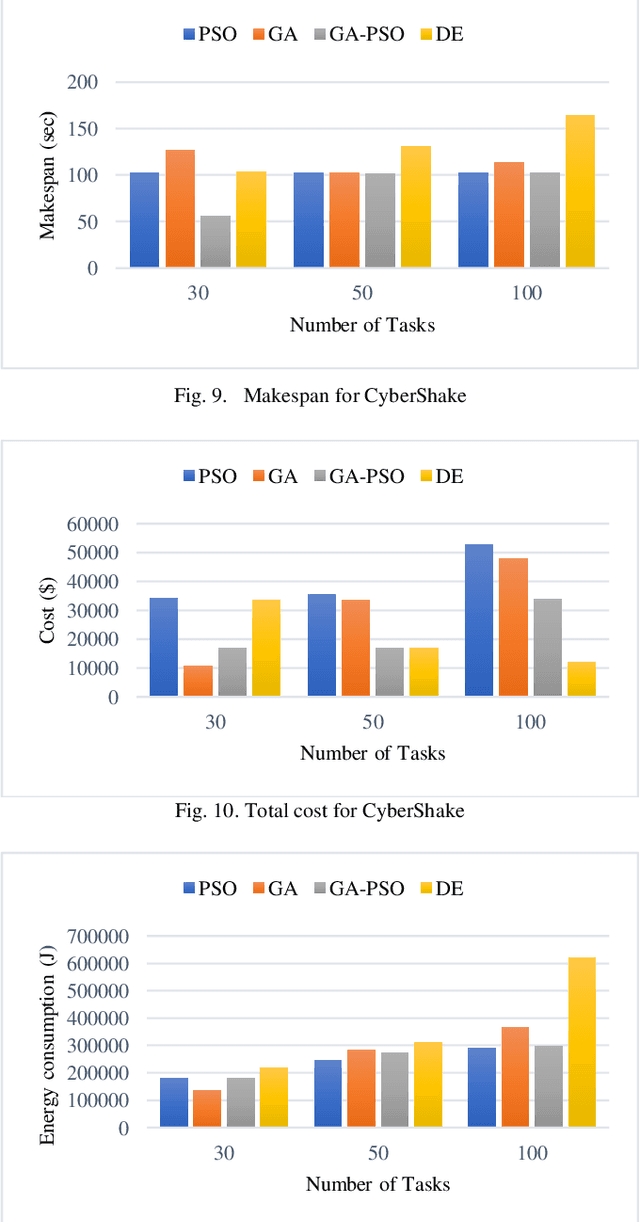
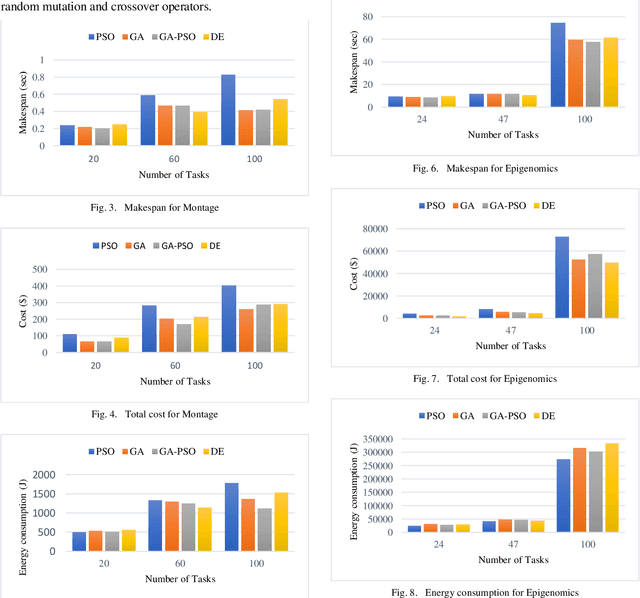
This work presents a comparative evaluation of four population-based optimization algorithms for workflow scheduling in cloud-fog environments. These algorithms are as follows: Particle Swarm Optimization (PSO), Genetic Algorithm (GA), Differential Evolution (DE) and GA-PSO. This work also provides the motivational groundwork for the weighted sum objective function for the workflow scheduling problem and develops this function based on three objectives: makespan, cost and energy. The recently proposed FogWorkflowSim is used as the simulation environment with the aforementioned objectives serving performance metrics. Results show that hybrid combination of the GA-PSO algorithm exhibits slightly better than the standard algorithms. Future work will include expansion of the workflows used by increasing the number of tasks as well as adding some more workflows. The addition of some more objectives to the weighted objective function will also be pursued
* 8 pages