 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Anomaly Detection for the Determination of Vehicle Hijacking Tweets
Aug 19, 2023In South Africa, there is an ever-growing issue of vehicle hijackings. This leads to travellers constantly being in fear of becoming a victim to such an incident. This work presents a new semi-supervised approach to using tweets to identify hijacking incidents by using unsupervised anomaly detection algorithms. Tweets consisting of the keyword "hijacking" are obtained, stored, and processed using the term frequency-inverse document frequency (TF-IDF) and further analyzed by using two anomaly detection algorithms: 1) K-Nearest Neighbour (KNN); 2) Cluster Based Outlier Factor (CBLOF). The comparative evaluation showed that the KNN method produced an accuracy of 89%, whereas the CBLOF produced an accuracy of 90%. The CBLOF method was also able to obtain a F1-Score of 0.8, whereas the KNN produced a 0.78. Therefore, there is a slight difference between the two approaches, in favour of CBLOF, which has been selected as a preferred unsupervised method for the determination of relevant hijacking tweets. In future, a comparison will be done between supervised learning methods and the unsupervised methods presented in this work on larger dataset. Optimisation mechanisms will also be employed in order to increase the overall performance.
A Twitter-Driven Deep Learning Mechanism for the Determination of Vehicle Hijacking Spots in Cities
Aug 11, 2022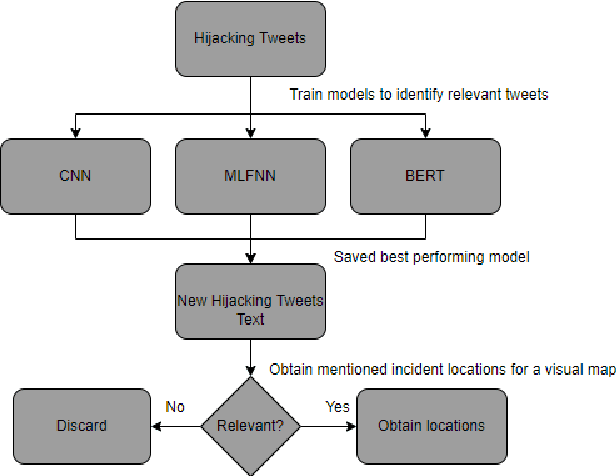
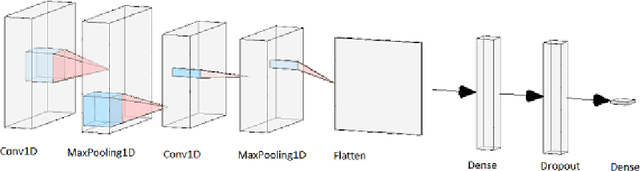
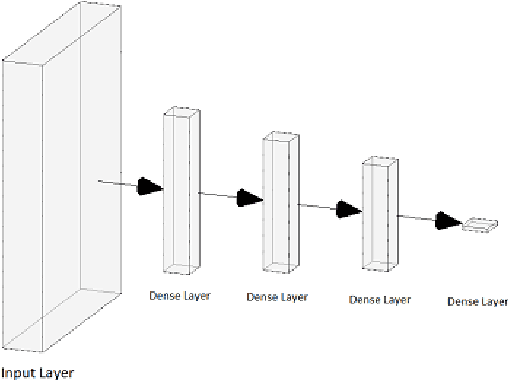
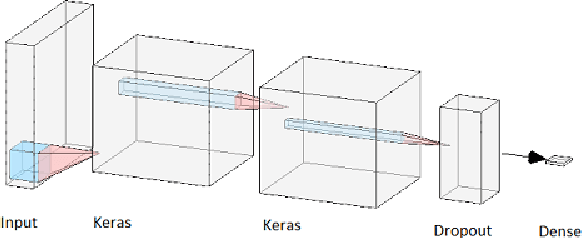
Vehicle hijacking is one of the leading crimes in many cities. For instance, in South Africa, drivers must constantly remain vigilant on the road in order to ensure that they do not become hijacking victims. This work is aimed at developing a map depicting hijacking spots in a city by using Twitter data. Tweets, which include the keyword "hijacking", are obtained in a designated city of Cape Town, in this work. In order to extract relevant tweets, these tweets are analyzed by using the following machine learning techniques: 1) a Multi-layer Feed-forward Neural Network (MLFNN); 2) Convolutional Neural Network; and Bidirectional Encoder Representations from Transformers (BERT). Through training and testing, CNN achieved an accuracy of 99.66%, while MLFNN and BERT achieve accuracies of 98.99% and 73.99% respectively. In terms of Recall, Precision and F1-score, CNN also achieved the best results. Therefore, CNN was used for the identification of relevant tweets. The relevant reports that it generates are visually presented on a points map of the City of Cape Town. This work used a small dataset of 426 tweets. In future, the use of evolutionary computation will be explored for purposes of optimizing the deep learning models. A mobile application is under development to make this information usable by the general public.