 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison and Analysis of Deep Audio Embeddings for Music Emotion Recognition
Apr 13, 2021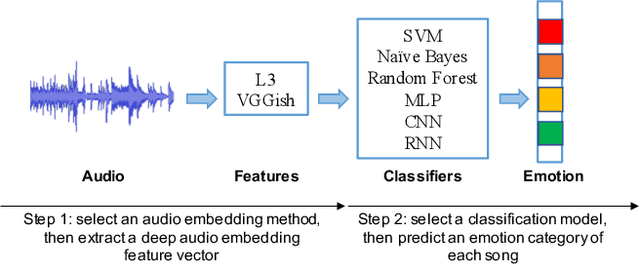

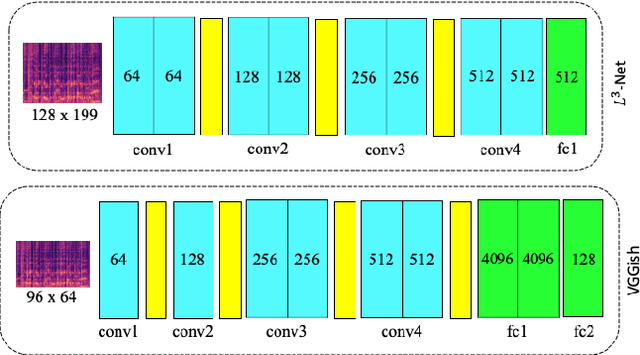
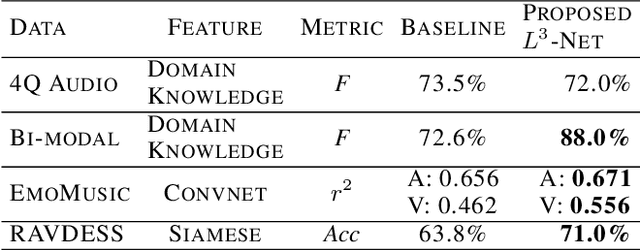
Emotion is a complicated notion present in music that is hard to capture even with fine-tuned feature engineering. In this paper, we investigate the utility of state-of-the-art pre-trained deep audio embedding methods to be used in the Music Emotion Recognition (MER) task. Deep audio embedding methods allow us to efficiently capture the high dimensional features into a compact representation. We implement several multi-class classifiers with deep audio embeddings to predict emotion semantics in music. We investigate the effectiveness of L3-Net and VGGish deep audio embedding methods for music emotion inference over four music datasets. The experiments with several classifiers on the task show that the deep audio embedding solutions can improve the performances of the previous baseline MER models. We conclude that deep audio embeddings represent musical emotion semantics for the MER task without expert human engineering.
* AAAI Workshop on Affective Content Analysis 2021 Camera Ready Version
Incremental Learning Algorithm for Sound Event Detection
Mar 26, 2020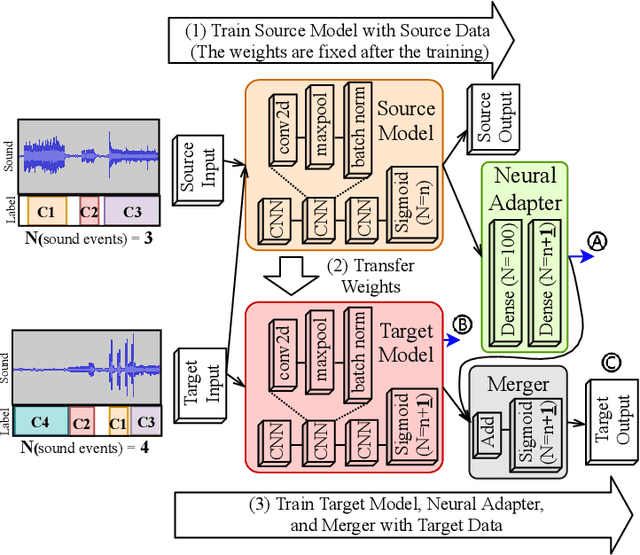
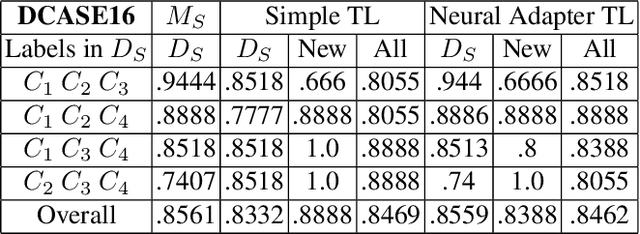
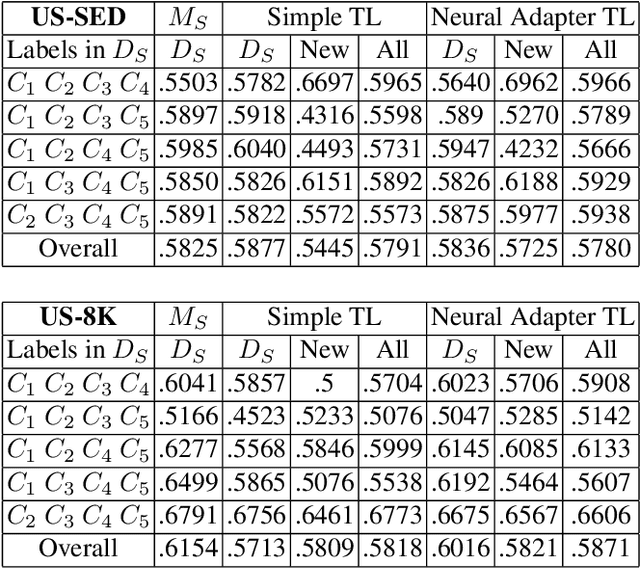
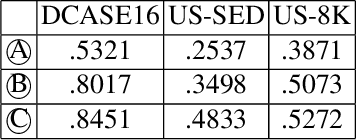
This paper presents a new learning strategy for the Sound Event Detection (SED) system to tackle the issues of i) knowledge migration from a pre-trained model to a new target model and ii) learning new sound events without forgetting the previously learned ones without re-training from scratch. In order to migrate the previously learned knowledge from the source model to the target one, a neural adapter is employed on the top of the source model. The source model and the target model are merged via this neural adapter layer. The neural adapter layer facilitates the target model to learn new sound events with minimal training data and maintaining the performance of the previously learned sound events similar to the source model. Our extensive analysis on the DCASE16 and US-SED dataset reveals the effectiveness of the proposed method in transferring knowledge between source and target models without introducing any performance degradation on the previously learned sound events while obtaining a competitive detection performance on the newly learned sound events.
* IEEE ICME 2020 Camera Ready Version