 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized musically induced emotions of not-so-popular Colombian music
Dec 09, 2021
This work presents an initial proof of concept of how Music Emotion Recognition (MER) systems could be intentionally biased with respect to annotations of musically induced emotions in a political context. In specific, we analyze traditional Colombian music containing politically charged lyrics of two types: (1) vallenatos and social songs from the "left-wing" guerrilla Fuerzas Armadas Revolucionarias de Colombia (FARC) and (2) corridos from the "right-wing" paramilitaries Autodefensas Unidas de Colombia (AUC). We train personalized machine learning models to predict induced emotions for three users with diverse political views - we aim at identifying the songs that may induce negative emotions for a particular user, such as anger and fear. To this extent, a user's emotion judgements could be interpreted as problematizing data - subjective emotional judgments could in turn be used to influence the user in a human-centered machine learning environment. In short, highly desired "emotion regulation" applications could potentially deviate to "emotion manipulation" - the recent discredit of emotion recognition technologies might transcend ethical issues of diversity and inclusion.
The emotions that we perceive in music: the influence of language and lyrics comprehension on agreement
Oct 25, 2019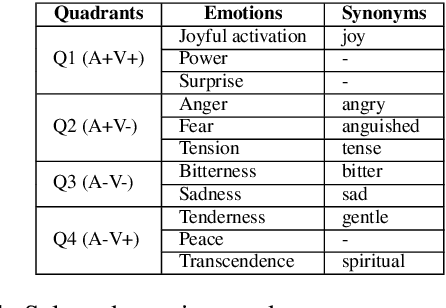
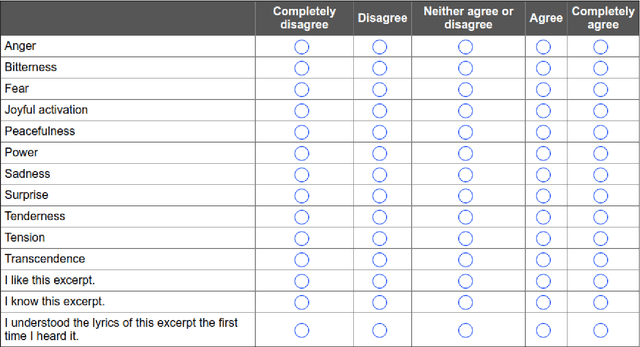
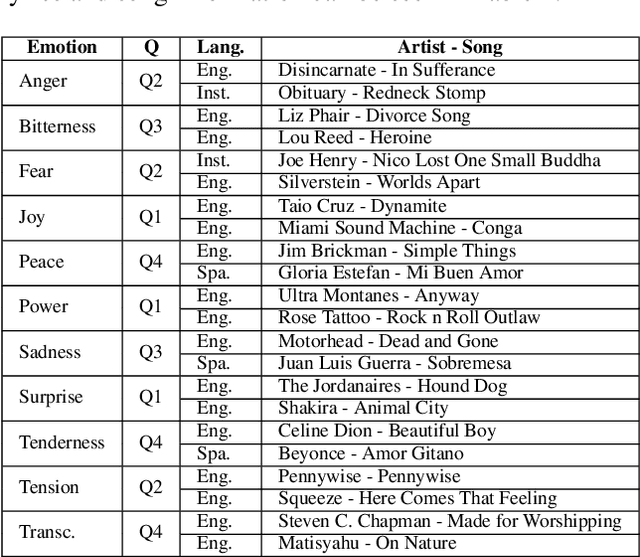

In the present study, we address the relationship between the emotions perceived in pop and rock music (mainly in Euro-American styles with English lyrics) and the language spoken by the listener. Our goal is to understand the influence of lyrics comprehension on the perception of emotions and use this information to improve Music Emotion Recognition (MER) models. Two main research questions are addressed: 1. Are there differences and similarities between the emotions perceived in pop/rock music by listeners raised with different mother tongues? 2. Do personal characteristics have an influence on the perceived emotions for listeners of a given language? Personal characteristics include the listeners' general demographics, familiarity and preference for the fragments, and music sophistication. Our hypothesis is that inter-rater agreement (as defined by Krippendorff's alpha coefficient) from subjects is directly influenced by the comprehension of lyrics.
Examining the Mapping Functions of Denoising Autoencoders in Music Source Separation
Apr 12, 2019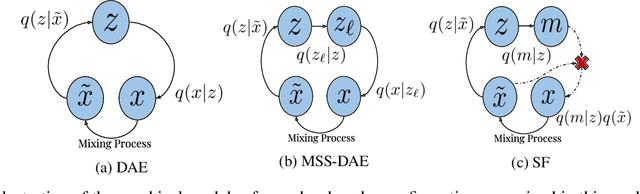
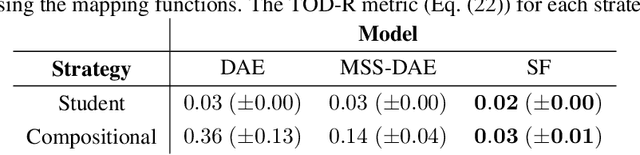
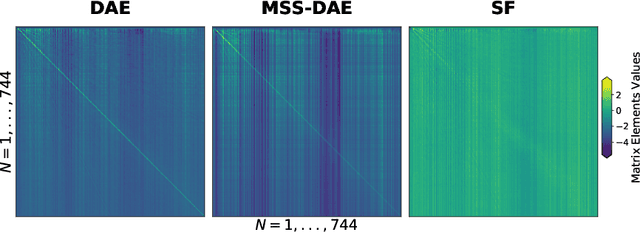
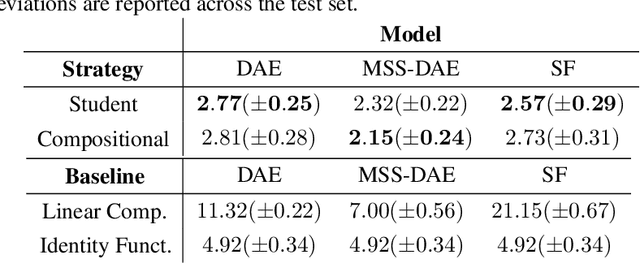
The goal of this work is to investigate what music source separation approaches based on neural networks learn from the data. We examine the mapping functions of neural networks that are based on the denoising autoencoder (DAE) model, and conditioned on the mixture magnitude spectra. For approximating the mapping functions, we propose an algorithm that is inspired by the knowledge distillation and is denoted as the neural couplings algorithm (NCA). The NCA yields a matrix that expresses the mapping of the mixture to the target source magnitude information. Using the NCA we examine the mapping functions of three fundamental DAE models in music source separation; one with single layer encoder and decoder, one with multi-layer encoder and single layer decoder, and one using the skip-filtering connections (SF) with a single encoding and decoding layer. We first train these models with realistic data to estimate the singing voice magnitude spectra from the corresponding mixture. We then use the optimized models and test spectral data as input to the NCA. Our experimental findings show that approaches based on the DAE model learn scalar filtering operators, exhibiting a predominant diagonal structure in their corresponding mapping functions, limiting the exploitation of inter-frequency structure of music data. In contrast, skip-filtering connections are shown to assist the DAE model in learning filtering operators that exploit richer inter-frequency structure.