 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Numbers to Perception, Energy Decay Curves Prediction
May 20, 2026Predicting Room Impulse Responses (RIRs) remains a challenge due to the high dimensionality of audio signals and the need for perceptual accuracy. This paper introduces a neural network framework that predicts multi-band Energy Decay Curves (EDCs) directly from room geometry and material properties. Unlike standard models, our framework employs a custom composite loss function that optimizes for both energy levels and decay slopes in the log-domain. This ensures the predicted curves adhere to physical decay principles while maintaining high sensitivity to reverberation time and early reflections. Results demonstrate that the model successfully approximates ground-truth acoustics with minimal error in T30 and clarity indices. The approach offers a computationally efficient alternative to traditional simulations, facilitating realistic audio rendering for interactive virtual environments.
Low Latency Time Domain Multichannel Speech and Music Source Separation
Apr 12, 2022
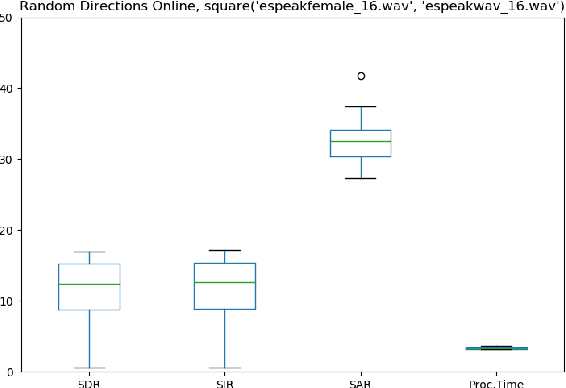
The Goal is to obtain a simple multichannel source separation with very low latency. Applications can be teleconferencing, hearing aids, augmented reality, or selective active noise cancellation. These real time applications need a very low latency, usually less than about 6 ms, and low complexity, because they usually run on small portable devices. For that we don't need the best separation, but "useful" separation, and not just on speech, but also music and noise. Usual frequency domain approaches have higher latency and complexity. Hence we introduce a novel probabilistic optimization method which we call "Random Directions", which can overcome local minima, applied to a simple time domain unmixing structure, and which is scalable for low complexity. Then it is compared to frequency domain approaches on separating speech and music sources, and using 3D microphone setups.
* This paper was published at the Asilomar Conference on Signals, Systems, and Computers in November 2021. A software repository for the paper is: https://github.com/TUIlmenauAMS/LowDelayMultichannelSourceSeparation_Random-Directions_Demo
Examining the Mapping Functions of Denoising Autoencoders in Music Source Separation
Apr 12, 2019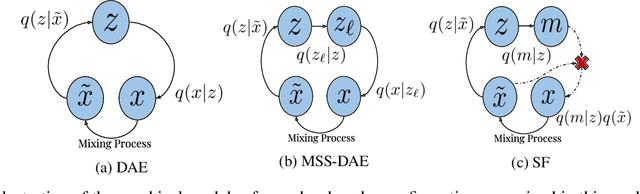
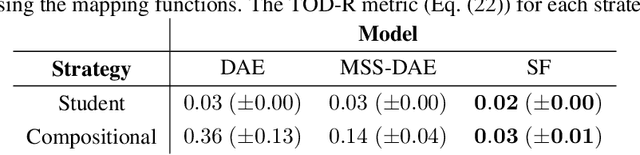
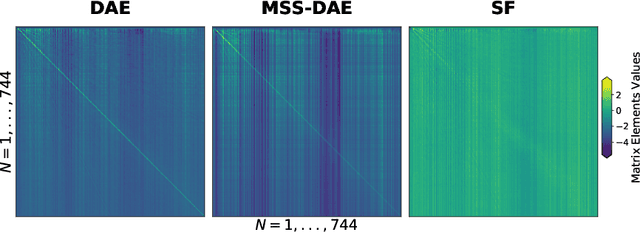
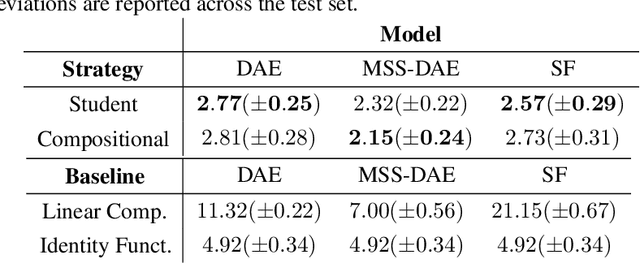
The goal of this work is to investigate what music source separation approaches based on neural networks learn from the data. We examine the mapping functions of neural networks that are based on the denoising autoencoder (DAE) model, and conditioned on the mixture magnitude spectra. For approximating the mapping functions, we propose an algorithm that is inspired by the knowledge distillation and is denoted as the neural couplings algorithm (NCA). The NCA yields a matrix that expresses the mapping of the mixture to the target source magnitude information. Using the NCA we examine the mapping functions of three fundamental DAE models in music source separation; one with single layer encoder and decoder, one with multi-layer encoder and single layer decoder, and one using the skip-filtering connections (SF) with a single encoding and decoding layer. We first train these models with realistic data to estimate the singing voice magnitude spectra from the corresponding mixture. We then use the optimized models and test spectral data as input to the NCA. Our experimental findings show that approaches based on the DAE model learn scalar filtering operators, exhibiting a predominant diagonal structure in their corresponding mapping functions, limiting the exploitation of inter-frequency structure of music data. In contrast, skip-filtering connections are shown to assist the DAE model in learning filtering operators that exploit richer inter-frequency structure.