 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Semi-supervised Expectation Maximization
Nov 01, 2022The Expectation Maximization (EM) algorithm is widely used as an iterative modification to maximum likelihood estimation when the data is incomplete. We focus on a semi-supervised case to learn the model from labeled and unlabeled samples. Existing work in the semi-supervised case has focused mainly on performance rather than convergence guarantee, however we focus on the contribution of the labeled samples to the convergence rate. The analysis clearly demonstrates how the labeled samples improve the convergence rate for the exponential family mixture model. In this case, we assume that the population EM (EM with unlimited data) is initialized within the neighborhood of global convergence for the population EM that consists solely of samples that have not been labeled. The analysis for the labeled samples provides a comprehensive description of the convergence rate for the Gaussian mixture model. In addition, we extend the findings for labeled samples and offer an alternative proof for the population EM's convergence rate with unlabeled samples for the symmetric mixture of two Gaussians.
Common Information Components Analysis
Feb 28, 2020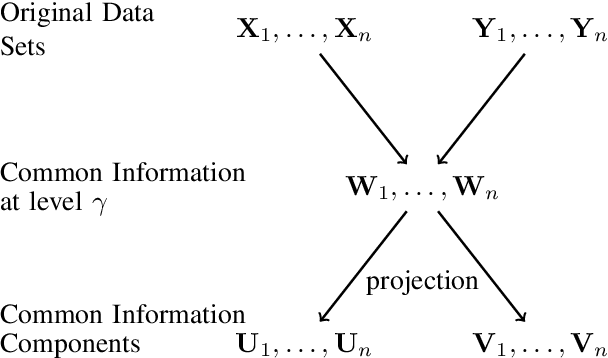
We give an information-theoretic interpretation of Canonical Correlation Analysis (CCA) via (relaxed) Wyner's common information. CCA permits to extract from two high-dimensional data sets low-dimensional descriptions (features) that capture the commonalities between the data sets, using a framework of correlations and linear transforms. Our interpretation first extracts the common information up to a pre-selected resolution level, and then projects this back onto each of the data sets. In the case of Gaussian statistics, this procedure precisely reduces to CCA, where the resolution level specifies the number of CCA components that are extracted. This also suggests a novel algorithm, Common Information Components Analysis (CICA), with several desirable features, including a natural extension to beyond just two data sets.
Supply-Power-Constrained Cable Capacity Maximization Using Deep Neural Networks
Oct 02, 2019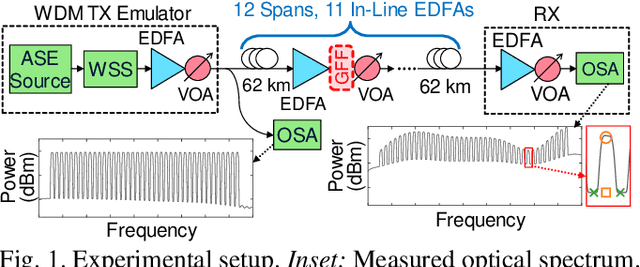
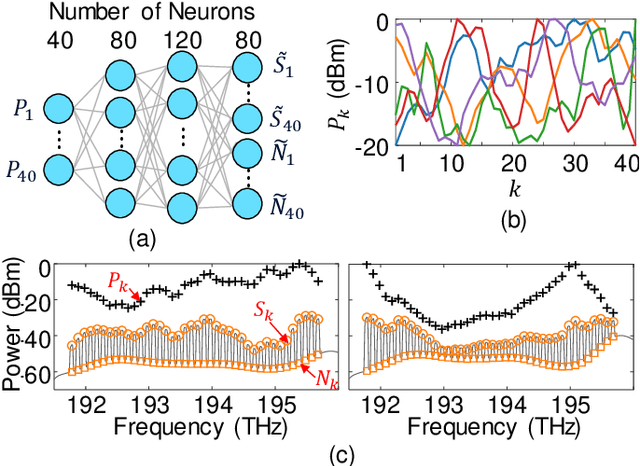
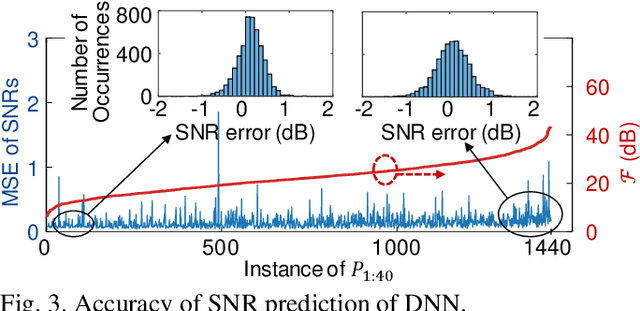
We experimentally achieve a 19% capacity gain per Watt of electrical supply power in a 12-span link by eliminating gain flattening filters and optimizing launch powers using machine learning by deep neural networks in a massively parallel fiber context.