 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Control Latent Representations for Few-Shot Learning of Named Entities
Nov 19, 2019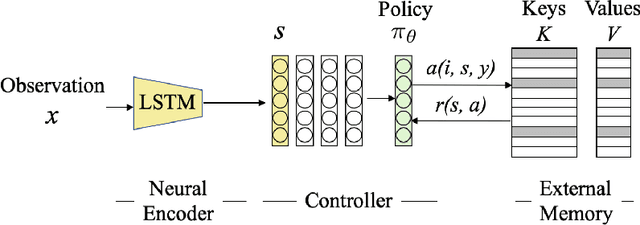

Humans excel in continuously learning with small data without forgetting how to solve old problems. However, neural networks require large datasets to compute latent representations across different tasks while minimizing a loss function. For example, a natural language understanding (NLU) system will often deal with emerging entities during its deployment as interactions with users in realistic scenarios will generate new and infrequent names, events, and locations. Here, we address this scenario by introducing an RL trainable controller that disentangles the representation learning of a neural encoder from its memory management role. Our proposed solution is straightforward and simple: we train a controller to execute an optimal sequence of reading and writing operations on an external memory with the goal of leveraging diverse activations from the past and provide accurate predictions. Our approach is named Learning to Control (LTC) and allows few-shot learning with two degrees of memory plasticity. We experimentally show that our system obtains accurate results for few-shot learning of entity recognition in the Stanford Task-Oriented Dialogue dataset.
Aging Memories Generate More Fluent Dialogue Responses with Memory Networks
Nov 19, 2019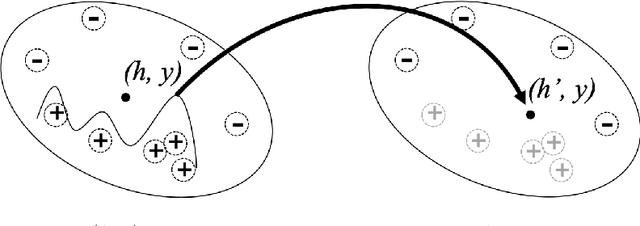

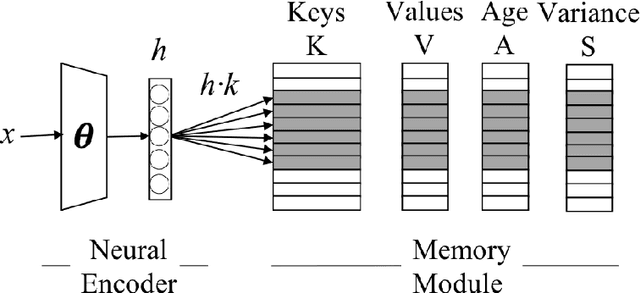
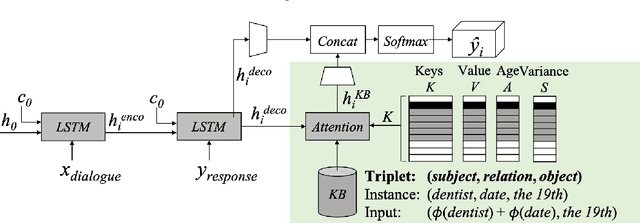
The integration of a Knowledge Base (KB) into a neural dialogue agent is one of the key challenges in Conversational AI. Memory networks has proven to be effective to encode KB information into an external memory to thus generate more fluent and informed responses. Unfortunately, such memory becomes full of latent representations during training, so the most common strategy is to overwrite old memory entries randomly. In this paper, we question this approach and provide experimental evidence showing that conventional memory networks generate many redundant latent vectors resulting in overfitting and the need for larger memories. We introduce memory dropout as an automatic technique that encourages diversity in the latent space by 1) Aging redundant memories to increase their probability of being overwritten during training 2) Sampling new memories that summarize the knowledge acquired by redundant memories. This technique allows us to incorporate Knowledge Bases to achieve state-of-the-art dialogue generation in the Stanford Multi-Turn Dialogue dataset. Considering the same architecture, its use provides an improvement of +2.2 BLEU points for the automatic generation of responses and an increase of +8.1% in the recognition of named entities.
Telephonetic: Making Neural Language Models Robust to ASR and Semantic Noise
Jun 13, 2019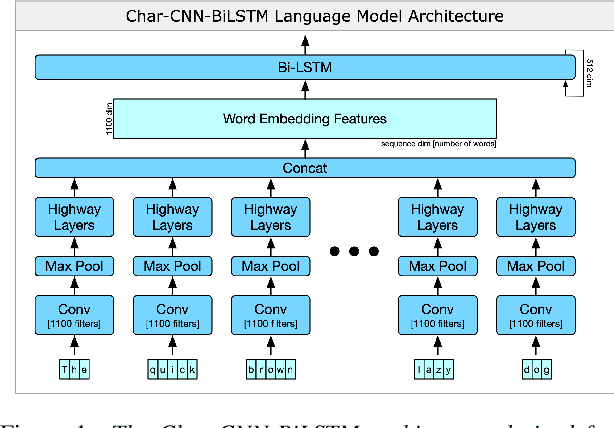
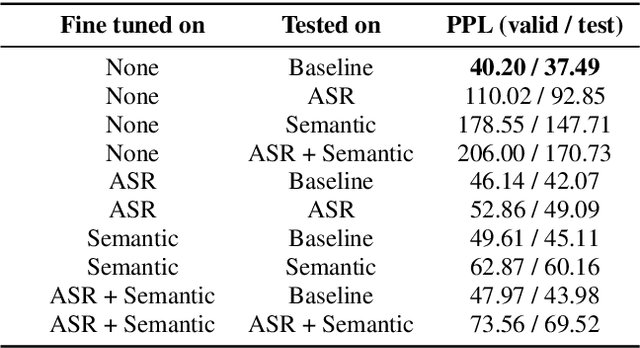

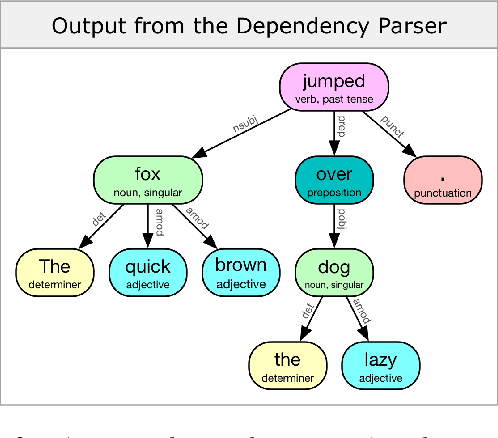
Speech processing systems rely on robust feature extraction to handle phonetic and semantic variations found in natural language. While techniques exist for desensitizing features to common noise patterns produced by Speech-to-Text (STT) and Text-to-Speech (TTS) systems, the question remains how to best leverage state-of-the-art language models (which capture rich semantic features, but are trained on only written text) on inputs with ASR errors. In this paper, we present Telephonetic, a data augmentation framework that helps robustify language model features to ASR corrupted inputs. To capture phonetic alterations, we employ a character-level language model trained using probabilistic masking. Phonetic augmentations are generated in two stages: a TTS encoder (Tacotron 2, WaveGlow) and a STT decoder (DeepSpeech). Similarly, semantic perturbations are produced by sampling from nearby words in an embedding space, which is computed using the BERT language model. Words are selected for augmentation according to a hierarchical grammar sampling strategy. Telephonetic is evaluated on the Penn Treebank (PTB) corpus, and demonstrates its effectiveness as a bootstrapping technique for transferring neural language models to the speech domain. Notably, our language model achieves a test perplexity of 37.49 on PTB, which to our knowledge is state-of-the-art among models trained only on PTB.