 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTelephonetic: Making Neural Language Models Robust to ASR and Semantic Noise
Paper and Code
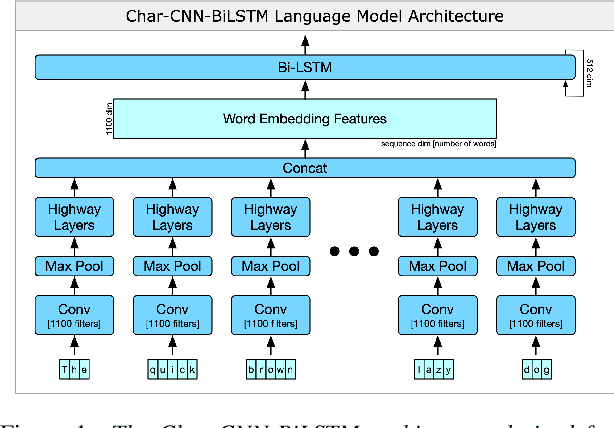
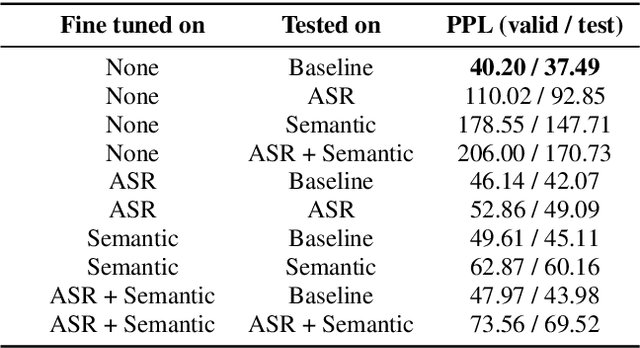

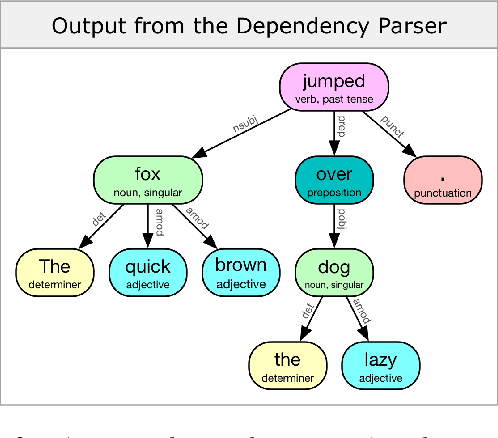
Speech processing systems rely on robust feature extraction to handle phonetic and semantic variations found in natural language. While techniques exist for desensitizing features to common noise patterns produced by Speech-to-Text (STT) and Text-to-Speech (TTS) systems, the question remains how to best leverage state-of-the-art language models (which capture rich semantic features, but are trained on only written text) on inputs with ASR errors. In this paper, we present Telephonetic, a data augmentation framework that helps robustify language model features to ASR corrupted inputs. To capture phonetic alterations, we employ a character-level language model trained using probabilistic masking. Phonetic augmentations are generated in two stages: a TTS encoder (Tacotron 2, WaveGlow) and a STT decoder (DeepSpeech). Similarly, semantic perturbations are produced by sampling from nearby words in an embedding space, which is computed using the BERT language model. Words are selected for augmentation according to a hierarchical grammar sampling strategy. Telephonetic is evaluated on the Penn Treebank (PTB) corpus, and demonstrates its effectiveness as a bootstrapping technique for transferring neural language models to the speech domain. Notably, our language model achieves a test perplexity of 37.49 on PTB, which to our knowledge is state-of-the-art among models trained only on PTB.